
ThreadLocal 提供了一種方式,讓在多執行緒環境下,每個執行緒都可以擁有自己獨特的數據,並且可以在整個執行緒執行過程中,從上而下的傳遞。
可能很多同學沒有使用過ThreadLocal,我們先來示範下ThreadLocal 的用法,demo 如下:
/**
* ThreadLocal 中保存的数据是 Map
*/
static final ThreadLocal<Map<String, String>> context = new ThreadLocal<>();
@Test
public void testThread() {
// 从上下文中拿出 Map
Map<String, String> contextMap = context.get();
if (CollectionUtils.isEmpty(contextMap)) {
contextMap = Maps.newHashMap();
}
contextMap.put("key1", "value1");
context.set(contextMap);
log.info("key1,value1被放到上下文中");
// 从上下文中拿出刚才放进去的数据
getFromComtext();
}
private String getFromComtext() {
String value1 = context.get().get("key1");
log.info("从 ThreadLocal 中取出上下文,key1 对应的值为:{}", value1);
return value1;
}
//运行结果:
demo.ninth.ThreadLocalDemo - key1,value1被放到上下文中
demo.ninth.ThreadLocalDemo - 从 ThreadLocal 中取出上下文,key1 对应的值为:value1從運行結果可以看到,key1 對應的值已經從上下文拿到了。
getFromComtext 方法是沒有接受任何入參的,透過context.get().get(“key1”) 這行程式碼就從上下文中拿到了key1 的值,接下來我們一起來看下ThreadLocal底層是如何實現上下文的傳遞的。
ThreadLocal 定義類別時帶有泛型,說明ThreadLocal 可以儲存任意格式的數據,原始碼如下:
public class ThreadLocal<T> {}ThreadLocal 有幾個關鍵屬性,我們一一看:
// threadLocalHashCode 表示当前 ThreadLocal 的 hashCode,用于计算当前 ThreadLocal 在 ThreadLocalMap 中的索引位置
private final int threadLocalHashCode = nextHashCode();
// 计算 ThreadLocal 的 hashCode 值(就是递增)
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
// static + AtomicInteger 保证了在一台机器中每个 ThreadLocal 的 threadLocalHashCode 是唯一的
// 被 static 修饰非常关键,因为一个线程在处理业务的过程中,ThreadLocalMap 是会被 set 多个 ThreadLocal 的,多个 ThreadLocal 就依靠 threadLocalHashCode 进行区分
private static AtomicInteger nextHashCode = new AtomicInteger();還有一個重要屬性:ThreadLocalMap,當一個執行緒有多個ThreadLocal時,需要一個容器來管理多個ThreadLocal,ThreadLocalMap 的功能就是這個,管理線程中多個ThreadLocal。
ThreadLocalMap 本身就是一個簡單的Map 結構,key 是ThreadLocal,value 是ThreadLocal 儲存的值,底層是陣列的資料結構,原始碼如下:
// threadLocalHashCode 表示当前 ThreadLocal 的 hashCode,用于计算当前 ThreadLocal 在 ThreadLocalMap 中的索引位置
private final int threadLocalHashCode = nextHashCode();
// 计算 ThreadLocal 的 hashCode 值(就是递增)
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
// static + AtomicInteger 保证了在一台机器中每个 ThreadLocal 的 threadLocalHashCode 是唯一的
