
首先,來跟大家解釋一個名詞,大家在看分散式事務相關資料的時候,常常會看到一個名詞:反向補償。啥是反向補償呢?
我舉一個例子:假設我們現在有三個微服務分別是A、B、C,現在在A 服務中分別呼叫B 和C 服務,為了確保B 和C 同時成功或同時失敗,我們需要使用到分散式事務。但是按照我們之前對本地事務的理解,B 和C 中的本地事務,當B 服務中的事務執行完畢並且提交之後,現在C 服務中的事務出現異常需要回滾了,但是,B 已經提交了還怎麼回滾呀?
此時我們所說的回滾其實並不是傳統意義上的,透過MySQL redo log 日誌來回滾的那種,而是透過一條更新SQL,再把B 服務中已經更改過的數據復原。
這就是我們所說的反向補償!
Seata 中有三個核心概念:
我們來看如下一張圖片:
@GlobalTransactional 註解來實現的,換句話說,這個註解該加在哪裡?加入該註解的地方其實就是事務管理器 TM 了。
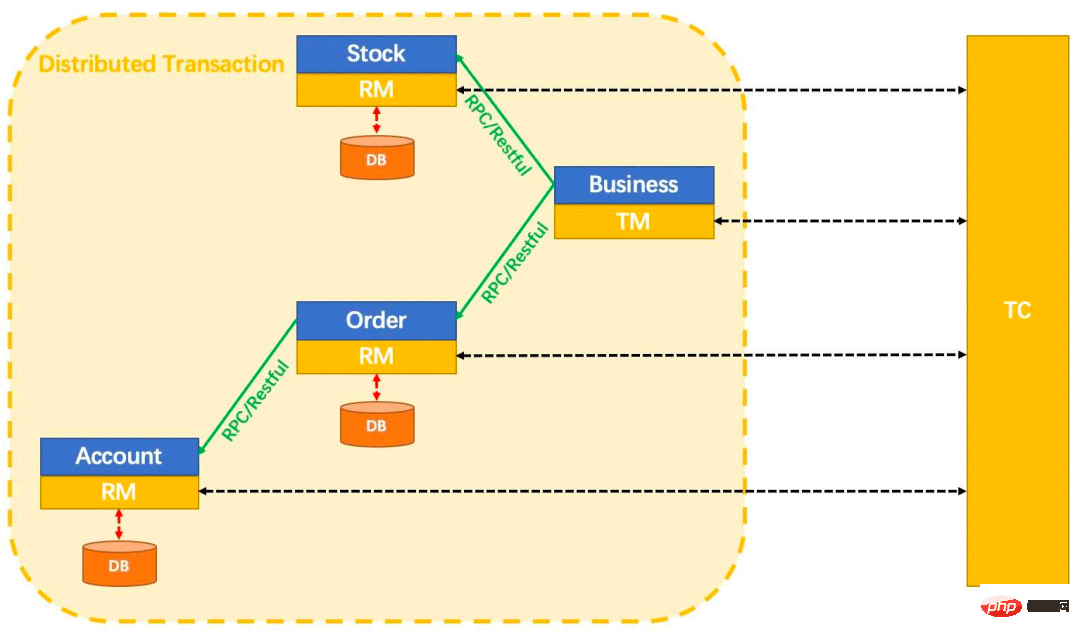
先來看下面一張圖:

這張圖裡牽涉到三個概念:
AP:這個不用多說,AP 就是應用程式本身。
RM:RM 是資源管理器,也就是事務的參與者,大部分情況下就是指資料庫,一個分散式事務往往涉及到多個RM。
TM:TM 就是事務管理器,建立分散式事務並協調分散式事務中的各個子事務的執行和狀態,子事務就是指在RM 上執行的具體操作。
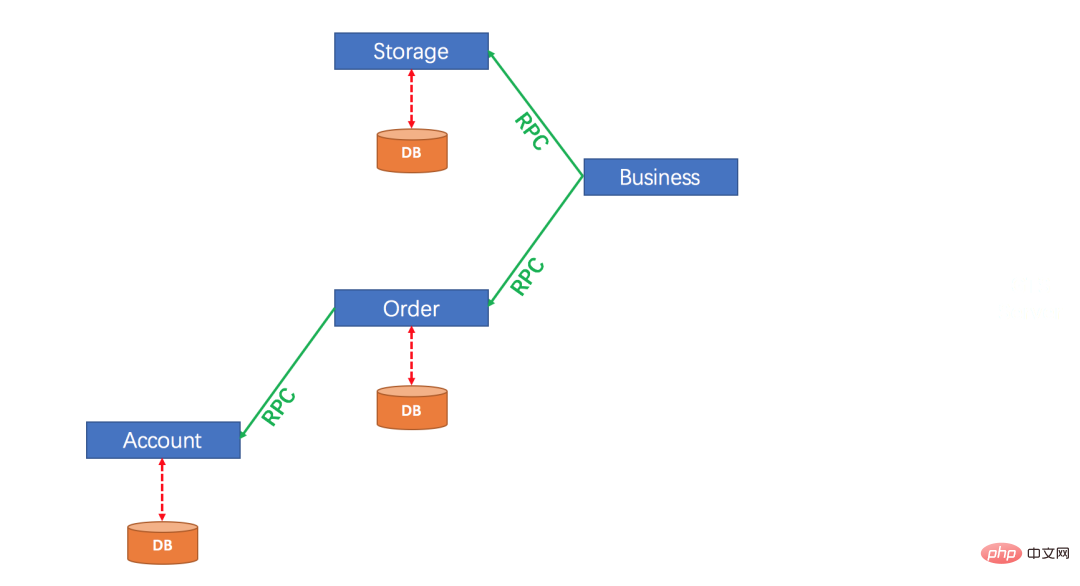 #我們在Business 中分別呼叫Storage 與Order、Account,這三個中的操作要同時成功或同時失敗,但是由於這三個分處於不同服務,因此我們只能先讓這三個服務中的操作各自執行,三個服務中的事務各自執行就是兩階段中的第一階段。
#我們在Business 中分別呼叫Storage 與Order、Account,這三個中的操作要同時成功或同時失敗,但是由於這三個分處於不同服務,因此我們只能先讓這三個服務中的操作各自執行,三個服務中的事務各自執行就是兩階段中的第一階段。
