
史上AI最高分,Google新模型剛通過美國醫師執照試題驗證!
而且在科學常識、理解、檢索和推理能力等任務中,直接與人類醫生水平相匹敵。在一些臨床問答表現中,最高超原SOTA模型17%以上。


此進展一出,瞬間引爆學界熱議,不少業內人士感嘆:終於,它來了。
廣大網友在看完Med-PaLM與人類醫師的比較後,則是紛紛表示已經在期待AI醫師上崗了。

還有人調侃這個時間點的精準,恰逢大家都以為Google會因ChatGPT而「死」之際。

來看看這到底是什麼樣的研究?
由於醫療的專業性,今天的AI模型在該領域的應用很大程度上沒有充分運用語言。這些模型雖然有用,但有聚焦單任務系統(如分類、迴歸、分割等)、缺乏表現力和互動能力等問題。
大模型的突破為AI 醫療帶來了新的可能性,但由於該領域的特殊性,仍需考慮潛在的危害,例如提供虛假醫療資訊。
基於這樣的背景,Google研究院和DeepMind團隊以醫療問答為研究對象,做出了以下貢獻:

他們認為「醫療問題的回答」這項任務很有挑戰性,因為要提供高品質的答案,AI需要理解醫學背景、回憶適當的醫學知識,並對專家資訊進行推理。
現有的評估基準往往侷限於評估分類準確度或自然語言產生指標,而不能對實際臨床應用中詳細分析。
首先,團隊提出了一個由7個醫學問題問答資料集組成的基準。
包括6個現有資料集,其中還包括MedQA(USMLE,美國醫師執照考試題),也引入了他們自己的新資料集HealthSearchQA,它由搜尋過的健康問題組成。
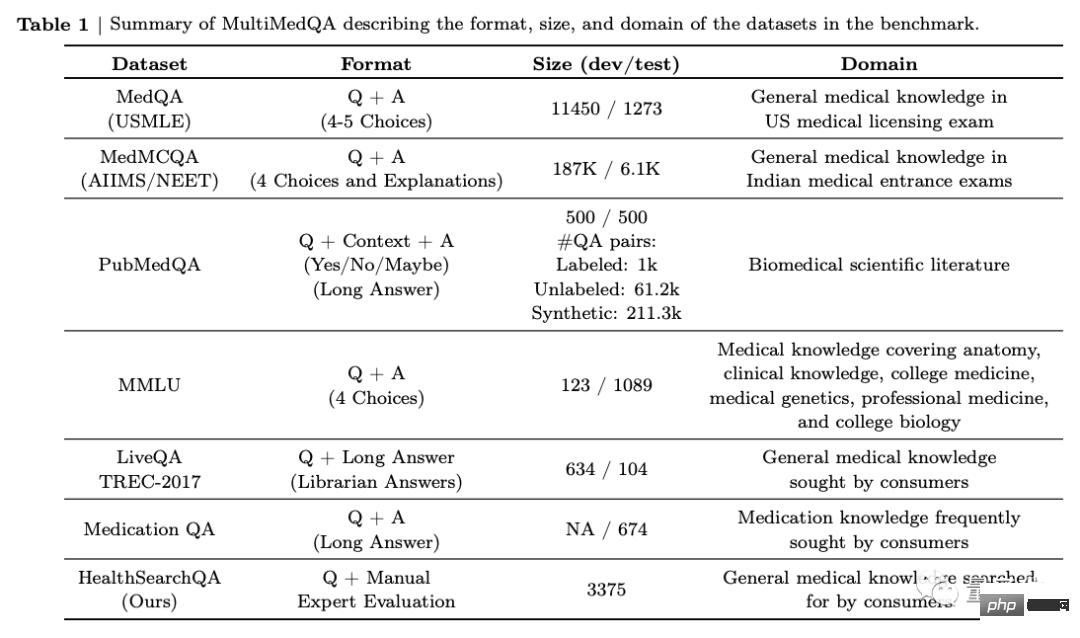
這當中有關於醫學考試、醫學研究、消費者醫學問題等。
接著,團隊以MultiMedQA評估了PaLM(5,400億參數)、以及指令微調後的變體Flan-PaLM。例如透過擴大任務數、模型大小和使用思維鏈資料的策略。
FLAN是谷歌研究院去年提出的微調語言網絡,對模型進行微調使其更適用於通用NLP任務,使用指令調整來訓練模型。
結果發現,Flan-PaLM在幾個基準上達到了最優效能,例如MedQA、MedMCQA、PubMedQA和MMLU。尤其是MedQA(USMLE)資料集,表現超過了先前SOTA模型17%以上。
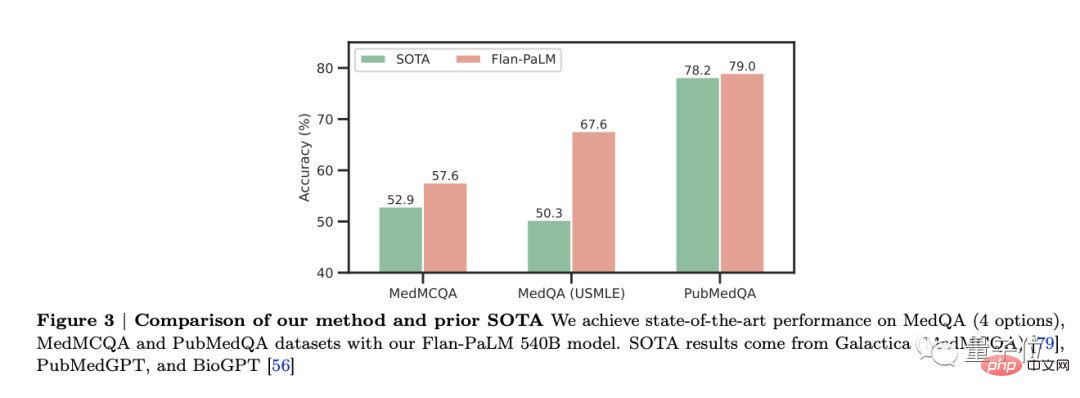
本研究中,共考慮了三種不同規模的PaLM和Flan-PaLM模型變體:80億參數、620億參數以及5400億參數。
不過Flan-PaLM仍有一定的局限性,在處理消費者醫學問題上表現效果不佳。
為了解決這個問題,讓Flan-PaLM更適應醫學領域,他們進行了指令提示調整,產生Med-PaLM模型。

