

人類沒有足夠的高品質語料給AI學了,2026年就用盡,網友:大型人類文本生成計畫啟動!

AI胃口太大,人類的語料數據已經不夠吃了。
來自Epoch團隊的一篇新論文表明,AI不出5年就會把所有高品質語料用光。

要知道,這可是把人類語言資料成長率考慮在內預測出的結果,換而言之,這幾年人類新寫的論文、新編的程式碼,就算全都餵給AI也不夠。
照這麼發展下去,依賴高品質資料提升水準的語言大模型,很快就要迎來瓶頸。
已經有網友坐不住了:
這太荒謬了。人類無需閱讀網路所有內容,就能高效訓練自己。
我們需要更好的模型,而不是更多的數據。
還有網友調侃,都這樣瞭不如讓AI吃自己吐的東西:
可以把AI自己生成的文本當成低品質數據餵給AI。

讓我們來看看,人類剩餘的資料還有多少?
文字和圖像資料「存貨」如何?
論文主要針對文字和圖像兩類資料進行了預測。
首先是文字資料。
數據的品質通常有好有壞,作者們根據現有大模型採用的資料類型、以及其他數據,將可用文字資料分成了低品質和高品質兩部分。
高品質語料,參考了Pile、PaLM和MassiveText等大型語言模型所使用的訓練資料集,包括維基百科、新聞、GitHub上的程式碼、出版書籍等。
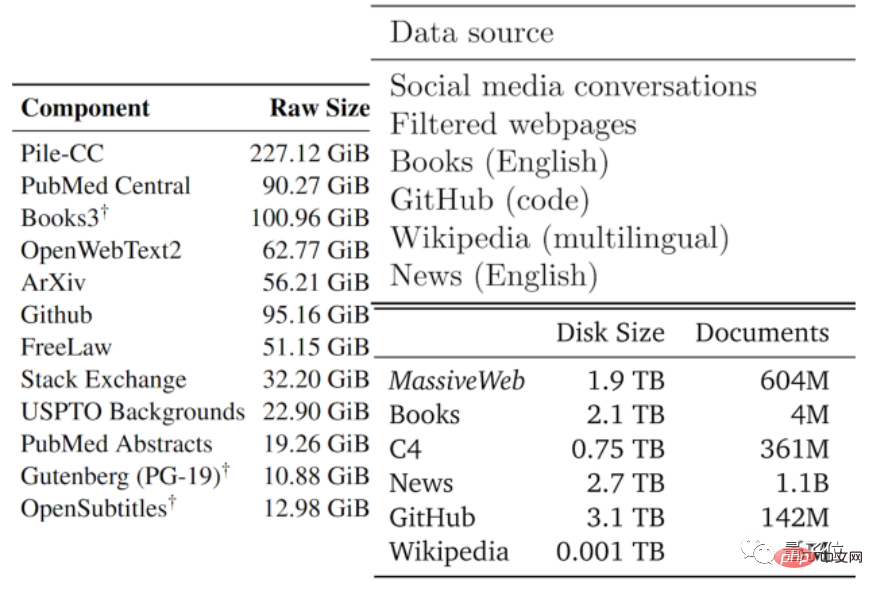
