

Java分散式之Kafka訊息佇列實例分析

介紹
Apache Kafka 是分散式發布-訂閱訊息系統,在 kafka官網上對 kafka 的定義:一個分散式發布-訂閱訊息傳遞系統。它最初由LinkedIn公司開發,Linkedin於2010年貢獻給了Apache基金會並成為頂級開源專案。 Kafka是一種快速、可擴展的、設計內在就是分散式的,分區的和可複製的提交日誌服務。
注意:Kafka並沒有遵循JMS規範(),它只提供了發布和訂閱通訊方式。
Kafka核心相關名稱
Broker:Kafka節點,一個Kafka節點就是一個broker,多個broker可以組成一個Kafka叢集
-
#Topic:一類訊息,訊息存放的目錄即主題,例如page view日誌、click日誌等都可以以topic的形式存在,Kafka叢集能夠同時負責多個topic的分發
#massage: Kafka中最基本的傳遞物件。
Partition:topic物理上的分組,一個topic可以分成多個partition,每個partition是一個有序的佇列。 Kafka裡面實作分區,一個broker就是表示一個區域。
Segment:partition物理上由多個segment組成,每個Segment存message資訊
Producer : 生產者,生產message發送到topic
Consumer : 消費者,訂閱topic並消費message, consumer作為一個執行緒來消費
Consumer Group:消費者群組,一個Consumer Group包含多個consumer
Offset:偏移量,理解為訊息partition 中訊息的索引位置
主題和佇列的區別:
佇列是一個資料結構,遵循先進先出原則
kafka叢集安裝
每台伺服器上安裝jdk1.8環境
安裝Zookeeper叢集環境
安裝kafka叢集環境
執行環境測試
安裝jdk環境和zookeeper這裡不詳述了。
kafka為什麼依賴zookeeper:kafka會將mq資訊存放在zookeeper上,為了讓整個叢集能夠方便擴展,採用zookeeper的事件通知相互感知。
kafka叢集安裝步驟:
1、下載kafka的壓縮套件
2、解壓縮安裝套件
##tar -zxvf kafka_2.11 -1.0.0.tgz3、修改kafka的設定檔config/server.properties設定檔修改內容:
- zookeeper連線位址:
zookeeper.connect=192.168.1.19:2181
- 監聽的ip,修改為本機的ip
listeners=PLAINTEXT:// 192.168.1.19:9092
- kafka的brokerid,每台broker的id都不一樣
broker.id=0
./kafka-server-start.sh -daemon config/server.properties
#./kafka-topics.sh --create --zookeeper localhost: 2181 --replication-factor 1 --partitions 3 --topic kaico
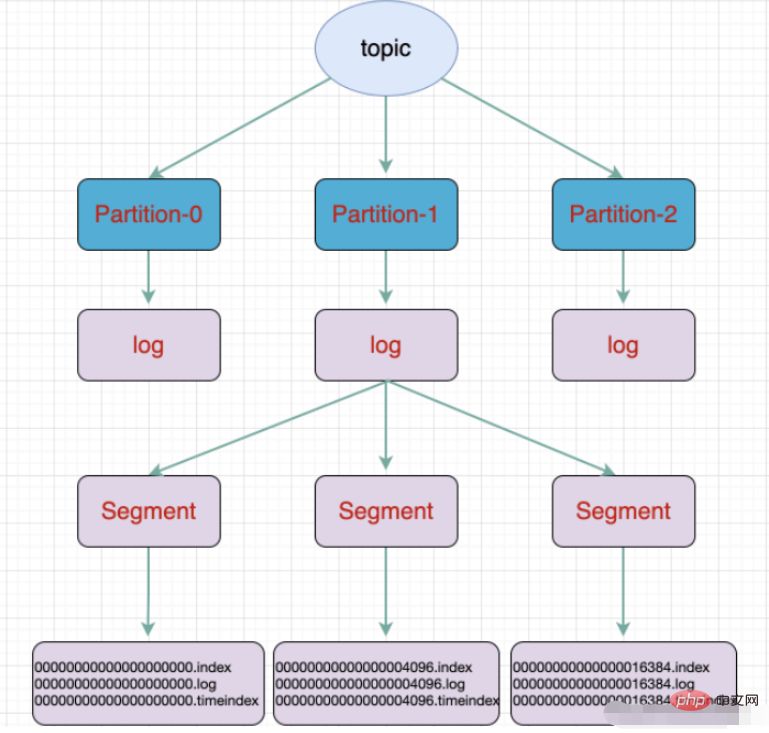
- 一個partition分為多個segment
- .log 日誌檔
- #.index 偏移量索引檔
- .timeindex 時間戳索引檔
- 其他檔案(partition.metadata,leader-epoch-checkpoint)
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies># kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}以上是Java分散式之Kafka訊息佇列實例分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 作曲家:通過AI的幫助開發PHP
Apr 29, 2025 am 12:27 AM
作曲家:通過AI的幫助開發PHP
Apr 29, 2025 am 12:27 AM
