
2021 年,微軟、OpenAI、Github 三家聯合打造了一個好用的程式碼補全與建議工具 ——Copilot。
它會在開發者的程式碼編輯器內推薦程式碼行,例如當開發者在Visual Studio Code、Neovim 和JetBrains IDE 等整合開發環境中輸入程式碼時,它就能夠推薦下一行的程式碼。此外,Copilot 甚至可以提供關於完整的方法和複雜的演算法等建議,以及模板程式碼和單元測試的協助。
一年多過去,這項工具已經成為不少程式設計師離不開的「程式夥伴」。前特斯拉人工智慧總監Andrej Karpathy 表示,「Copilot 大大加快了我的程式設計速度,很難想像如何回到『手動程式設計』。目前,我仍在學習如何使用它,它已經編寫了我將近80%的程式碼,準確率也接近80%。」
習慣之餘,我們對於Copilot 也有一些疑問,例如Copilot 的prompt 長什麼樣子?它是如何呼叫模型的?它的推薦成功率是怎麼測出來的?它會收集使用者的程式碼片段發送到自己的伺服器嗎? Copilot 背後的模型是大模型還是小模型?
為了解答這些疑問,來自伊利諾大學香檳分校的一位研究者對 Copilot 進行了粗略的逆向工程,並將觀察結果寫成了部落格。
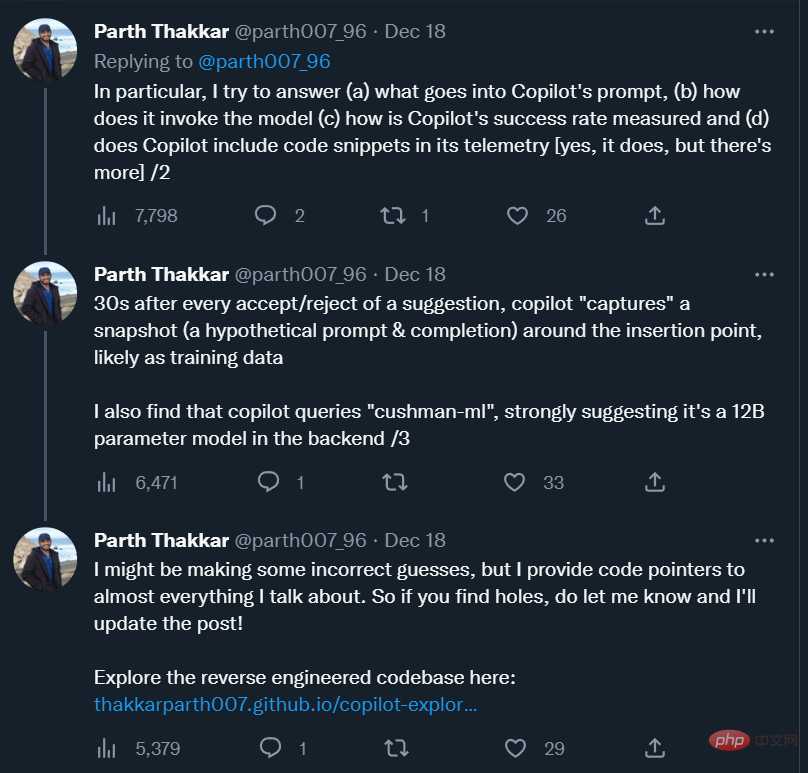
Andrej Karpathy 在自己的推特中推薦了這篇部落格。
以下是部落格原文。
Github Copilot 對我來說非常有用。它經常能神奇地讀懂我的心思,並提出有用的建議。最讓我驚訝的是它能夠從周圍的程式碼(包括其他文件中的程式碼)中正確地“猜測”函數 / 變數。只有當 Copilot 擴展從周圍的程式碼發送有價值的資訊到 Codex 模型時,這一切才會發生。我很好奇它是如何運作的,所以我決定看一看原始碼。
在這篇文章中,我試圖回答有關 Copilot 內部結構的具體問題,同時也描述了我在梳理程式碼時所得到的一些有趣的觀察。
這個專案的程式碼可以在這裡找到:
程式碼位址:https: //github.com/thakkarparth007/copilot-explorer
#整篇文章架構如下:

幾個月前,我對Copilot 擴展進行了非常淺顯的「逆向工程」,從那時起我就一直想要進行更深入的研究。在過去的近幾週時間終於得以抽空來做這件事。大體來講,透過使用Copilot 中包含的extension.js 文件,我進行了一些微小的手動更改以簡化模組的自動提取,並編寫了一堆AST 轉換來「美化」每個模組,將模組進行命名,同時分類並手動註釋出其中一些最有趣的部分。
你可以透過我建立的工具探索逆向工程的 copilot 程式碼庫。它可能不夠全面和精緻,但你仍然可以使用它來探索 Copilot 的程式碼。
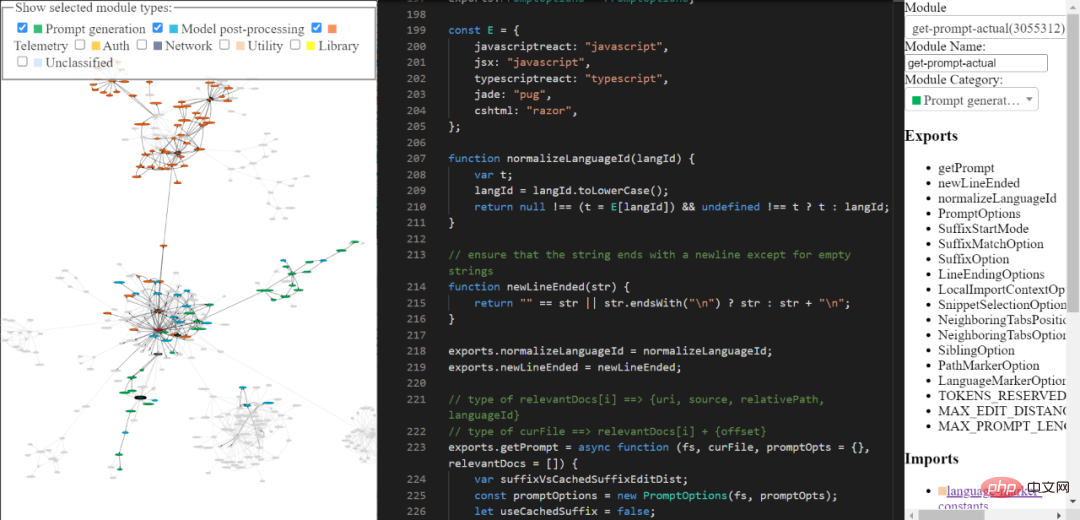
工具連結:https://thakkarparth007.github.io/copilot-explorer/
Github Copilot 由以下兩個主要部分組成:
##
現在,Codex 已經在大量公共Github 程式碼上得到了訓練,因此它能提出有用的建議是合理的。但 Codex 不可能知道你目前專案中存在哪些功能,即便如此,它還是能提出涉及專案功能的建議,它是如何做到的?
讓我們分成兩個部分來對此進行解答:首先讓我們來看看由 copilot 產生的一個真實 prompt 例子,而後我們再來看它是如何產生的。
prompt 長啥樣
#Copilot 擴充功能在 prompt 中編碼了大量與你專案相關的資訊。 Copilot 有一個相當複雜的 prompt 工程 pipeline。如下是一個 prompt 的範例:
{"prefix": "# Path: codeviz\app.pyn# Compare this snippet from codeviz\predictions.py:n# import jsonn# import sysn# import timen# from manifest import Manifestn# n# sys.path.append(__file__ + "/..")n# from common import module_codes, module_deps, module_categories, data_dir, cur_dirn# n# gold_annots = json.loads(open(data_dir / "gold_annotations.js").read().replace("let gold_annotations = ", ""))n# n# M = Manifest(n# client_name = "openai",n# client_connection = open(cur_dir / ".openai-api-key").read().strip(),n# cache_name = "sqlite",n# cache_connection = "codeviz_openai_cache.db",n# engine = "code-davinci-002",n# )n# n# def predict_with_retries(*args, **kwargs):n# for _ in range(5):n# try:n# return M.run(*args, **kwargs)n# except Exception as e:n# if "too many requests" in str(e).lower():n# print("Too many requests, waiting 30 seconds...")n# time.sleep(30)n# continuen# else:n# raise en# raise Exception("Too many retries")n# n# def collect_module_prediction_context(module_id):n# module_exports = module_deps[module_id]["exports"]n# module_exports = [m for m in module_exports if m != "default" and "complex-export" not in m]n# if len(module_exports) == 0:n# module_exports = ""n# else:n# module_exports = "It exports the following symbols: " + ", ".join(module_exports)n# n# # get module snippetn# module_code_snippet = module_codes[module_id]n# # snip to first 50 lines:n# module_code_snippet = module_code_snippet.split("\n")n# if len(module_code_snippet) > 50:n# module_code_snippet = "\n".join(module_code_snippet[:50]) + "\n..."n# else:n# module_code_snippet = "\n".join(module_code_snippet)n# n# return {"exports": module_exports, "snippet": module_code_snippet}n# n# #### Name prediction ####n# n# def _get_prompt_for_module_name_prediction(module_id):n# context = collect_module_prediction_context(module_id)n# module_exports = context["exports"]n# module_code_snippet = context["snippet"]n# n# prompt = f"""\n# Consider the code snippet of an unmodule named.n# nimport jsonnfrom flask import Flask, render_template, request, send_from_directorynfrom common import *nfrom predictions import predict_snippet_description, predict_module_namennapp = Flask(__name__)nn@app.route('/')ndef home():nreturn render_template('code-viz.html')nn@app.route('/data/<path:filename>')ndef get_data_files(filename):nreturn send_from_directory(data_dir, filename)nn@app.route('/api/describe_snippet', methods=['POST'])ndef describe_snippet():nmodule_id = request.json['module_id']nmodule_name = request.json['module_name']nsnippet = request.json['snippet']ndescription = predict_snippet_description(nmodule_id,nmodule_name,nsnippet,n)nreturn json.dumps({'description': description})nn# predict name of a module given its idn@app.route('/api/predict_module_name', methods=['POST'])ndef suggest_module_name():nmodule_id = request.json['module_id']nmodule_name = predict_module_name(module_id)n","suffix": "if __name__ == '__main__':rnapp.run(debug=True)","isFimEnabled": true,"promptElementRanges": [{ "kind": "PathMarker", "start": 0, "end": 23 },{ "kind": "SimilarFile", "start": 23, "end": 2219 },{ "kind": "BeforeCursor", "start": 2219, "end": 3142 }]}#如你所見,上述 prompt 包括一個前綴和一個後綴。 Copilot 隨後會將此 prompt(在經過一些格式化後)發送給模型。在這種情況下,因為後綴是非空的,Copilot 將以 “插入模式”,也就是 fill-in-middle (FIM) 模式來呼叫 Codex。
如果你查看前綴,你將會看到它包含專案中另一個檔案的一些程式碼。參見 # Compare this snippet from codeviz\predictions.py: 程式碼行及其之後的數行
prompt 是如何準備的?
Roughly, the following sequence of steps are executed to generate the prompt:
一般來說,prompt 透過以下一系列步驟逐步產生:
1. 入口點:prompt 擷取發生在給定的文件和遊標位置。其產生的主要入口點是 extractPrompt (ctx, doc, insertPos)
#2. 從 VSCode 查詢文件的相對路徑和語言 ID。請參閱:getPromptForRegularDoc (ctx, doc, insertPos)
3. 相關文件:而後,從 VSCode 中查詢最近存取的 20 個相同語言的檔案。請參閱 getPromptHelper (ctx, docText, insertOffset, docRelPath, docUri, docLangId) 。這些檔案後續會用於提取將要包含在 prompt 中的類似片段。我個人認為用同一種語言作為過濾器很奇怪,因為多語言開發是相當常見的。不過我猜想這仍然能涵蓋大多數情況。
4. 設定:接下來,設定一些選項。具體包括:
5. 前綴計算:現在,建立一個「Prompt Wishlist」用於計算 prompt 的前綴部分。這裡,我們添加了不同的“元素”及其優先順序。例如,一個元素可以類似於“比較這個來自 中的片段”,或本地導入的上下文,或每個文件的語言 ID 及和 / 或路徑。這一切都發生在 getPrompt (fs, curFile, promptOpts = {}, relevantDocs = []) 。
6. 後綴計算:上一步是針對前綴的,但後綴的邏輯相對簡單—— 只需用來自於遊標的任意可用後綴填充token budget 即可。這是預設設置,但後綴的起始位置會根據 SuffixStartMode 選項略有不同, 這也是由 AB 實驗框架控制的。例如,如果 SuffixStartMode 是 SiblingBlock,則 Copilot 將首先找到與正在編輯的函數同級的功能最相近的函數,並從那裡開始編寫後綴。
仔細觀察片段提取
#對我來說,prompt 生成最完整的部分似乎是從其他文件中提取片段。它在此處被呼叫並被 neighbor-snippet-selector.getNeighbourSnippets 所定義。根據選項,這將會使用“Fixed window Jaccard matcher”或“Indentation based Jaccard Matcher”。我難以百分之百確定,但看起來其實並沒有使用 Indentation based Jaccard Matcher。