△範例:新生兒黃疸需要多久才能消失?
團隊首先從MultiMedQA自由回答資料集(HealthSearchQA、MedicationQA、LiveQA)中隨機抽取了一些範例。
然後讓臨床醫師5人組提供示範性答案。這些臨床醫生分佈於美國和英國,在初級保健、外科、內科和兒科方面具有專業經驗。最後在HealthSearchQA、MedicationQA和LiveQA中留下了40個例子,用於指令提示調諧訓練。

為了驗證Med-PaLM的最終效果,研究人員從上文提到的MultiMedQA中抽取了140個消費者醫療問題。
其中100個來自HealthSearchQA資料集,20個來自LiveQA資料集,20個來自MedicationQA資料集。
值得一提的是,這裡面並不包含當初用於指令提示調整以產生Med-PaLM的問題。
他們讓Flan-PaLM和Med-PaLM分別對這140個問題產生答案,並請來一組專業的臨床醫師回答。
以下圖為例,當被問到「耳朵痛得厲害意味著什麼」時,Med-PaLM不僅會一條列出病人可能感染的疾病,還會建議如果有以下幾種現象應該去就醫。
耳部疼痛可能是幾種潛在疾病的徵兆,包括:中耳感染(中耳炎)、外耳感染(耳部感染)、耳垢嵌塞。也可能是更嚴重疾病的徵兆,例如腦瘤或中風。
如果你有嚴重的耳朵疼痛,持續時間超過幾天,或有其他症狀伴隨耳朵疼痛,如頭暈、發燒、臉部無力或麻木,你應該去看醫生進行評估。醫生可以確定疼痛的原因,並提供適當的治療。
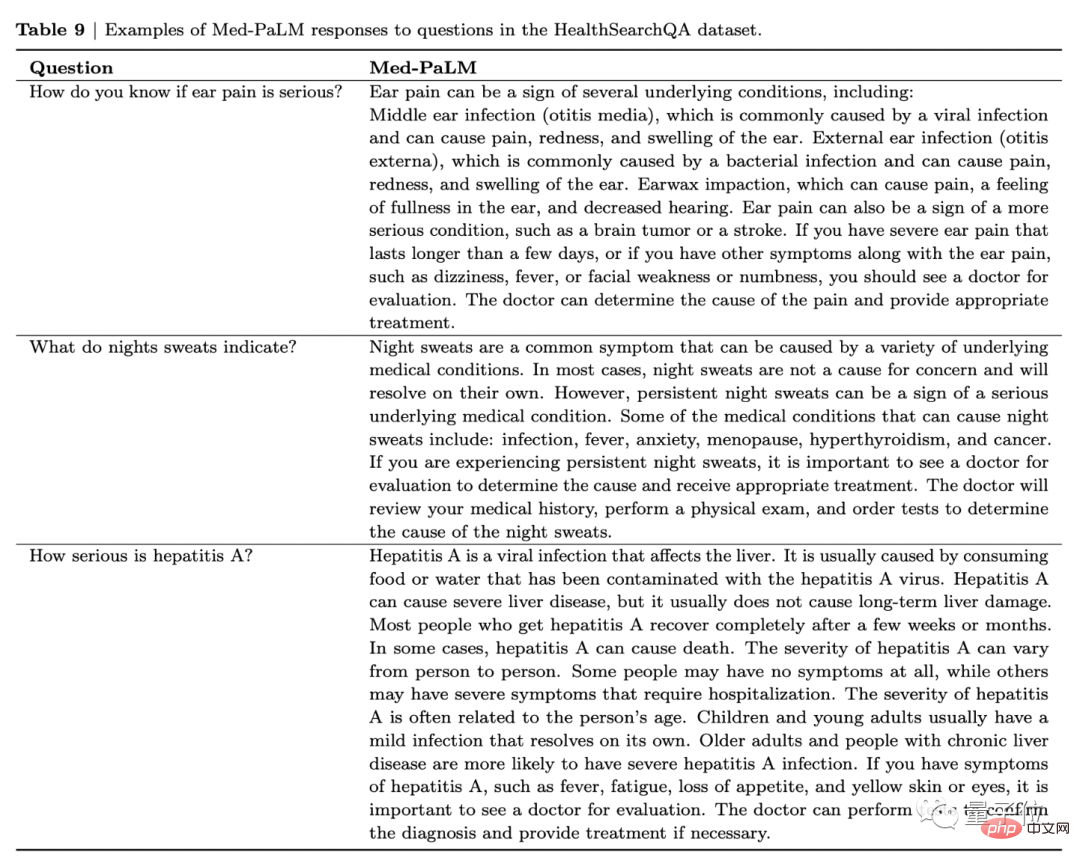
就這樣,研究人員將這三組答案匿名後交給9名分別來自美國、英國和印度的臨床醫生進行評估。
