

怎麼為MySQL建立高效能索引

1 索引基礎
1.1 索引作用
在MySQL中,在尋找資料時先在索引中找到對應的值,然後根據符合的索引記錄找到對應的資料行,如果要執行下面查詢語句:
SELECT * FROM USER WHERE uid = 5;
如果在uid在建有索引,則MySQL會使用該索引先找到uid為5的行,也就是說MySQL先在索引上按值進行查找,然後再傳回所有包含該值的資料行。
1.2 MySQL索引常用資料結構
MySQL索引是在儲存引擎層面實現的,不是在伺服器實現的。所以,沒有統一的索引標準:不同儲存引擎的索引運作方式不一樣。
1.2.1 B-Tree
大多數的MySQL引擎都支援這種索引B-Tree,即時多個儲存引擎支援同一種類型的索引,其底層實作也可能不同。例如InnoDB使用的是B Tree。
儲存引擎以不同的方式實現B-Tree,效能也各有不同,各有優勢。如,MyISAM使用前綴壓縮技術是的索引更小,當InnoDB則按照原始資料格式進行存儲,MyISAMy索引透過資料的物理位置引用被索引的行,而InnoDB根據元件應用被索引的行。
B-Tree所有值都是順序儲存的,並且每一個葉子頁到根的距離都相同。如下圖大致反應了InnoDB索引是如何運作的,MyISAM所使用的結構有所不同。但基本實作是類似的。
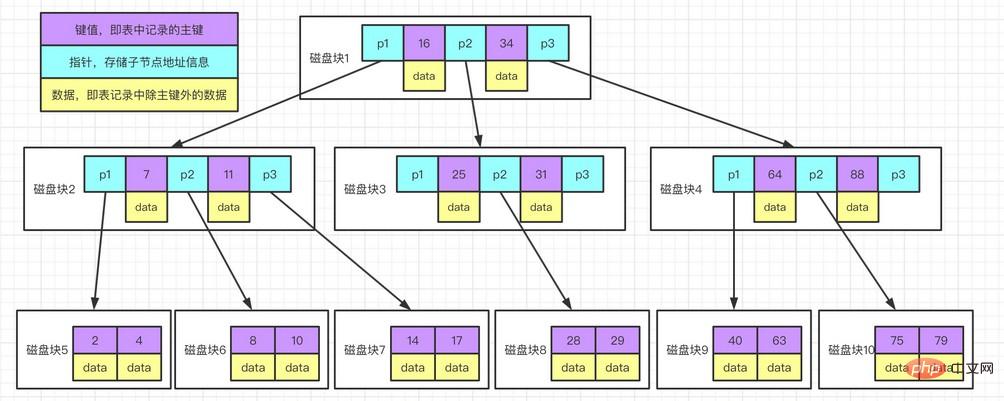
實例圖說明:
每個節點佔用一個磁碟區塊,一個節點上有兩個升序排序的關鍵字和三個指向子樹根節點的指針,指針儲存的是子節點所在磁碟塊的位址。兩個關鍵字分割成的三個範圍域對應三個指標指向的子樹的資料的範圍域。以根節點為例,關鍵字為16 和34,P1 指標指向的子樹的資料範圍為小於16,P2 指標指向的子樹的資料範圍為16~34,P3 指標指向的子樹的資料範圍為大於34。尋找關鍵字過程:
根據根節點找到磁碟區塊 1,讀入記憶體。 【磁碟 I/O 操作第 1 次】
比較關鍵字 28 在區間(16,34),找出磁碟區塊 1 的指標 P2。
根據 P2 指標找到磁碟區塊 3,讀入記憶體。 【磁碟 I/O 操作第 2 次】
比較關鍵字 28 在區間(25,31),找出磁碟區塊 3 的指標 P2。
根據 P2 指標找到磁碟區塊 8,讀入記憶體。 【磁碟 I/O 操作第 3 次】
在磁碟區塊 8 中的關鍵字清單中找到關鍵字 28。
缺點:
#每個節點都有key,同時也包含data,而每頁儲存空間是有限的,如果data比較大的話會導致每個節點儲存的key數量變小;
#當儲存的資料量很大的時候會導致深度較大,增大查詢時磁碟io次數,進而影響查詢效能。
1.2.2 B Tree索引
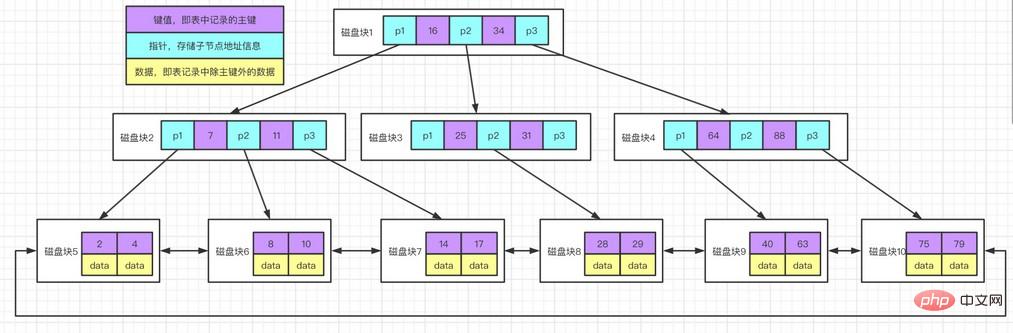
B 樹是對B樹的變體。與B樹區別:B 樹只在葉節點儲存數據,非葉節點只儲存key值及指標。
在B 樹上有兩個指針,一個指向根葉子節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即資料節點)之間是一種鍊式環結構,因此可以對B 樹進行兩種查找運算:一種是對於組件的範圍查找,另一種是從根節點開始,進行隨機查找。
B*樹與B 數類似,差異在於B*數非葉子節點之間也有鍊式環結構。
1.2.3 Hash索引
哈希索引基於哈希表實現,只有精準匹配索引所有列的查詢才有效。對於每一行數據,儲存引擎都會對所有的索引列計算一個哈希碼(hash code),哈希碼是一個較小的值,並且不同鍵值的行計算出來的哈希碼也不一樣。哈希索引將所有的雜湊碼儲存在索引中,同時在雜湊表中保存指向每個資料行的指標。
在MySQL中只有Memory預設索引類型就是使用的雜湊索引,memory也支援B-Tree索引。同時,Memory引擎支援非唯一雜湊索引,如果多個列的雜湊值相同,索引會以鍊錶的方式存放多個指標相同一個雜湊條目中。類似HashMap。