低品質語料,則來自Reddit等社群媒體上的推文、以及非官方創作的同人小說(fanfic)等。
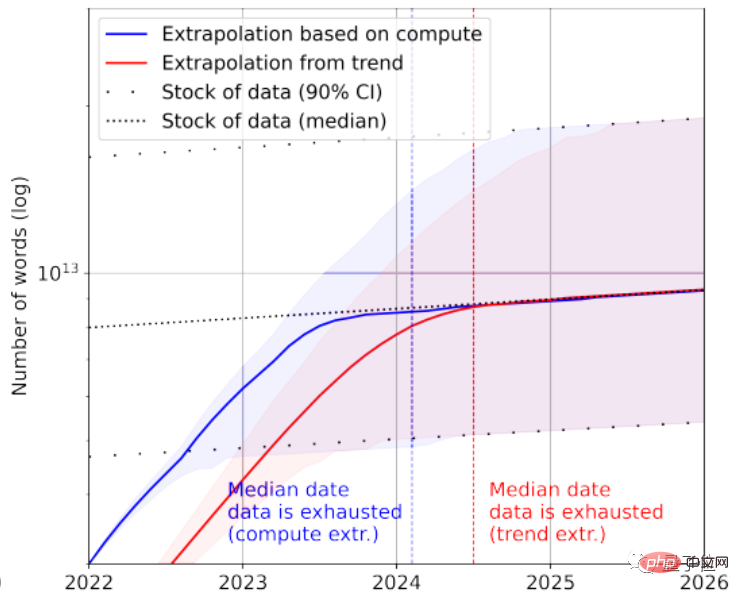
根據統計,高品質語言資料存量只剩下約4.6×10^12~1.7×10^13個單詞,相較於目前最大的文字資料集大了不到一個數量級。
結合成長率,論文預測高品質文本資料會在2023~2027年間被AI耗盡,預估節點在2026年左右。
看起來實在有點快…
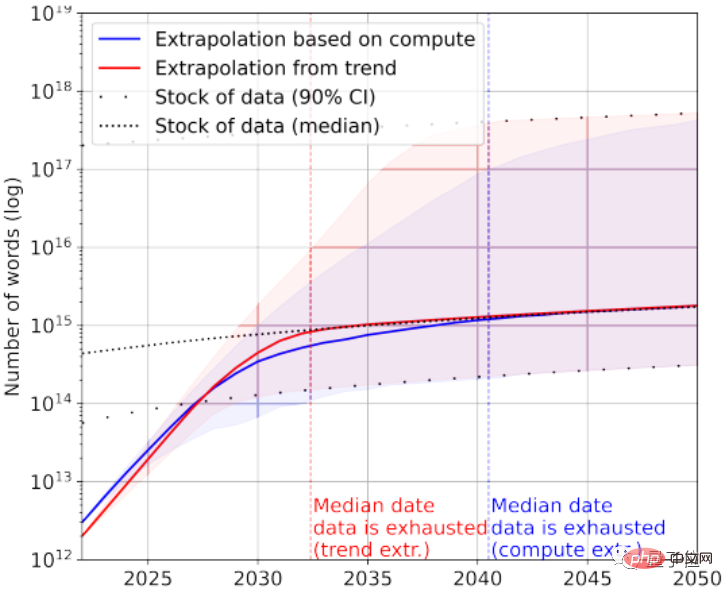
當然,可以再加上低品質文字資料來救急。根據統計,目前文字資料整體存量還剩下7×10^13~7×10^16個單詞,比最大的資料集大1.5~4.5個數量級。
如果對資料品質要求不高,那麼AI會在2030年~2050年之間才用完所有文字資料。
再看看圖像數據,這裡論文沒有區分圖像品質。
目前最大的影像資料集擁有3×10^9張圖片。
根據統計,目前圖片總量約有8.11×10^12~2.3×10^13張,比最大的影像資料集大出3~4個數量級。
論文預測AI會在2030~2070年間用完這些圖片。
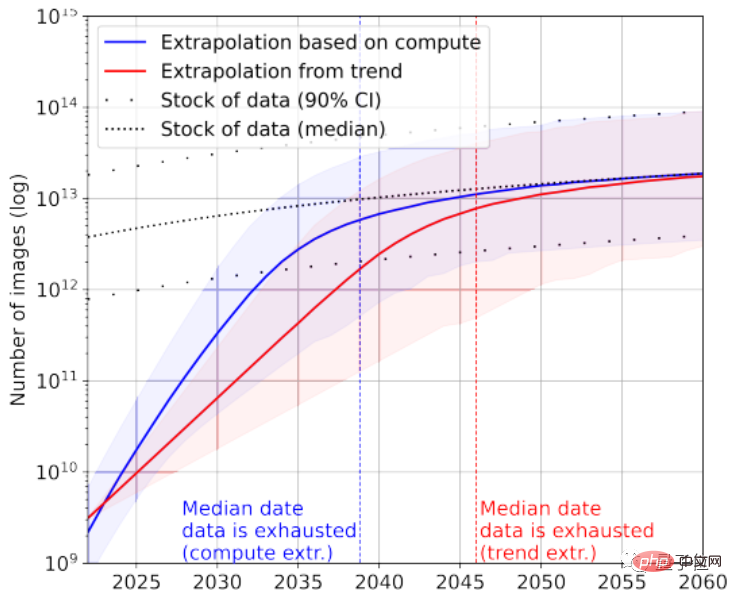
顯然,大語言模型比圖像模型面臨更緊張的「缺少資料」情況。
那麼這結論是如何得出的呢?
