

MySQL索引建立原則的範例分析

一、適合建立索引
1、欄位的數值有唯一性限制
根據Alibaba規範,指明在業務上具有唯一特性的字段,即使是組合字段,也必須建造唯一索引。

例如,學生表中的學號時具有唯一性的字段,為該字段建立唯一性索引可以快速查詢出某個學生的信息,如果使用姓名的話,可能存在同名的情況,從而降低查詢速度。
2、經常作為Where查詢條件的欄位
某個欄位在Select語句的Where條件中常被使用到,那麼就需要為這個欄位建立索引,尤其實在資料量大的情況下,建立普通索引就可以大幅提升查詢效率。
例如測試表student_info有100萬數據,假設查詢student_id=112322的用戶信息,如果沒有對student_id字段創建索引,查詢結果如下:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
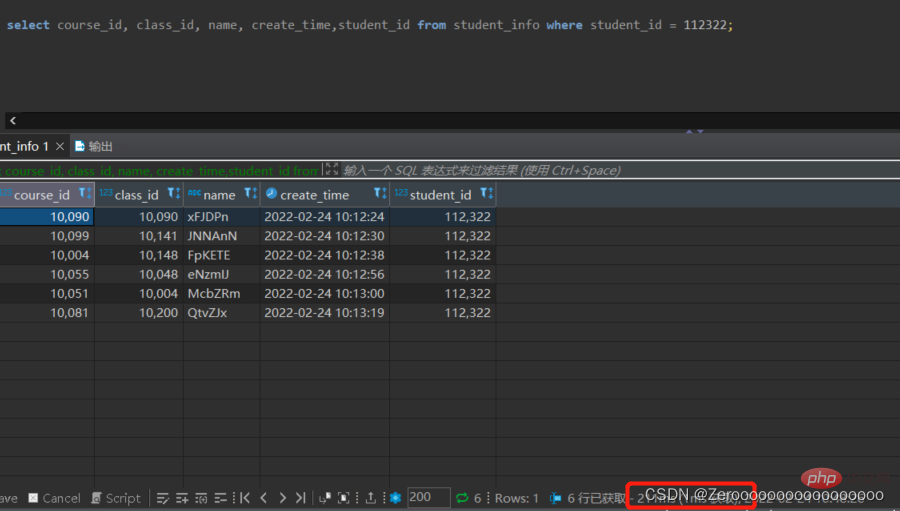
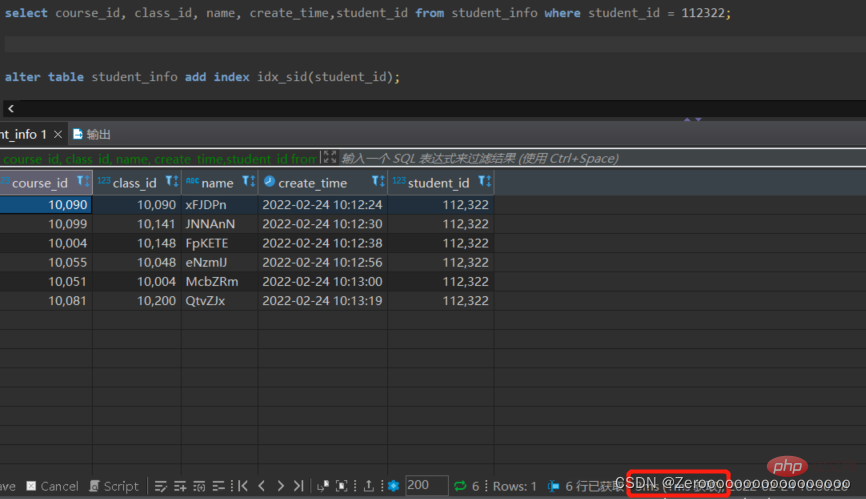
#為student_id建立索引後,查詢結果如下:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
3、經常Group by和Order by的列
索引就是讓資料依照某種順序進行儲存或檢索,因此當使用Group by對資料進行分組查詢或使用Order by對資料進行排序的時候,就需要對分組或排序的欄位進行索引。如果待排序的欄位有多個,則可以在這些欄位上建立組合索引。
例如,依照student_id將學生選秀的課程分組,顯示不同的student_id和課程的數量,顯示100個。如果沒有對student_id建立索引,查詢結果如下:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
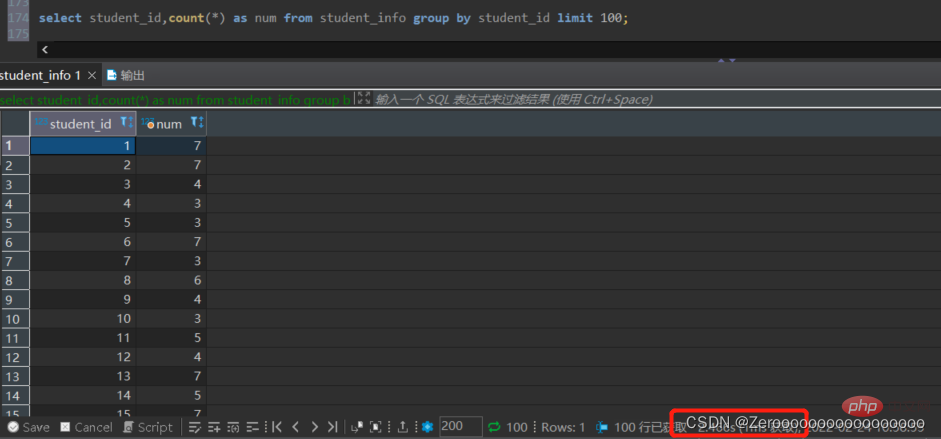
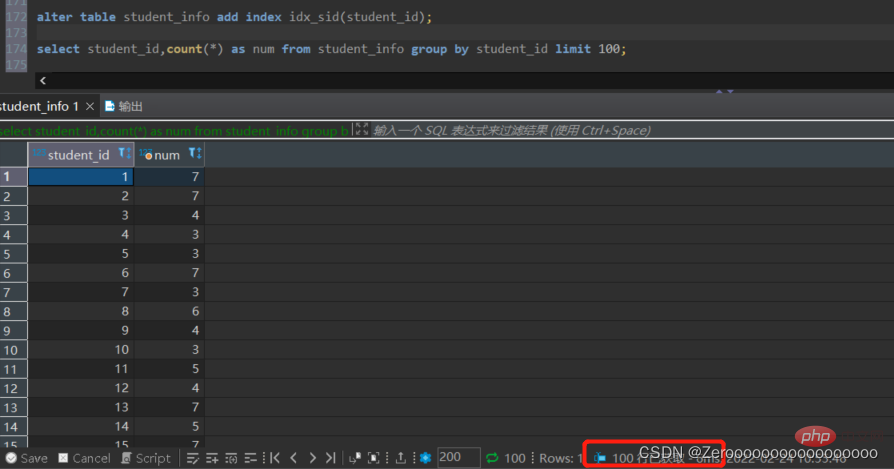
#為student_id建立索引後,查詢結果如下:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