優點:
索引本身只需要儲存對應的雜湊值,所以索引的結構十分緊湊,哈希所以找到的速度非常快。
缺點:
利用hash儲存的話需要將所有的資料檔案加入內存,比較耗費記憶體空間;
哈希索引資料並不是按順序儲存的,所以無法用於排序;
如果所有的查詢都是等值查詢,那麼hash確實很快,但是在企業或實際工作環境中範圍查找的資料更多,而不是等值查詢,因此hash就不太適合了;
如果哈希衝突很多的話,索引維護操作的代價也會很高,這也是HashMap後期透過增加紅黑樹解決Hash衝突的問題;
2 高效能索引策略
2.1 叢集索引與非叢集索引
叢集索引
不是單獨的索引類型,而是一種資料儲存方式,在InnoDB儲存引擎中聚集索引實際在同一個結構中保存了鍵值和資料行。當表中有叢集索引時,它的資料行實際上存放在索引的葉子頁中。因為無法同時把資料行存放在不同的地方,所以一個表格中只能有一個聚集索引(索引覆蓋可以模擬出多個叢集索引的情況)。
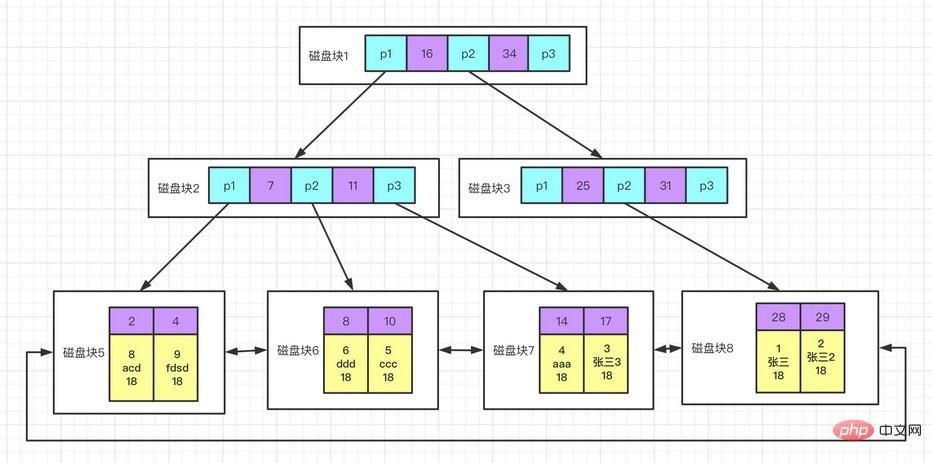
叢集索引優點:
可以把相關資料存在一起;資料存取更快,因為索引和資料保存在同一個樹中;使用覆蓋索引掃描的查詢可以直接使用頁節點中的主鍵值;
缺點:
叢集資料最大限度地提高了IO密集型應用程式的效能,如果資料全部在內存,那麼聚簇索引就沒有什麼優勢;插入速度嚴重依賴於插入順序,按照主鍵的順序插入是最快的方式;更新聚簇索引列的代價很高,因為會強制將每個被更新的行移動到新的位置;基於聚簇索引的表在插入新行,或者主鍵被更新導致需要移動行的時候,可能面臨頁分裂的問題;聚簇索引可能導致全表掃描變慢,尤其是行比較稀疏,或由於頁分裂導致資料儲存不連續的時候;
非聚集索引
資料檔案跟索引檔案分開存放
2.2 前綴索引
#有時候需要索引很長的字串,這會讓索引變的大且慢,通常情況下可以使用某個列開始的部分字串,這樣大大的節約索引空間,從而提高索引效率,但這會降低索引的選擇性,索引的選擇性是指:不重複的索引值(也稱為基數cardinality)和資料表記錄總數的比值,範圍從1/#T到1之間。索引的選擇性越高則查詢效率越高,因為選擇性較高的索引可以讓mysql在尋找的時候過濾掉更多的行。
一般情況下某個列前綴的選擇性也是足夠高的,足以滿足查詢的性能,但是對應BLOB,TEXT,VARCHAR類型的列,必須要使用前綴索引,因為mysql不允許索引這些列的完整長度,使用該方法的訣竅在於要選擇足夠長的前綴以確保較高的選擇性,通過又不能太長。
範例
表格結構及資料MySQL官網或GItHub下載。
city Table Columns
| 欄位名稱 | 意義 |
|---|---|
| city_id | 城市主鍵ID |
| city | 城市名 |
| #country_id | 「國家ID |
| last_update: | 建立或最近更新時間 |
--计算完整列的选择性
select count(distinct left(city,3))/count(*) as sel3,
count(distinct left(city,4))/count(*) as sel4,
count(distinct left(city,5))/count(*) as sel5,
count(distinct left(city,6))/count(*) as sel6,
count(distinct left(city,7))/count(*) as sel7,
count(distinct left(city,8))/count(*) as sel8
from citydemo;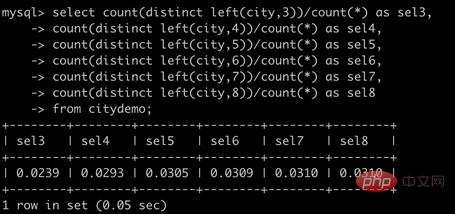