計算網民日均發文量得出
論文從兩個角度,分別對文字影像資料產生效率、以及訓練資料集成長情況進行了分析。
值得注意的是,論文統計的不都是標註數據,考慮到無監督學習比較火熱,把未標註數據也算進去了。
以文字資料為例,大部分資料會從社群平台、部落格和論壇產生。
為了估計文字資料產生速度,有三個因素需要考慮,即總人口、網路普及率和網路使用者平均產生資料量。
例如,這是根據歷史人口資料和網路使用者數量,估計得到的未來人口和網路使用者成長趨勢:
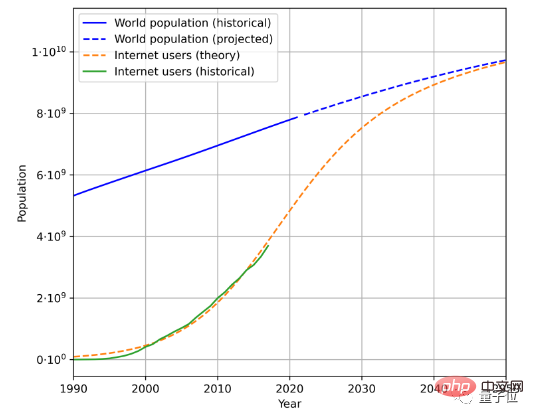
再結合使用者產生的平均資料量,就能計算出生成資料的速率。 (由於地理和時間變化複雜,論文簡化了用戶平均生成數據量計算方法)
根據此方法,計算得出語言數據增長率在7%左右,然而這一增長率會隨著時間延長逐漸下降。
預計到2100年,我們的語言資料成長率會降低到1%。
同樣類似的方法分析影像數據,目前成長率在8%左右,然而到2100年影像數據成長率同樣會放緩至1%左右。
論文認為,如果資料成長率沒有大幅提升、或出現新的資料來源,無論是靠高品質資料訓練的圖像或文字大模型,都可能在某個階段迎來瓶頸期。
對此有網友調侃,未來或許會有像科幻故事情節一樣的事情發生:
人類為了訓練AI,啟動大型文本生成項目,大家為了AI拼命寫東西。
他稱之為一種「對AI的教育」:
我們每年給AI14萬到260萬單詞量的文字數據,聽起來似乎比人類當電池更酷?
你覺得呢?
論文網址:https://arxiv.org/abs/2211.04325
參考連結:https://twitter.com/emollick/status/1605756428941246466
#以上是人類沒有足夠的高品質語料給AI學了,2026年就用盡,網友:大型人類文本生成計畫啟動!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 AI攻克費馬大定理?數學家放棄5年職業生涯,將100頁證明變代碼
Apr 09, 2024 pm 03:20 PM
AI攻克費馬大定理?數學家放棄5年職業生涯,將100頁證明變代碼
Apr 09, 2024 pm 03:20 PM
費馬大定理,即將被AI攻克?而整件事最有意義的地方在於,AI即將解決的費馬大定理,正是為了證明AI無用。曾經,數學屬於純粹的人類智力王國;如今,這片疆土正被先進的演算法所破解,所踐踏。圖片費馬大定理,是一個「臭名昭著」的謎題,在幾個世紀以來,一直困擾著數學家。它在1993年被證明,而現在,數學家們有一個偉大計畫:用電腦把證明過程重現。他們希望在這個版本的證明中,如果有任何邏輯上的錯誤,都可以由電腦檢查出來。專案網址:https://github.com/riccardobrasca/flt
 分享PyCharm專案打包的簡易方法
Dec 30, 2023 am 09:34 AM
分享PyCharm專案打包的簡易方法
Dec 30, 2023 am 09:34 AM
簡單易懂的PyCharm專案打包方法分享隨著Python的流行,越來越多的開發者使用PyCharm作為Python開發的主要工具。 PyCharm是功能強大的整合開發環境,它提供了許多方便的功能來幫助我們提高開發效率。其中一個重要的功能就是專案的打包。本文將介紹如何在PyCharm中簡單易懂地打包項目,並提供具體的程式碼範例。為什麼要打包專案?在Python開發
 用於時間序列機率預測的分位數迴歸
May 07, 2024 pm 05:04 PM
用於時間序列機率預測的分位數迴歸
May 07, 2024 pm 05:04 PM