#對於既有group by又有order by的查詢語句,建議最好建立聯合索引,並且將group by中的字段放到order by字段的前邊,滿足‘最左前綴匹配原則’ ,這樣索引的使用率就會高,自然查詢的效率也會高;同時8.0之後的版本支援降序索引,如果order by之後的欄位時降序的,可以考慮直接建立降序索引,也會提高查詢效率。
4、Update、Delete的where條件列
對資料按照某個條件進行查詢後再進行Update或Delete的操作,如果對Where欄位建立了索引,就能答覆提升效率。原因是因為需要先根據Where條件列檢索出來這條記錄,然後再對他進行更新或刪除。如果進行更新的時候,更新的字段是非索引字段,提升效率會更明顯,這是因為費索引字段更新不需要對所以進行維護。
例如對student_info表中的name欄位為sdfasdfas123123的資料修改student_id為110119,在沒有對name欄位建立索引的情況下,執行情況如下:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
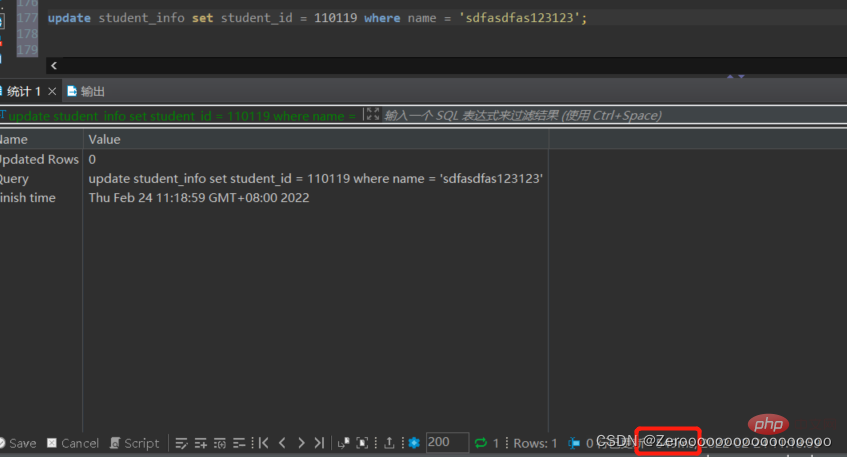
#新增索引後,執行情況如下:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
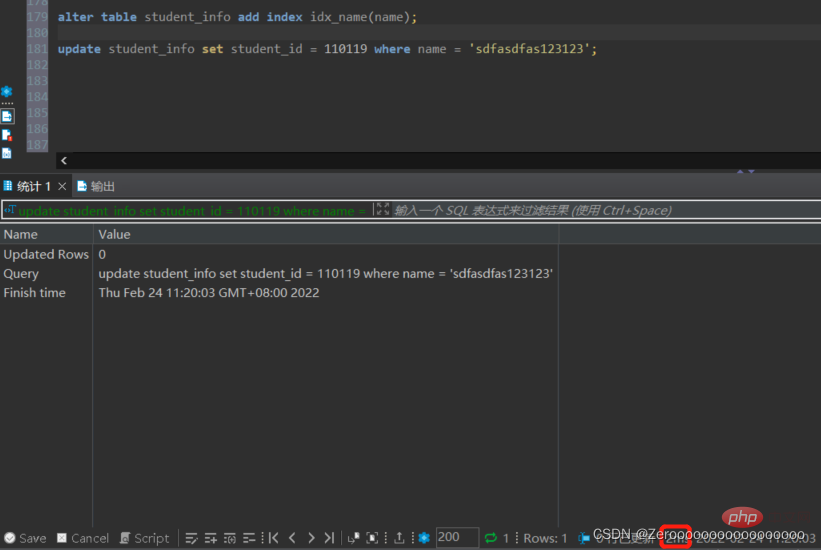
5、Distinct欄位需要建立索引
有時候需要對某個欄位進行去重,使用Distinct,那麼對這個建立索引也會提升查詢效率。
例如查詢課程表中不同student_id都有哪些,如果沒有為student_id建立索引,執行情況如下:
select distinct(student_id) from student_id;#花费2ms
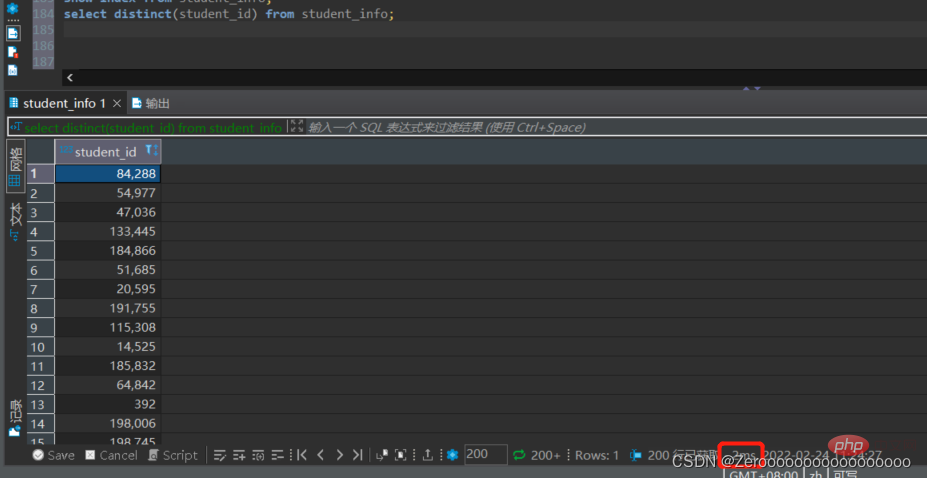
建立索引後,執行情況如下:
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms
6、多表Join連接操作時,建立索引註意事項
#首先,連接表的資料量盡量不超過3張,因為每增加一張表就相當於增加了一次嵌套的循環,數量級成長非常快,嚴重影響查詢效率。其次,對Where條件建立索引,因為Where才是對資料條件的過濾,如果再資料量非常大的情況下,沒有Where條件過濾時非常可怕的,最後,對於連接的欄位建立索引,並且改欄位再多張表中類型必須一致。