可以看到当前缀长度到达7之后,再增加前缀长度,选择性提升的幅度已经很小了。由此最佳创建前缀索引长度为7。
2.3 回表
要理解回表需要先了解聚族索引和普通索引。聚族索引即建表时设置的主键索引,如果没有设置MySQL自动将第一个非空唯一值作为索引,如果还是没有InnoDB会创建一个隐藏的row-id作为索引(oracle数据库row-id显式展示,可以用于分页);普通索引就是给普通列创建的索引。普通列索引在叶子节点中存储的并不是整行数据而是主键,当按普通索引查找时会先在B+树中查找该列的主键,然后根据主键所在的B+树中查找改行数据,这就是回表。
2.4 覆盖索引
覆盖索引在InnoDB中特别有用。MySQL中可以使用索引直接获取列的数据,如果索引的叶子节点中已经包含要查询的数据,那么就没必要再回表查询了,如果一个索引包含(覆盖)所有需要查询的字段的值,那么该索引就是覆盖索引。简单的说:不回表直接通过一次索引查找到列的数据就叫覆盖索引。
表信息
CREATE TABLE `t_user` ( `uid` int(11) NOT NULL AUTO_INCREMENT, `uname` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`uid`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
举例
--将uid设置成主键索引后通过下面的SQL查询 在explain的Extra列可以看到“Using index” explain select uid from t_user where uid = 1;

覆盖索引在组合索引中用的比较多,举例
explain select age,uname from t_user where age = 10 ;
当不建立组合索引时,会进行回表查询

设置组合索引后再次查询
create index index_user on t_user(age,uname);

2.5 索引匹配方式
2.5.1 最左匹配
在使用组合索引中,比如设置(age,name)为组合索引,单独使用组合索引中最左列是可以匹配索引的,如果不使用最左列则不走索引。例如下面SQL
--走索引 explain select * from t_user where age=10 and uname='zhang';

下面的SQL不走索引
explain select * from t_user where uname='zhang';

2.5.2 匹配列前缀
可以匹配某一列的值的开头部分,比如like 'abc%'。
2.5.3 匹配范围值
可以查找某一个范围的数据。
explain select * from t_user where age>18;

2.5.4 精确匹配某一列并范围匹配另外一列
可以查询第一列的全部和第二列的部分
explain select * from t_user where age=18 and uname like 'zhang%';

2.5.5 只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引。
explain select age,uname,update_time from t_user
where age=18 and uname= 'zhang' and update_time='123';
3 索引优化最佳实践
1. 当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层。
--推荐 select uid,age,uname from t_user where uid=1; --不推荐 select uid,age,uname from t_user where uid+9=10;