AI可以幫助優化Composer的使用,具體方法包括:1.依賴管理優化:AI分析依賴關係,建議最佳版本組合,減少衝突。 2.自動化代碼生成:AI生成符合最佳實踐的composer.json文件。 3.代碼質量提升:AI檢測潛在問題,提供優化建議,提高代碼質量。這些方法通過機器學習和自然語言處理技術實現,幫助開發者提高效率和代碼質量。
 H5:HTML5的關鍵改進
Apr 28, 2025 am 12:26 AM
H5:HTML5的關鍵改進
Apr 28, 2025 am 12:26 AM
HTML5帶來了五個關鍵改進:1.語義化標籤提升了代碼清晰度和SEO效果;2.多媒體支持簡化了視頻和音頻嵌入;3.表單增強簡化了驗證;4.離線與本地存儲提高了用戶體驗;5.畫布與圖形功能增強了網頁的可視化效果。
 如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
MySQL函數可用於數據處理和計算。 1.基本用法包括字符串處理、日期計算和數學運算。 2.高級用法涉及結合多個函數實現複雜操作。 3.性能優化需避免在WHERE子句中使用函數,並使用GROUPBY和臨時表。
 討論可能需要在Java中編寫平台特定代碼的情況。
Apr 25, 2025 am 12:22 AM
討論可能需要在Java中編寫平台特定代碼的情況。
Apr 25, 2025 am 12:22 AM
在Java中編寫平台特定代碼的原因包括訪問特定操作系統功能、與特定硬件交互和優化性能。 1)使用JNA或JNI訪問Windows註冊表;2)通過JNI與Linux特定硬件驅動程序交互;3)通過JNI使用Metal優化macOS上的遊戲性能。儘管如此,編寫平台特定代碼會影響代碼的可移植性、增加複雜性、可能帶來性能開銷和安全風險。
 怎樣在C 中使用type traits?
Apr 28, 2025 pm 08:18 PM
怎樣在C 中使用type traits?
Apr 28, 2025 pm 08:18 PM
typetraits在C 中用於編譯時類型檢查和操作,提升代碼的靈活性和類型安全性。 1)通過std::is_integral和std::is_floating_point等進行類型判斷,實現高效的類型檢查和輸出。 2)使用std::is_trivially_copyable優化vector拷貝,根據類型選擇不同的拷貝策略。 3)注意編譯時決策、類型安全、性能優化和代碼複雜性,合理使用typetraits可以大大提升代碼質量。
 MySQL的字符集和排序規則如何配置
Apr 29, 2025 pm 04:06 PM
MySQL的字符集和排序規則如何配置
Apr 29, 2025 pm 04:06 PM
在MySQL中配置字符集和排序規則的方法包括:1.設置服務器級別的字符集和排序規則:SETNAMES'utf8';SETCHARACTERSETutf8;SETCOLLATION_CONNECTION='utf8_general_ci';2.創建使用特定字符集和排序規則的數據庫:CREATEDATABASEexample_dbCHARACTERSETutf8COLLATEutf8_general_ci;3.創建表時指定字符集和排序規則:CREATETABLEexample_table(idINT
 如何在MySQL中重命名數據庫
Apr 29, 2025 pm 04:00 PM
如何在MySQL中重命名數據庫
Apr 29, 2025 pm 04:00 PM
MySQL中重命名數據庫需要通過間接方法實現。步驟如下:1.創建新數據庫;2.使用mysqldump導出舊數據庫;3.將數據導入新數據庫;4.刪除舊數據庫。
 如何在C 中實現單例模式?
Apr 28, 2025 pm 10:03 PM
如何在C 中實現單例模式?
Apr 28, 2025 pm 10:03 PM
在C 中實現單例模式可以通過靜態成員變量和靜態成員函數來確保類只有一個實例。具體步驟包括:1.使用私有構造函數和刪除拷貝構造函數及賦值操作符,防止外部直接實例化。 2.通過靜態方法getInstance提供全局訪問點,確保只創建一個實例。 3.為了線程安全,可以使用雙重檢查鎖定模式。 4.使用智能指針如std::shared_ptr來避免內存洩漏。 5.對於高性能需求,可以使用靜態局部變量實現。需要注意的是,單例模式可能導致全局狀態的濫用,建議謹慎使用並考慮替代方案。