// 被 static 修饰非常关键,因为一个线程在处理业务的过程中,ThreadLocalMap 是会被 set 多个 ThreadLocal 的,多个 ThreadLocal 就依靠 threadLocalHashCode 进行区分
private static AtomicInteger nextHashCode = new AtomicInteger();從原始碼看到ThreadLocalMap 其實就是一個簡單的Map 結構,底層是數組,有初始化大小,也有擴容閾值大小,數組的元素是Entry,Entry 的key 就是ThreadLocal 的引用,value 是ThreadLocal 的值。
ThreadLocal 是線程安全的,我們可以放心使用,主要因為是ThreadLocalMap 是線程的屬性,我們看下線程Thread的原始碼,如下:
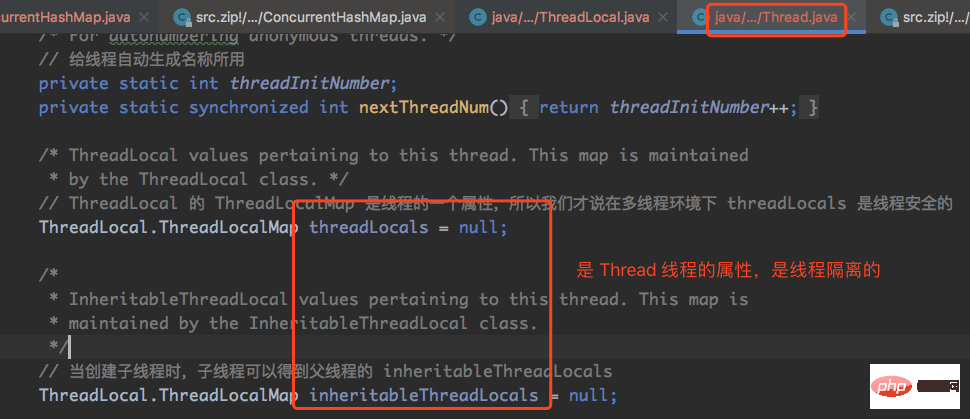
從上圖中,我們可以看到ThreadLocals.ThreadLocalMap 和InheritableThreadLocals.ThreadLocalMap 分別是執行緒的屬性,所以每個執行緒的ThreadLocals 都是隔離獨享的。
父執行緒在建立子執行緒的情況下,會拷貝inheritableThreadLocals 的值,但不會拷貝threadLocals 的值,原始碼如下:
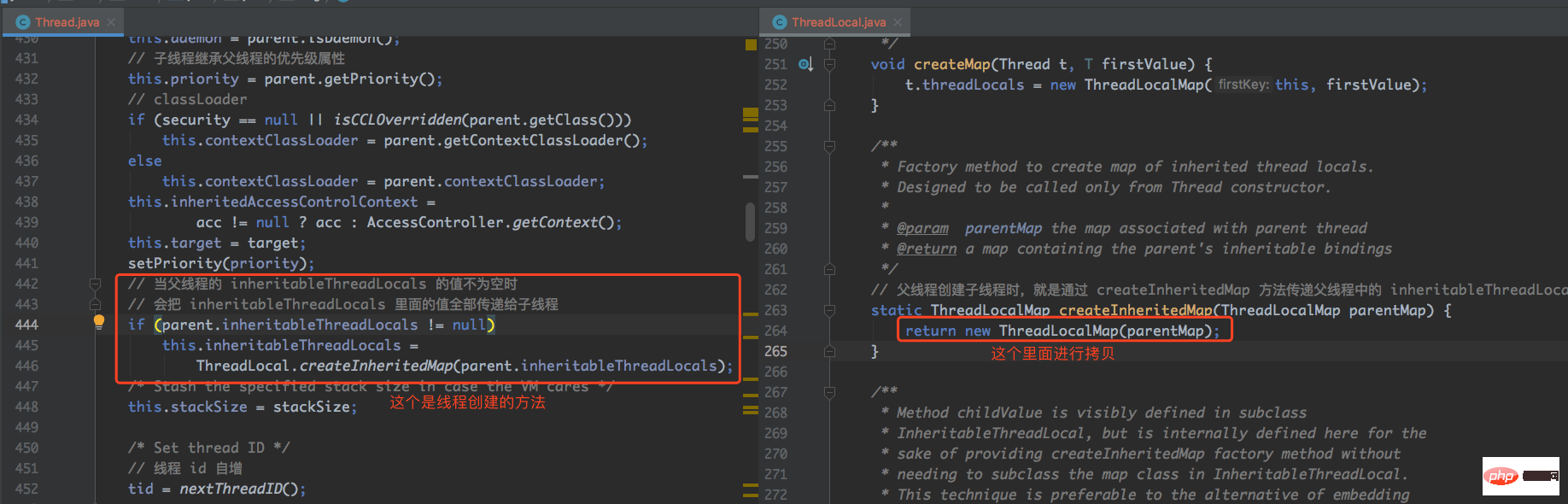
從上圖中我們可以看到,在執行緒建立時,會把父執行緒的inheritableThreadLocals 屬性值進行拷貝。
set 方法的主要功能是往當前ThreadLocal 裡面set 值,假如當前ThreadLocal 的泛型是Map,那麼就是往當前ThreadLocal 裡面set map,原始碼如下:
// set 操作每个线程都是串行的,不会有线程安全的问题
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 当前 thradLocal 之前有设置值,直接设置,否则初始化
if (map != null)
map.set(this, value);
// 初始化ThreadLocalMap
else
createMap(t, value);
}程式碼邏輯比較清晰,我們一起來看下ThreadLocalMap.set 的源碼,如下:
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 计算 key 在数组中的下标,其实就是 ThreadLocal 的 hashCode 和数组大小-1取余
int i = key.threadLocalHashCode & (len-1);
// 整体策略:查看 i 索引位置有没有值,有值的话,索引位置 + 1,直到找到没有值的位置
// 这种解决 hash 冲突的策略,也导致了其在 get 时查找策略有所不同,体现在 getEntryAfterMiss 中
for (Entry e = tab[i];
e != null;
// nextIndex 就是让在不超过数组长度的基础上,把数组的索引位置 + 1
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 找到内存地址一样的 ThreadLocal,直接替换
if (k == key) {
e.value = value;
return;
}
// 当前 key 是 null,说明 ThreadLocal 被清理了,直接替换掉
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 当前 i 位置是无值的,可以被当前 thradLocal 使用
tab[i] = new Entry(key, value);
int sz = ++size;
// 当数组大小大于等于扩容阈值(数组大小的三分之二)时,进行扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}上面源碼我們注意幾點:
#是透過遞增的AtomicInteger 作為ThreadLocal 的hashCode 的;
計算數組索引位置的公式是:hashCode 取模組大小,由於hashCode 不斷自增,所以不同的hashCode大概率上會計算到同一個陣列的索引位置(但這個不用擔心,在實際項目中,ThreadLocal 都很少,基本上不會衝突);
透過hashCode 計算的索引位置i 處如果已經有值了,會從i 開始,通過1 不斷的往後尋找,直到找到索引位置為空的地方,把當前ThreadLocal 作為key 放進去。
好在日常工作中使用 ThreadLocal 時,常常只使用 1~2 個 ThreadLocal,透過 hash 計算出重複的陣列的機率並不是很大。
set 時的解決數組元素位置衝突的策略,也對 get 方法產生了影響,接著我們一起來看 get 方法。