2. 尽量使用主键查询,而不是其他索引,因为主键查询不会触发回表查询
3. 使用前缀索引参考2.2 前缀索引
4. 使用索引扫描排序mysql有两种方式可以生成有序的结果:通过排序操作或者按索引顺序扫描,如果explain出来的type列的值为index,则说明mysql使用了索引扫描来做排序。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那么就不得不每扫描一条索引记录就得回表查询一次对应的行,这基本都是随机IO,因此按索引顺序读取数据的速度通常要比顺序地全表扫描慢。
mysql可以使用同一个索引即满足排序,又用于查找行,如果可能的话,设计索引时应该尽可能地同时满足这两种任务。
只有当索引的列顺序和order by子句的顺序完全一致,并且所有列的排序方式都一样时,mysql才能够使用索引来对结果进行排序,如果查询需要关联多张表,则只有当orderby子句引用的字段全部为第一张表时,才能使用索引做排序。order by子句和查找型查询的限制是一样的,需要满足索引的最左前缀的要求,否则,mysql都需要执行顺序操作,而无法利用索引排序。
举例表结构及数据MySQL官网或GItHub下载。
CREATE TABLE `rental` ( `rental_id` int(11) NOT NULL AUTO_INCREMENT, `rental_date` datetime NOT NULL, `inventory_id` mediumint(8) unsigned NOT NULL, `customer_id` smallint(5) unsigned NOT NULL, `return_date` datetime DEFAULT NULL, `staff_id` tinyint(3) unsigned NOT NULL, `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`rental_id`), UNIQUE KEY `rental_date` (`rental_date`,`inventory_id`,`customer_id`), KEY `idx_fk_inventory_id` (`inventory_id`), KEY `idx_fk_customer_id` (`customer_id`), KEY `idx_fk_staff_id` (`staff_id`), CONSTRAINT `fk_rental_customer` FOREIGN KEY (`customer_id`) REFERENCES `customer` (`customer_id`) ON UPDATE CASCADE, CONSTRAINT `fk_rental_inventory` FOREIGN KEY (`inventory_id`) REFERENCES `inventory` (`inventory_id`) ON UPDATE CASCADE, CONSTRAINT `fk_rental_staff` FOREIGN KEY (`staff_id`) REFERENCES `staff` (`staff_id`) ON UPDATE CASCADE ) ENGINE=InnoDB AUTO_INCREMENT=16050 DEFAULT CHARSET=utf8mb4;
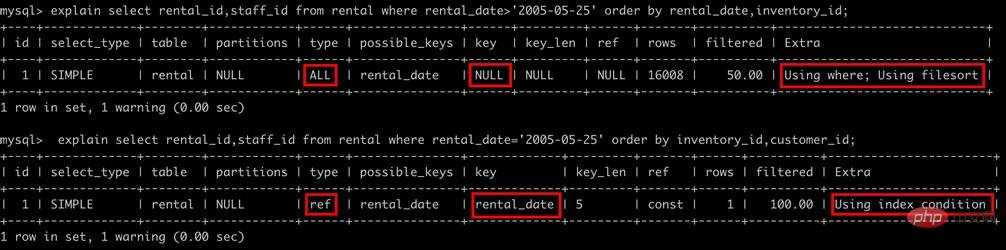
rental表在rental_date,inventory_id,customer_id上有rental_date的索引。使用rental_date索引为下面的查询做排序