第一階段執行完畢後,先不要急著提交,因為三個服務中有的可能執行失敗了,此時需要三個服務各自把自己一階段的執行結果報告給一個事務協調者,事務協調者收到訊息後,如果三個服務的一階段都執行成功了,此時就通知三個事務分別提交,如果三個服務中有服務執行失敗了,此時就通知三個事務分別回滾。
這就是所謂的兩階段提交。
總結一下:兩階段提交中,事務分為參與者(例如上圖的各個具體服務)與協調者,參與者將操作成敗通知協調者,再由協調者根據所有參與者的回饋情報決定各參與者是要提交操作還是中止操作,這裡的參與者可以理解為RM,協調者可以理解為TM。
不過 Seata 中的各個分散式事務模式,基本上都是在二階段提交的基礎上演化出來的,因此並不完全一樣,這點需要小伙伴們注意。
AT 模式是一種全自動的交易回溯模式。
整體上來說,AT 模式是兩階段提交協定的演進:
一階段:業務資料和回溯日誌記錄在同一個本地事務中提交,釋放本地鎖定和連線資源。
二階段則分成兩種情況:2.1 提交非同步化,非常快速地完成。 2.2 回滾透過一階段的回滾日誌進行反向補償。
大致上的邏輯就是上面這樣,我們透過一個具體的案例來看看AT 模式是如何運作的:
假設有一個業務表product,如下:
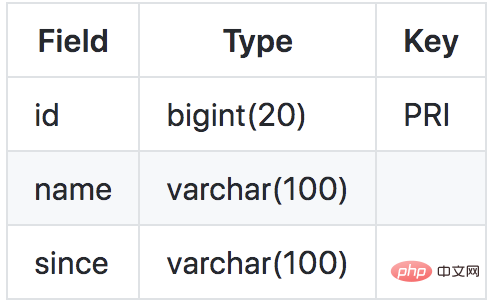
現在我們想做如下一個更新操作:
update product set name = 'GTS' where name = 'TXC';
步驟如下:
一階段:
解析SQL:得到SQL 的型別(UPDATE),表(product),條件(where name = 'TXC')等相關的資訊。
查詢前鏡像:根據解析得到的條件信息,產生查詢語句,定位資料(查找到更新之前的資料)。
執行上面的更新 SQL。
查詢後鏡像:根據前鏡像的結果,透過主鍵定位資料。
插入回滾日誌:把前後鏡像資料以及業務 SQL 相關的資訊組成一條回滾日誌記錄,插入到 UNDO_LOG 表中。
提交前,向 TC 註冊分支:申請 product 表中,主鍵值等於 1 的記錄的 全域鎖定。
本地交易提交:業務資料的更新和前面步驟中產生的 UNDO LOG 一併提交。
