

史丹佛、Meta AI研究:實現AGI之路,資料剪枝比我們想像得更重要

在視覺、語言和語音在內的機器學習諸多領域中,神經標度律表明,測試誤差通常隨著訓練資料、模型大小或計算數量而下降。這種成比例提升已經推動深度學習實現了實質的表現成長。然而,這些僅透過縮放實現的提昇在計算和能源方面帶來了相當高的成本。
這種成比例的縮放是不可持續的。例如,想要誤差從 3% 下降到 2% 所需的資料、計算或能量會呈指數級增長。先前的一些研究表明,在大型 Transformer 的語言建模中,交叉熵損失從 3.4 下降到 2.8 需要 10 倍以上的訓練資料。此外,對於大型視覺 Transformer,額外的 20 億預訓練資料點 (從 10 億開始) 在 ImageNet 上僅能帶來幾個百分點的準確率成長。
所有這些結果都揭示了深度學習中資料的本質,同時表明收集巨大資料集的實踐可能是很低效的。這裡要討論的是,我們是否可以做得更好。例如,我們是否可以用一個選擇訓練樣本的良好策略來實現指數縮放呢?
在最近的一篇文章中,研究者發現,只增加一些精心選擇的訓練樣本,可以將誤差從3% 降到2% ,而無需收集10 倍以上的隨機樣本。簡而言之,「Sale is not all you need」。

論文連結:https://arxiv.org/pdf/2206.14486.pdf
整體來說,這項研究的貢獻在於:
1. 利用統計力學,發展了一種新的資料剪枝分析理論,在師生感知機學習環境中,樣本根據其教師邊際進行剪枝,大(小) 邊際各對應於簡單(困難) 樣本。該理論在數量上與數值實驗相符,並揭示了兩個驚人的預測:
a.最佳剪枝策略會因初始數據的數量而改變;如果初始數據豐富(稀缺) ,則應只保留困難(容易) 的樣本。
b.如果選擇一個遞增的帕累托最適剪枝分數作為初始資料集大小的函數,那麼對於剪枝後的資料集大小,指數縮放是可能的。

2. 研究表明,這兩個預測在更多通用設定的實踐中依舊成立。他們驗證了在 SVHN、CIFAR-10 和 ImageNet 上從頭訓練的 ResNets,以及在 CIFAR-10 上進行微調的視覺 Transformer 的與剪枝資料集大小有關的誤差指數縮放特徵。
3. 在 ImageNet 上對 10 個不同的資料剪枝度量進行了大規模基準測試研究,發現除了計算密集度最高的度量之外,大多數度量表現不佳。
4. 利用自監督學習開發了一種新的低成本無監督剪枝度量,不同於先前的度量,它不需要標籤。研究者證明了這種無監督度量與最好的監督剪枝度量相媲美,而後者需要標籤和更多的計算。這個結果揭示了一種可能性:利用預訓練基礎模型來修剪新資料集。
Is scale all you need?
研究者的感知器資料剪枝理論提出了三個驚人的預測,可以在更通用的環境下進行測試,例如在benchmark 上訓練的深度神經網路:
( 1) 相對於隨機資料剪枝,當初始資料集比較大時,只保留最難的樣本是有收益的,但當初始資料集比較小時,這樣反而有害;
(2) 隨著初始資料集大小的增加,透過保留最難樣本的固定分數f 進行的資料剪枝應該產生冪律縮放,指數等於隨機剪枝;
(3) 在初始資料集大小和所保留資料的分數上優化的測試誤差,可以透過在更大初始資料集上進行更積極的剪枝,追蹤出一個帕累托最優下包絡線,打破了測試誤差和剪枝資料集大小之間的冪律縮放函數關係。
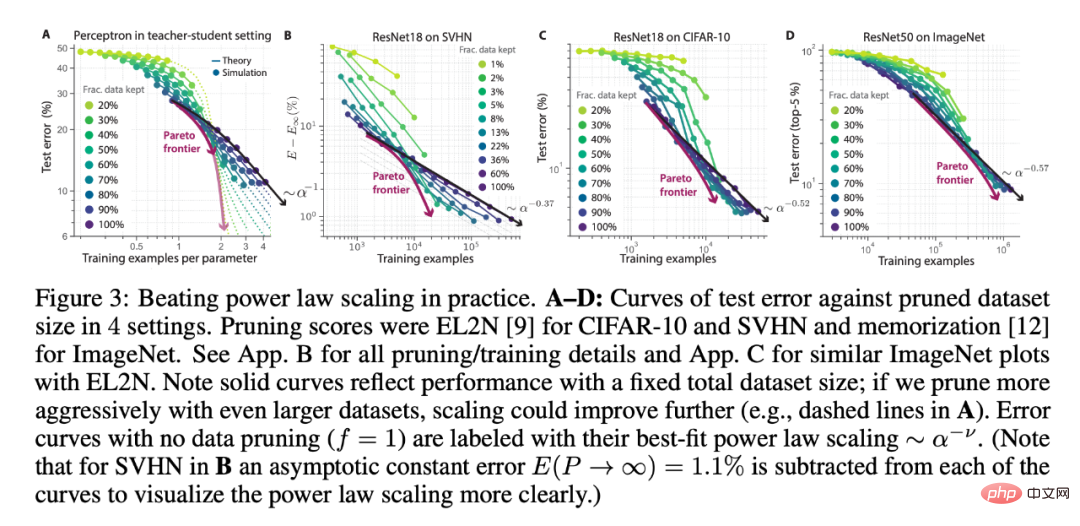
研究者以不同數量的初始資料集大小和資料剪枝下保存的資料分數(圖3A 中的理論對比圖3BCD 中的深度學習實驗) ,在SVHN、CIFAR-10 和ImageNet 上訓練的ResNets 驗證了上述三個預測。在每個實驗設定中,可以看到,較大的初始資料集大小和更積極的剪枝比冪律縮放表現更好。此外,更大的初始資料集可能會看到更好的縮放(如圖 3A)。
此外,研究者發現資料剪枝可以提升遷移學習的表現。他們首先分析了在 ImageNet21K 上預先訓練的 ViT,然後在 CIFAR-10 的不同剪枝子集上進行了微調。有趣的是,預先訓練的模型允許更積極的資料剪枝;只有 10% 的 CIFAR-10 的微調可以媲美或超過所有 CIFAR-10 的微調所獲得的性能 (圖 4A)。此外,圖 4A 提供了一個在微調設定中打破冪律縮放的樣本。