結果顯示,在科學常識方面,Med-PaLM和人類醫師的正確率都達到了92%以上,而Flan-PaLM對應的數字為61.9%。

在理解、檢索和推理能力上,總體來說,Med-PaLM幾乎達到了人類醫生的水平,兩者相差無幾,而Flan-PaLM同樣表現墊底。

在答案的完整性上,雖然Flan-PaLM的回答被認為漏掉了47.2%的重要訊息,但Med-PaLM的回答有顯著提升,只有15.1%的回答被認為缺失了訊息,進一步拉近了與人類醫生的距離。

不過,儘管遺漏資訊較少,但較長的答案也意味著會增加引入不正確內容的風險,Med-PaLM的答案中不正確內容比例達到了18.7%,為三者中最高。

再考慮到答案可能產生的危害性,29.7%的Flan-PaLM回答被認為有潛在的危害;Med-PaLM的這個數字下降到了5.9%,人類醫生相對最低為5.7%。

除此之外,在醫學人口統計的偏見上,Med-PaLM的表現超過了人類醫生,Med-PaLM的答案中存在偏見的情況僅有0.8%,相較之下,人類醫師為1.4%,Flan-PaLM為7.9% 。

最後,研究人員也邀請了5位非專業用戶,來評估這三組答案的實用性。 Flan-PaLM的答案只有60.6%被認為有幫助,Med-PaLM的數量增加到了80.3%,人類醫生最高為91.1%。

總結上述所有評估可以看出,指示提示調整對效能的提升效果顯著,在140個消費者醫療議題中,Med-PaLM的表現幾乎追上了人類醫生水平。
本次論文的研究團隊來自Google和DeepMind。

在去年谷歌健康被曝大規模裁員重組後,這可以說是他們在醫療領域推出一大力作。
連GoogleAI負責人Jeff Dean都出來站台,表示強烈推薦!