將本地交易提交的結果回報給 TC。
二階段:
二階段分兩種情況,提交或回滾。
先來看回溯步驟:
先收到 TC 的分支回溯請求,開啟一個本機事務,執行下列操作。
透過 XID 和 Branch ID 查找到對應的 UNDO LOG 記錄(這條記錄中保存了資料修改前後對應的鏡像)。
資料校驗:拿 UNDO LOG 中的後映像與目前資料比較,如果有不同,表示資料被目前全域事務以外的動作做了修改。這種情況,需要根據配置策略來做處理。
根據UNDO LOG 中的前映像和業務SQL 的相關資訊產生並執行回滾的語句:update product set name = 'TXC' where id = 1;
提交本機事務。並且把本地事務的執行結果(即分支事務回溯的結果)回報給 TC。
再來看提交步驟:
#收到TC 的分支提交請求,把請求放入一個非同步任務的隊列中,馬上返回提交成功的結果給TC。
非同步任務階段的分支提交請求將非同步和批次地刪除對應 UNDO LOG 記錄。
大致上就是這樣一個步驟,思路還是比較清晰的,就是當你要更新一筆記錄的時候,系統將這條記錄更新之前和更新之後的內容生成一段JSON並存入undo log 表中,將來要回滾的話,就根據undo log 中的記錄去更新資料(反向補償),將來要是不回滾的話,就刪除undo log 中的記錄。
在整個過程中,開發者只需要額外建立一張 undo log 表就行了,然後給需要處理全域事務的地方加上 @GlobalTransactional 註解就行了。
其他的提交呀回滾呀都是全自動的,比較省事。所以如果你專案中選擇了用 seata 來處理分散式事務,那麼用 AT 模式的機率還是相當高的。
TCC(Try-Confirm-Cancel) 模式就帶一點手動的感覺了,它也是兩階段,但是和AT 又不太一樣,我們來看下流程。
官網上有一張TCC 的流程圖,我們來看下:
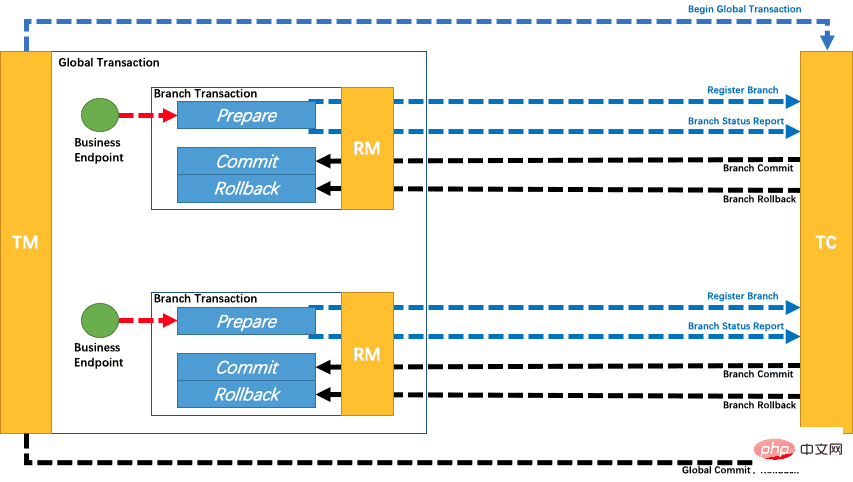
可以看到,TCC 也是分為兩階段:
第一階段是prepare,在這個階段主要是做資源的檢測和預留工作,例如銀行轉賬,這個階段就先去檢查下用戶的錢夠不夠,不夠就直接拋異常,夠就先給凍結。
第二階段是commit 或rollback,這個主要是等各個分支事務的一階段都執行完畢,都執行完畢後各自將自己的情況報告給TC,TC 一統計,發現各個分支事務都沒有異常,那麼就通知大家一起提交;如果TC 發現有分支事務發生異常了,那麼就通知大家回滾。
那麼小夥伴可能也發現了,上面這個流程中,總共涉及了三個方法,prepare、commit 以及rollback,這三個方法都完全是用戶自訂的方法,都是需要我們自己來實現的,所以我一開始就說TCC 是一種手動的模式。
和AT 相比,大家發現TCC 這種模式其實是不依賴底層資料庫的事務支援的,也就是說,就算你底層資料庫不支援事務也沒關係,反正prepare、commit 以及rollback 三個方法都是開發者自己寫的,我們自己將這三個方法對應的流程捋順就行了。
如果小夥伴們懂得 MySQL 資料庫的 XA 事務,那麼一下子就懂得 seata 中的 XA 模式是咋回事了。
XA 規範是 X/Open 組織定義的分散式事務處理(DTP,Distributed Transaction Processing)標準。
XA 規範描述了全域的事務管理器與局部的資源管理器之間的介面。 XA規範的目的是允許的多個資源(如資料庫,應用伺服器,訊息佇列等)在同一事務中訪問,這樣可以使 ACID 屬性跨越應用程式而保持有效。
XA 規範使用兩階段提交來保證所有資源同時提交或回滾任何特定的交易。
XA 規範在 90 年代初就被提出。目前,幾乎所有主流的資料庫都對 XA 規範提供了支援。
XA 事務的基礎是兩階段提交協定。需要有一個事務協調者來保證所有的事務參與者都完成了準備工作(第一階段)。如果協調者收到所有參與者都準備好的訊息,就會通知所有的事務都可以提交了(第二階段)。 MySQL 在這個 XA 事務中扮演的是參與者的角色,而不是協調者(事務管理器)。