預設情況下,我們使用 fixed window Jaccard Matcher。在這種情況下,將給定檔案(會從中提取片段的檔案)分割成固定大小的滑動視窗。然後計算每個視窗和參考文件(你正在輸入的文件)之間的 Jaccard 相似度。每個「相關文件」僅傳回最優視窗(儘管有需返回前 K 個片段的規定,但從未遵守)。預設情況下,FixedWindowJaccardMatcher 會被用於「Eager 模式」(即視窗大小為 60 行)。但是,該模式由 AB Experimentation framework 控制,因此我們可能會使用其他模式。
Copilot 透過兩個 UI 提供補全:Inline/GhostText 和 Copilot Panel。在這兩種情況下,模型的呼叫方式存在一些差異。
Inline/GhostText
#主模組:https://thakkarparth007.github.io/copilot-explorer/ codeviz/templates/code-viz.html#m9334&pos=301:14
在其中,Copilot 擴充要求模型提供非常少的建議(1-3 條) 以提速。它也積極緩存模型的結果。此外,如果使用者繼續輸入,它會負責調整建議。如果使用者打字速度很快,它也會要求模型開啟函數防抖動功能(debouncing)。
這個 UI 也設定了一些邏輯來防止在某些情況下發送請求。例如,若使用者遊標在一行的中間,那麼僅當其右側的字元是空格、右大括號等時才會傳送請求。
1、透過上下文過濾器(Contextual Filter)阻止不良請求
更有趣的是,在生成 prompt 後,該模組會檢查 prompt 是否「足夠好」,以便調用模型, 這是透過計算「上下文過濾分數」來實現的。這個分數似乎是基於一個簡單的logistic 迴歸模型,它包含11 個特徵,例如語言、先前的建議是否被接受/ 拒絕、先前接受/ 拒絕之間的持續時間、prompt 中最後一行的長度、遊標前的最後一個字元等。此模型權重包含在擴充程式碼自身。
如果分數低於閾值(預設 15% ),則不會發出請求。探索這個模型會很有趣,我觀察到有些語言比其他語言有更高的權重(例如 php > js > python > rust > dart…php)。另一個直觀的觀察是,如果prompt 以) 或] 結尾,則分數低於以( 或[ 結尾的情況。這是有道理的,因為前者更可能表明早已“完成”,而後者清楚地表明用戶將從自動補全中受益。
Copilot Panel
#主要模組:https://thakkarparth007.github. io/copilot-explorer/codeviz/templates/code-viz.html#m2990&pos=12:1
Core logic 1:https://thakkarparth007.github.io/copilot-explorer /codeviz/templates/code-viz.html#m893&pos=9:1
Core logic 2:https://thakkarparth007.github.io/copilot-explorer/codeviz/templates/ code-viz.html#m2388&pos=67:1
#與Inline UI 相比,此UI 會從模型中要求更多樣本(預設為10 個)。這個UI似乎沒有上下文過濾邏輯(有道理,如果用戶明確調用它,你不會想不prompt 該模型)。
這裡主要有兩件有趣的事情:
不顯示無用的補全建議:
在(透過任一UI)顯示建議之前,Copilot 執行兩個檢查:
##如果輸出是重複的(如:foo = foo = foo = foo...),這是語言模型的常見失敗模式,那麼這個建議會被丟棄。這在Copilot proxy server 或客戶端都有可能發生。
如果使用者已經打出了該建議,該建議也會被丟棄。
秘訣3:telemetryGithub 在先前的部落格中聲稱,程式設計師所寫的程式碼中有40% 是由Copilot 寫的(適用於Python等流行語言)。我很好奇他們是如何測出這個數字的,所以想在 telemetry 程式碼中插入一些內容。
我還想知道它收集了哪些 telemetry 數據,尤其是是否收集了程式碼片段。我想知道這一點,因為雖然我們可以輕鬆地將Copilot 擴展指向開源FauxPilot 後端而不是Github 後端,該擴展可能仍然會透過telemetry 發送程式碼片段到Github,讓一些對程式碼隱私有疑慮的人放棄使用Copilot。我想知道情況是不是這樣。
問題一:40% 的數字是如何測量的?