--该查询为索引的第一列提供了常量条件,而使用第二列进行排序,将两个列组合在一起,就形成了索引的最左前缀 explain select rental_id,staff_id from rental where rental_date='2005-05-25' order by inventory_id desc --下面的查询不会利用索引 explain select rental_id,staff_id from rental where rental_date>'2005-05-25' order by rental_date,inventory_id
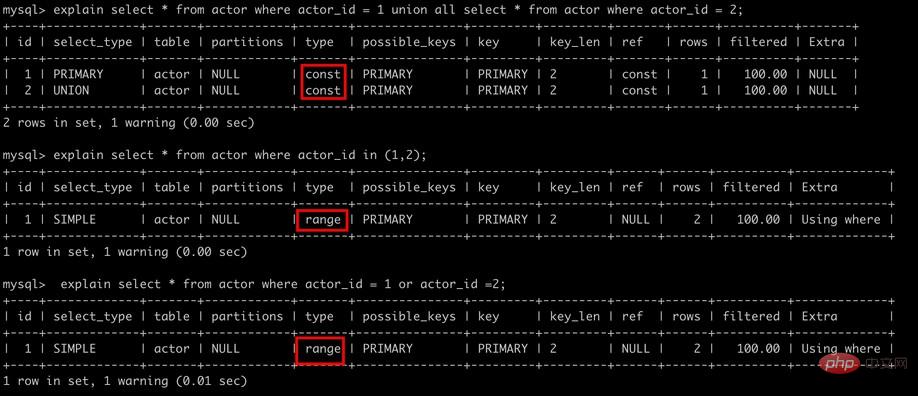
5. union all,in,or都能够使用索引,但是推荐使用in
explain select * from actor where actor_id = 1 union all select * from actor where actor_id = 2; explain select * from actor where actor_id in (1,2); explain select * from actor where actor_id = 1 or actor_id =2;
6. 范围列可以用到索引范围条件是:<、<=、>、>=、between。范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列。
7. 更新十分频繁,数据区分度不高的字段上不宜建立索引
更新会变更B+树,更新频繁的字段建议索引会大大降低数据库性能;
类似于性别这类区分不大的属性,建立索引是没有意义的,不能有效的过滤数据;
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算;
8. 创建索引的列,不允许为null,可能会得到不符合预期的结果
9.当需要进行表连接的时候,最好不要超过三张表,如果需要join的字段,数据类型必须一致
10. 能使用limit的时候尽量使用limit
11. 单表索引建议控制在5个以内
12. 单索引字段数不允许超过5个(组合索引)
13. 创建索引的时候应该避免以下错误概念
索引越多越好
过早优化,在不了解系统的情况下进行优化
4 索引监控
show status like 'Handler_read%';
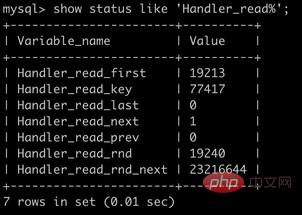
| 参数 | 说明 |
|---|---|
| Handler_read_first | 读取索引第一个条目的次数 |
| Handler_read_key | 通过index获取数据的次数 |
| Handler_read_last | 读取索引最后一个条目的次数 |
| Handler_read_next | 通过索引读取下一条数据的次数 |
| Handler_read_prev | 通过索引读取上一条数据的次数 |
| Handler_read_rnd | 从固定位置读取数据的次数 |
| Handler_read_rnd_next | 从数据节点读取下一条数据的次数 |
以上是怎麼為MySQL建立高效能索引的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受歡迎的數據庫的簡介
Apr 12, 2025 am 12:18 AM
MySQL是一種開源的關係型數據庫管理系統,主要用於快速、可靠地存儲和檢索數據。其工作原理包括客戶端請求、查詢解析、執行查詢和返回結果。使用示例包括創建表、插入和查詢數據,以及高級功能如JOIN操作。常見錯誤涉及SQL語法、數據類型和權限問題,優化建議包括使用索引、優化查詢和分錶分區。
 MySQL的位置:數據庫和編程
Apr 13, 2025 am 12:18 AM
MySQL的位置:數據庫和編程