例如,只對student_id建立索引,查詢結果如下:
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
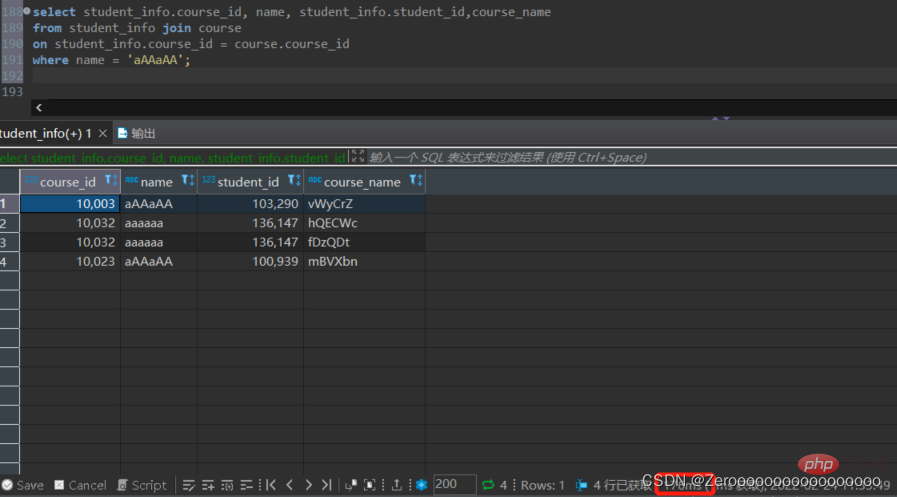
給name欄位建立索引後,查詢結果如下:
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9、不要定義冗餘或重複的索引
以上是MySQL索引建立原則的範例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 MySQL:初學者的數據管理易用性
Apr 09, 2025 am 12:07 AM
MySQL:初學者的數據管理易用性
Apr 09, 2025 am 12:07 AM
MySQL適合初學者使用,因為它安裝簡單、功能強大且易於管理數據。 1.安裝和配置簡單,適用於多種操作系統。 2.支持基本操作如創建數據庫和表、插入、查詢、更新和刪除數據。 3.提供高級功能如JOIN操作和子查詢。 4.可以通過索引、查詢優化和分錶分區來提升性能。 5.支持備份、恢復和安全措施,確保數據的安全和一致性。
 忘記數據庫密碼,能在Navicat中找回嗎?
Apr 08, 2025 pm 09:51 PM
忘記數據庫密碼,能在Navicat中找回嗎?
Apr 08, 2025 pm 09:51 PM
Navicat本身不存儲數據庫密碼,只能找回加密後的密碼。解決辦法:1. 檢查密碼管理器;2. 檢查Navicat的“記住密碼”功能;3. 重置數據庫密碼;4. 聯繫數據庫管理員。
 navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
navicat premium怎麼創建
Apr 09, 2025 am 07:09 AM
使用 Navicat Premium 創建數據庫:連接到數據庫服務器並輸入連接參數。右鍵單擊服務器並選擇“創建數據庫”。輸入新數據庫的名稱和指定字符集和排序規則。連接到新數據庫並在“對象瀏覽器”中創建表。右鍵單擊表並選擇“插入數據”來插入數據。
 mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