MySQL 的 XA 事務分為內部 XA 和外部 XA。外部XA 可以參與到外部的分散式事務中,需要應用層介入作為協調者;內部XA 事務用於同一實例下跨多引擎事務,由Binlog 作為協調者,例如在一個儲存引擎提交時,需要將提交資訊寫入二進位日誌,這就是一個分散式內部XA 事務,只不過二進位日誌的參與者是MySQL 本身。 MySQL 在 XA 事務中扮演的是一個參與者的角色,而不是協調者。
換言之,MySQL 天然的就可以透過 XA 規範來實現分散式事務,只不過需要藉助一些外部應用的支援。我們來看看 Seata 中的 XA 模式使用流程。
先來看一張來自官方的圖片:
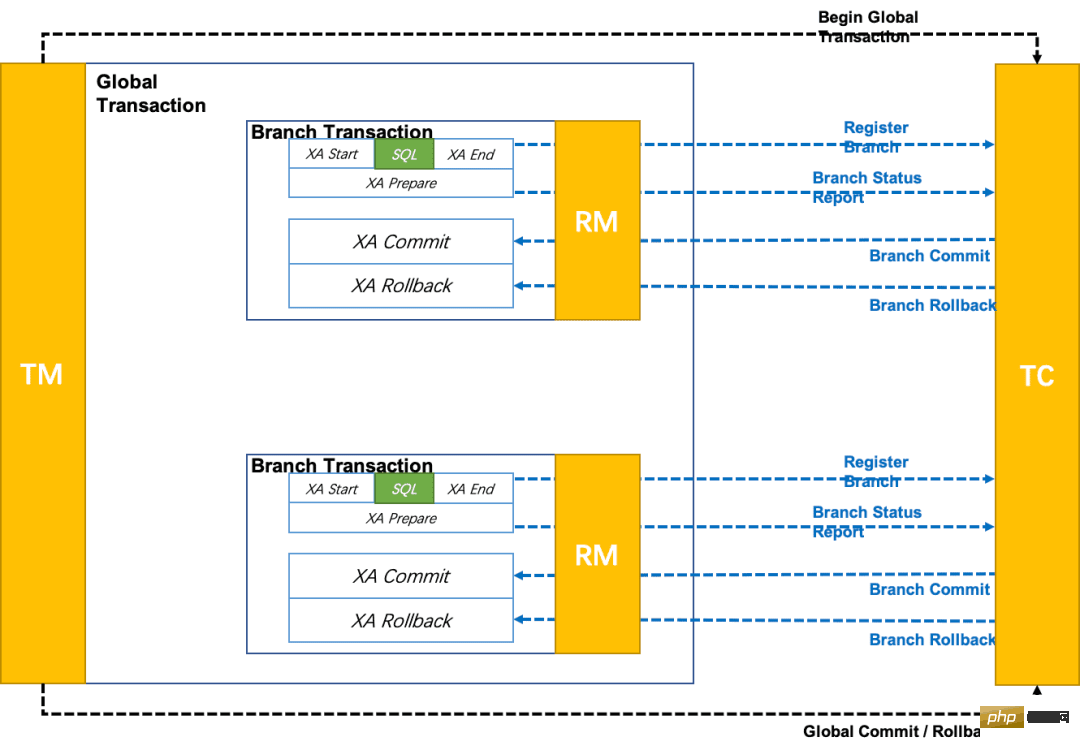
#可以看到,這也是一個兩階段提交:
一階段:業務SQL 作業放在XA 分支中進行,XA 分支完成後,執行XA prepare,由RM 對XA 協定的支援來確保持久化(即之後任何意外都不會造成無法回滾的情況)。
二階段分兩種情況:提交或回滾:
#分支提交:執行XA 分支的commit
分支回滾:執行XA 分支的rollback
和前面兩種模式的差別在於,XA 模式中的回滾,是正兒八經的回滾,是我們傳統意義上所理解的回滾,而不是一種反向補償。
最後再來看看 saga 模式,這個模式應用很少,大家作為了解即可。
saga 模式是 seata 提供的長事務解決方案,然而長事務是我們在開發中應該避免的,因為效率低並且容易造成死鎖。
這個saga 模式就有點像流程引擎,開發者先自己畫一個流程引擎,把整個事務中涉及到的方法都囊括進來,每一個方法返回什麼的時候就是正常的,返回什麼就是異常的,正常的就繼續往下走,異常的就執行另一套流程,也就是我們需要事先準備好兩套方法,第一套是各種正常狀況的執行流程,第二套則是發生異常之後的執行流程,類似下面這樣:
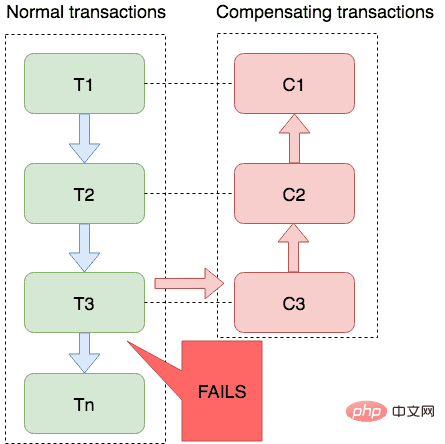
綠色的都是正常的流程,紅色的則是發生異常後回滾的流程。回滾中也是一種反向補償。
以上是Java Spring Boot分散式事務問題怎麼解決的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