Apr 13, 2025 am 12:18 AM
MySQL在數據庫和編程中的地位非常重要,它是一個開源的關係型數據庫管理系統,廣泛應用於各種應用場景。 1)MySQL提供高效的數據存儲、組織和檢索功能,支持Web、移動和企業級系統。 2)它使用客戶端-服務器架構,支持多種存儲引擎和索引優化。 3)基本用法包括創建表和插入數據,高級用法涉及多表JOIN和復雜查詢。 4)常見問題如SQL語法錯誤和性能問題可以通過EXPLAIN命令和慢查詢日誌調試。 5)性能優化方法包括合理使用索引、優化查詢和使用緩存,最佳實踐包括使用事務和PreparedStatemen
 apache怎麼連接數據庫
Apr 13, 2025 pm 01:03 PM
apache怎麼連接數據庫
Apr 13, 2025 pm 01:03 PM
Apache 連接數據庫需要以下步驟:安裝數據庫驅動程序。配置 web.xml 文件以創建連接池。創建 JDBC 數據源,指定連接設置。從 Java 代碼中使用 JDBC API 訪問數據庫,包括獲取連接、創建語句、綁定參數、執行查詢或更新以及處理結果。
 為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
為什麼要使用mysql?利益和優勢
Apr 12, 2025 am 12:17 AM
選擇MySQL的原因是其性能、可靠性、易用性和社區支持。 1.MySQL提供高效的數據存儲和檢索功能,支持多種數據類型和高級查詢操作。 2.採用客戶端-服務器架構和多種存儲引擎,支持事務和查詢優化。 3.易於使用,支持多種操作系統和編程語言。 4.擁有強大的社區支持,提供豐富的資源和解決方案。
 docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中啟動 MySQL 的過程包含以下步驟:拉取 MySQL 鏡像創建並啟動容器,設置根用戶密碼並映射端口驗證連接創建數據庫和用戶授予對數據庫的所有權限
 MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL在Web應用中的主要作用是存儲和管理數據。 1.MySQL高效處理用戶信息、產品目錄和交易記錄等數據。 2.通過SQL查詢,開發者能從數據庫提取信息生成動態內容。 3.MySQL基於客戶端-服務器模型工作,確保查詢速度可接受。
 laravel入門實例
Apr 18, 2025 pm 12:45 PM
laravel入門實例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用於輕鬆構建 Web 應用程序。它提供一系列強大的功能,包括:安裝: 使用 Composer 全局安裝 Laravel CLI,並在項目目錄中創建應用程序。路由: 在 routes/web.php 中定義 URL 和處理函數之間的關係。視圖: 在 resources/views 中創建視圖以呈現應用程序的界面。數據庫集成: 提供與 MySQL 等數據庫的開箱即用集成,並使用遷移來創建和修改表。模型和控制器: 模型表示數據庫實體,控制器處理 HTTP 請求。
 centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
優雅安裝 MySQL 的關鍵在於添加 MySQL 官方倉庫。具體步驟如下:下載 MySQL 官方 GPG 密鑰,防止釣魚攻擊。添加 MySQL 倉庫文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 倉庫緩存:yum update安裝 MySQL:yum install mysql-server啟動 MySQL 服務:systemctl start mysqld設置開機自啟動