MySQL是一個開源的關係型數據庫管理系統。 1)創建數據庫和表:使用CREATEDATABASE和CREATETABLE命令。 2)基本操作:INSERT、UPDATE、DELETE和SELECT。 3)高級操作:JOIN、子查詢和事務處理。 4)調試技巧:檢查語法、數據類型和權限。 5)優化建議:使用索引、避免SELECT*和使用事務。
 MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:開發人員的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是開發者必備技能。 1.MySQL是開源的關係型數據庫管理系統,SQL是用於管理和操作數據庫的標準語言。 2.MySQL通過高效的數據存儲和檢索功能支持多種存儲引擎,SQL通過簡單語句完成複雜數據操作。 3.使用示例包括基本查詢和高級查詢,如按條件過濾和排序。 4.常見錯誤包括語法錯誤和性能問題,可通過檢查SQL語句和使用EXPLAIN命令優化。 5.性能優化技巧包括使用索引、避免全表掃描、優化JOIN操作和提升代碼可讀性。
 navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
navicat怎麼新建連接mysql
Apr 09, 2025 am 07:21 AM
可在 Navicat 中通過以下步驟新建 MySQL 連接:打開應用程序並選擇“新建連接”(Ctrl N)。選擇“MySQL”作為連接類型。輸入主機名/IP 地址、端口、用戶名和密碼。 (可選)配置高級選項。保存連接並輸入連接名稱。
 phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎麼打開
Apr 10, 2025 pm 10:51 PM
可以通過以下步驟打開 phpMyAdmin:1. 登錄網站控制面板;2. 找到並點擊 phpMyAdmin 圖標;3. 輸入 MySQL 憑據;4. 點擊 "登錄"。
 navicat如何執行sql
Apr 08, 2025 pm 11:42 PM
navicat如何執行sql
Apr 08, 2025 pm 11:42 PM
在 Navicat 中執行 SQL 的步驟:連接到數據庫。創建 SQL 編輯器窗口。編寫 SQL 查詢或腳本。單擊“運行”按鈕執行查詢或腳本。查看結果(如果執行查詢的話)。