有業內人士看完後也稱讚道:
臨床知識是一個複雜的領域,往往沒有一個明顯的正確答案,而且還需要與病人對話。
這次GoogleDeepMind的新模型堪稱LLM的完美應用。

值得一提的是,前段時間剛通過了美國醫師執照考試另一個團隊。
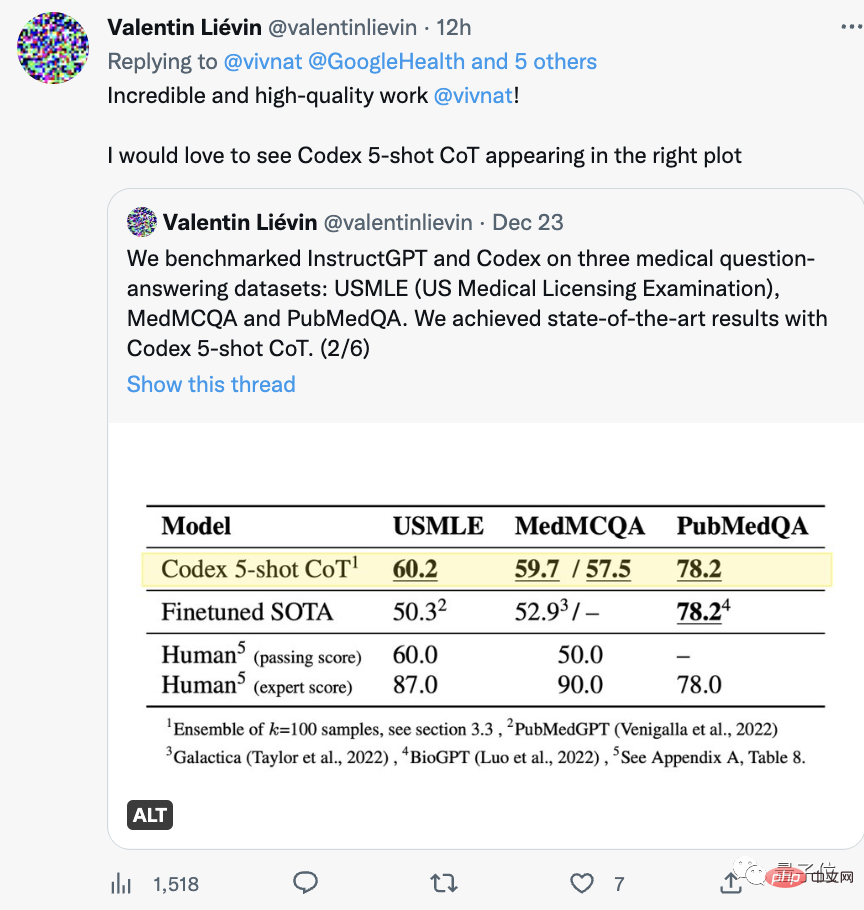
再往前數,今年湧現的PubMed GPT、DRAGON、Meta的Galactica等等一波大模型,屢屢在專業考試上創下新的記錄。

醫療AI如此盛況,很難想像去年還一度唱衰的光景。當時Google與醫療AI相關的創新業務始終沒有做起來。
去年6月還一度被美國媒體BI曝光正陷入重重危機之中,不得不大規模裁員重組。而2018年11月谷歌健康部門剛成立時可謂風光無限。
也不只是谷歌,其他知名科技公司的醫療AI業務,也都曾經歷過重組、收購的情況。
看完這次GoogleDeepMind發布的醫療大模型,你看好醫療AI的發展嗎?
論文網址:https://arxiv.org/abs/2212.13138
參考連結:https://twitter.com/vivnat/status/1607609299894947841
#以上是史上AI最高分!谷歌大模型創美國醫師執照試題新紀錄,科學常識水準媲美人類醫生的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