get 方法主要是從ThreadLocalMap 拿到目前ThreadLocal 儲存的值,原始碼如下:
public T get() {
// 因为 threadLocal 属于线程的属性,所以需要先把当前线程拿出来
Thread t = Thread.currentThread();
// 从线程中拿到 ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 从 map 中拿到 entry,由于 ThreadLocalMap 在 set 时的 hash 冲突的策略不同,导致拿的时候逻辑也不太一样
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果不为空,读取当前 ThreadLocal 中保存的值
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 否则给当前线程的 ThreadLocal 初始化,并返回初始值 null
return setInitialValue();
}接著我們來看下ThreadLocalMap 的getEntry 方法,原始碼如下:
// 得到当前 thradLocal 对应的值,值的类型是由 thradLocal 的泛型决定的
// 由于 thradLocalMap set 时解决数组索引位置冲突的逻辑,导致 thradLocalMap get 时的逻辑也是对应的
// 首先尝试根据 hashcode 取模数组大小-1 = 索引位置 i 寻找,找不到的话,自旋把 i+1,直到找到索引位置不为空为止
private Entry getEntry(ThreadLocal<?> key) {
// 计算索引位置:ThreadLocal 的 hashCode 取模数组大小-1
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// e 不为空,并且 e 的 ThreadLocal 的内存地址和 key 相同,直接返回,否则就是没有找到,继续通过 getEntryAfterMiss 方法找
if (e != null && e.get() == key)
return e;
else
// 这个取数据的逻辑,是因为 set 时数组索引位置冲突造成的
return getEntryAfterMiss(key, i, e);
}// 自旋 i+1,直到找到为止
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 在大量使用不同 key 的 ThreadLocal 时,其实还蛮耗性能的
while (e != null) {
ThreadLocal<?> k = e.get();
// 内存地址一样,表示找到了
if (k == key)
return e;
// 删除没用的 key
if (k == null)
expungeStaleEntry(i);
// 继续使索引位置 + 1
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}get 邏輯原始碼中註解已經寫的很清楚了,我們就不重複說了。
ThreadLocalMap 中的ThreadLocal 的數量超過閾值時,ThreadLocalMap 就要開始擴容了,我們一起來看下擴容的邏輯:
//扩容
private void resize() {
// 拿出旧的数组
Entry[] oldTab = table;
int oldLen = oldTab.length;
// 新数组的大小为老数组的两倍
int newLen = oldLen * 2;
// 初始化新数组
Entry[] newTab = new Entry[newLen];
int count = 0;
// 老数组的值拷贝到新数组上
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
// 计算 ThreadLocal 在新数组中的位置
int h = k.threadLocalHashCode & (newLen - 1);
// 如果索引 h 的位置值不为空,往后+1,直到找到值为空的索引位置
while (newTab[h] != null)
h = nextIndex(h, newLen);
// 给新数组赋值
newTab[h] = e;
count++;
}
}
}
// 给新数组初始化下次扩容阈值,为数组长度的三分之二
setThreshold(newLen);
size = count;
table = newTab;
}源碼註解也比較清晰,我們注意到兩點:
擴充後陣列大小是原來陣列的兩倍;
以上是Java程式設計中的ThreadLocal詳解與源碼分析的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