不要改變原內容的意思,微調內容,重寫內容,不要續寫。 「分位數迴歸滿足此需求,提供具有量化機會的預測區間。它是一種統計技術,用於模擬預測變數與反應變數之間的關係,特別是當反應變數的條件分佈命令人感興趣時。 ⼀組迴歸變數X與被解釋變數Y的分位數之間線性關係的建模⽅法。現有的迴歸模型其實是研究被解釋變數與解釋變數之間關係的一種方法。他們關註解釋變數與被解釋變數之間的關
 深入了解PyCharm:快速刪除項目的方法
Feb 26, 2024 pm 04:21 PM
深入了解PyCharm:快速刪除項目的方法
Feb 26, 2024 pm 04:21 PM
標題:深入了解PyCharm:刪除專案的高效方式近年來,Python作為一種強大而靈活的程式語言,受到越來越多開發者的青睞。在Python專案的開發中,選擇一個高效的整合開發環境至關重要。 PyCharm作為一款功能強大的整合開發環境,為Python開發者提供了許多便利的功能和工具,其中包括快速、有效率地刪除專案目錄。以下將著重介紹如何使用PyCharm中的刪除
 PyCharm實用技巧:將項目轉換為可執行EXE文件
Feb 23, 2024 am 09:33 AM
PyCharm實用技巧:將項目轉換為可執行EXE文件
Feb 23, 2024 am 09:33 AM
PyCharm是一款功能強大的Python整合開發環境,提供了豐富的開發工具和環境配置,讓開發者更有效率地編寫和除錯程式碼。在使用PyCharm進行Python專案開發的過程中,有時候我們需要將專案打包成可執行的EXE文件,以便在沒有安裝Python環境的電腦上執行。本文將介紹如何使用PyCharm將專案轉換為可執行的EXE文件,同時給出具體的程式碼範例。首
 SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
原文標題:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving論文連結:https://arxiv.org/pdf/2402.02519.pdf程式碼連結:https://github.com/HKUST-Aerial-Robotics/SIMPLobotics單位論文想法:本文提出了一種用於自動駕駛車輛的簡單且有效率的運動預測基線(SIMPL)。與傳統的以代理為中心(agent-cent
 如何使用MySQL資料庫進行預測和預測分析?
Jul 12, 2023 pm 08:43 PM
如何使用MySQL資料庫進行預測和預測分析?
Jul 12, 2023 pm 08:43 PM
如何使用MySQL資料庫進行預測和預測分析?概述:預測和預測分析在數據分析中扮演重要角色。 MySQL作為一種廣泛使用的關聯式資料庫管理系統,也可以用於預測和預測分析任務。本文將介紹如何使用MySQL進行預測和預測分析,並提供相關的程式碼範例。資料準備:首先,我們需要準備相關的資料。假設我們要進行銷售預測,我們需要具有銷售資料的表格。在MySQL中,我們可以使用
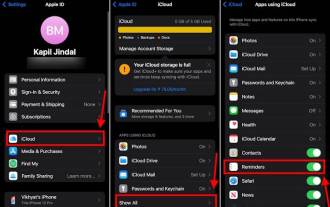 製作 iPhone 上 iOS 17 提醒應用程式中的購物清單的方法
Sep 21, 2023 pm 06:41 PM
製作 iPhone 上 iOS 17 提醒應用程式中的購物清單的方法
Sep 21, 2023 pm 06:41 PM
如何在iOS17中的iPhone上製作GroceryList在「提醒事項」應用程式中建立GroceryList非常簡單。你只需添加一個列表,然後用你的項目填充它。該應用程式會自動將您的商品分類,您甚至可以與您的伴侶或扁平夥伴合作,列出您需要從商店購買的東西。以下是執行此操作的完整步驟:步驟1:開啟iCloud提醒事項聽起來很奇怪,蘋果表示您需要啟用來自iCloud的提醒才能在iOS17上建立GroceryList。以下是它的步驟:前往iPhone上的「設定」應用,然後點擊[您的姓名]。接下來,選擇i