透過在ImageNet1K 的不同剪枝子集(如圖3D 所示) 上預訓練ResNet50,研究者檢查了剪枝預訓練資料的功效,然後在CIFAR -10 上對它們進行微調。如圖 4B 所示,在最少 50% 的 ImageNet 上進行的預訓練能夠達到或超過在所有 ImageNet 上進行的預訓練所獲得的 CIFAR-10 性能。
因此,對上游任務的訓練前資料進行剪枝仍然可以在不同的下游任務上保持高效能。總體來說,這些結果顯示了剪枝在預訓練和微調階段的遷移學習中的前景。
在ImageNet 上對監督剪枝指標進行基準測試
研究者註意到,大多數的資料剪枝實驗都是在小規模資料集(即MNIST 和CIFAR 的變體)上進行的。所以,為 ImageNet 提出的少數剪枝度量很少與在較小資料集上設計的 baseline 進行比較。
因此,目前尚不清楚大多數剪枝方法如何縮放到 ImageNet 以及哪種方法最好。為研究剪枝度量的品質在理論上對性能的影響,研究者決定透過在 ImageNet 上對 8 個不同的監督剪枝度量進行系統評估來填補這一知識空白。

他們觀察到測量之間的顯著表現差異:圖 5BC 顯示了當每個測量下的最難樣本的一部分保留在訓練集中時的測試表現。在較小的資料集上,許多度量都取得了成功,但在選擇一個明顯較小的訓練子集(如 Imagenet 的 80%)時,只有少數度量在完整資料集訓練中仍然獲得了相當的效能。
儘管如此,大多數度量仍然優於隨機剪枝(圖 5C)。研究者發現所有剪枝度量都會放大類別的不平衡,從而導致效能下降。為了解決這個問題,作者在所有 ImageNet 實驗中使用了一個簡單的 50% 類平衡率。
透過原型度量進行自監督資料剪枝
如圖 5 ,許多資料剪枝度量不能很好地縮放到 ImageNet,其中一些確實需要大量計算。此外,所有這些度量都需要標註,這限制了它們為在大量未標註資料集訓練大規模基礎模型的資料剪枝能力。因此,我們顯然需要簡單、可縮放、自我監督的剪枝度量。

為了評估測量所發現的聚類是否與 ImageNet 類別一致,研究者在圖 6A 中比較了它們的重疊。當保留 70% 以上的數據時,自監督度量和監督度量的表現是相似的,這表明了自監督剪枝的前景。
更多研究細節,可參考原論文。
以上是史丹佛、Meta AI研究:實現AGI之路,資料剪枝比我們想像得更重要的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
 如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
檢查CentOS系統中HDFS配置的完整指南本文將指導您如何有效地檢查CentOS系統上HDFS的配置和運行狀態。以下步驟將幫助您全面了解HDFS的設置和運行情況。驗證Hadoop環境變量:首先,確認Hadoop環境變量已正確設置。在終端執行以下命令,驗證Hadoop是否已正確安裝並配置:hadoopversion檢查HDFS配置文件:HDFS的核心配置文件位於/etc/hadoop/conf/目錄下,其中core-site.xml和hdfs-site.xml至關重要。使用
 CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系統下GitLab的備份與恢復策略為了保障數據安全和可恢復性,CentOS上的GitLab提供了多種備份方法。本文將詳細介紹幾種常見的備份方法、配置參數以及恢復流程,幫助您建立完善的GitLab備份與恢復策略。一、手動備份利用gitlab-rakegitlab:backup:create命令即可執行手動備份。此命令會備份GitLab倉庫、數據庫、用戶、用戶組、密鑰和權限等關鍵信息。默認備份文件存儲於/var/opt/gitlab/backups目錄,您可通過修改/etc/gitlab
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系統下查看GitLab日誌的完整指南本文將指導您如何查看CentOS系統中GitLab的各種日誌,包括主要日誌、異常日誌以及其他相關日誌。請注意,日誌文件路徑可能因GitLab版本和安裝方式而異,若以下路徑不存在,請檢查GitLab安裝目錄及配置文件。一、查看GitLab主要日誌使用以下命令查看GitLabRails應用程序的主要日誌文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令會顯示produc
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