衡量 Copilot 的成功率不僅僅是簡單地計算接受數 / 拒絕數的問題,因為人們通常都會接受推薦並進行一些修改。因此,Github 的工作人員會檢查被接受的建議是否仍存在於程式碼中。具體來說,他們會在建議代碼插入之後的 15 秒、30 秒、2 分鐘、5 分鐘、10 分鐘進行檢查。
現在,對已接受的建議進行精確搜尋過於嚴格,因此他們會測量建議的文字和插入點周圍的視窗之間的編輯距離(在字元級別和單字級別)。如果插入和視窗之間的「單字」級編輯距離小於 50%(歸一化為建議大小),則該建議被視為「仍在程式碼中」。
當然,這一切只針對已接受程式碼。
問題二:telemetry 資料包含程式碼片段嗎?
是的,包含。
在接受或拒絕建議 30 秒後,copilot 會在插入點附近「捕獲」一份快照。具體來說,該擴充功能會呼叫 prompt extraction 機制來收集一份「假設 prompt」,該 prompt 可以用於在該插入點提出建議。 copilot 也透過捕捉插入點和所「猜測」的終結點之間的程式碼來捕捉「假設 completion」。我不太明白它是怎麼猜測這個端點的。如前所述,這發生在接受或拒絕之後。
我懷疑這些快照可能會被用作進一步改進模型的訓練資料。然而,對於假設程式碼是否「穩定下來」,30 秒似乎太短了。但我猜,考慮到 telemetry 包含與使用者專案對應的 github repo,即使 30 秒的時間內會產生嘈雜的資料點,GitHub 的工作人員也可以離線清理這些相對嘈雜的資料。當然,所有這些都只是我的猜測。
注意,GitHub 會讓你選擇是否同意用你的程式碼片段「改進產品」,如果你不同意,包含這些片段的telemetry 就不會被送到伺服器上(至少在我檢查的v1.57 中是這樣,但我也驗證了v1.65)。在它們通過網路發送之前,我會透過查看代碼和記錄 telemetry 數據點來檢查這一點。
我稍微修改了擴充程式碼以啟用 verbose logging(找不到可設定的參數)。我發現這個模型叫做“cushman-ml”,這強烈暗示了 Copilot 使用的可能是 12B 參數模型而不是 175B 參數模型。對於開源工作者來說,這是非常令人鼓舞的,這意味著一個中等大小的模型可以提供如此優秀的建議。當然,Github 所擁有的巨量資料對於開源工作者來說仍然難以取得。
在本文中,我沒有介紹隨擴充功能一起發布的 worker.js 檔案。乍一看,它似乎基本上只提供了 prompt-extraction logic 的平行版本,但它可能還有更多的功能。
檔案位址:https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/worker_expanded.js
#啟用verbose logging
#如果你想啟用verbose logging,你可以透過修改擴充功能來實現:
如果你想要現成的patch,只需複製擴充程式碼:https://thakkarparth007.github.io/copilot-explorer/muse/github.copilot-1.57.7193/dist/extension.js
注意,這是針對1.57 .7193 版本的。
原文中有更多細節鏈接,有興趣的讀者可以查看原文。
#以上是在對Copilot進行逆向工程之後,我發現它可能只用了參數量12B的小模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















