

linux 頻道是什麼

管道是Linux進程間的一種通訊方式,兩個進程可以透過一個共享記憶體區域來傳遞訊息,並且管道中的資料只能是單向流動的,也就是說只能有固定的寫入進程和讀取進程。目前在任何一個shell中,都可以使用「|」連接兩個指令,shell會將前後兩個行程的輸入輸出用一個管道相連,以便達到進程間通訊的目的。

本教學操作環境:linux7.3系統、Dell G3電腦。
管道是UNIX環境中歷史最悠久的進程間通訊方式。本文主要說明在Linux環境上如何使用管道。
什麼是管道?
管道,英文為pipe。管道是Linux進程間的一種通訊方式,兩個進程可以透過一個共享記憶體區域來傳遞訊息,並且管道中的資料只能是單向流動的,也就是說只能有固定的寫進程和讀取進程。
管道的發明人是道格拉斯.麥克羅伊,這位也是UNIX上早期shell的發明者。當他發明了shell之後,發現系統操作執行指令的時候,常常有需求要將一個程式的輸出交給另一個程式處理,這種操作可以使用輸入輸出重定向加檔搞定,例如:
[zorro@zorro-pc pipe]$ ls -l /etc/ > etc.txt [zorro@zorro-pc pipe]$ wc -l etc.txt 183 etc.txt
但是這樣未免顯得太麻煩了。所以,管道的概念應運而生。目前在任何一個shell中,都可以使用「|」連接兩個指令,shell會將前後兩個行程的輸入輸出用一個管道相連,以便達到進程間通訊的目的:
[zorro@zorro-pc pipe]$ ls -l /etc/ | wc -l 183
對比以上兩種方法,我們也可以理解為,管道本質上就是一個文件,前面的進程以寫方式打開文件,後面的進程以讀取方式打開。這樣前面寫完後面讀,於是就實現了通訊。實際上管道的設計也是遵循UNIX的「一切皆文件」設計原則的,它本質上就是一個文件。 Linux系統直接把管道實作成了一種檔案系統,借助VFS給應用程式提供操作介面。
雖然實作形態上是文件,但是管道本身並不佔用磁碟或其他外部儲存的空間。在Linux的實作上,它佔用的是記憶體空間。所以,Linux上的管道就是一個操作方式為檔案的記憶體緩衝區。
管道的分類和使用
##Linux上的管道分為兩種類型:- 匿名管道
- 命名管道
[zorro@zorro-pc pipe]$ mkfifo pipe [zorro@zorro-pc pipe]$ ls -l pipe prw-r--r-- 1 zorro zorro 0 Jul 14 10:44 pipe
[zorro@zorro-pc pipe]$ echo xxxxxxxxxxxxxx > pipe
[zorro@zorro-pc pipe]$ cat pipe xxxxxxxxxxxxxx
[zorro@zorro-pc pipe]$ cat /proc/filesystems |grep pipefs nodev pipefs
观察完了如何在命令行中使用管道之后,我们再来看看如何在系统编程中使用管道。
PIPE
我们可以把匿名管道和命名管道分别叫做PIPE和FIFO。这主要因为在系统编程中,创建匿名管道的系统调用是pipe(),而创建命名管道的函数是mkfifo()。使用mknod()系统调用并指定文件类型为为S_IFIFO也可以创建一个FIFO。
使用pipe()系统调用可以创建一个匿名管道,这个系统调用的原型为:
#include <unistd.h> int pipe(int pipefd[2]);
这个方法将会创建出两个文件描述符,可以使用pipefd这个数组来引用这两个描述符进行文件操作。pipefd[0]是读方式打开,作为管道的读描述符。pipefd[1]是写方式打开,作为管道的写描述符。从管道写端写入的数据会被内核缓存直到有人从另一端读取为止。我们来看一下如何在一个进程中使用管道,虽然这个例子并没有什么意义:
[zorro@zorro-pc pipe]$ cat pipe.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
if (write(pipefd[1], STRING, strlen(STRING)) < 0) {
perror("write()");
exit(1);
}
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
exit(0);
}这个程序创建了一个管道,并且对管道写了一个字符串之后从管道读取,并打印在标准输出上。用一个图来说明这个程序的状态就是这样的:

一个进程自己给自己发送消息这当然不叫进程间通信,所以实际情况中我们不会在单个进程中使用管道。进程在pipe创建完管道之后,往往都要fork产生子进程,成为如下图表示的样子:
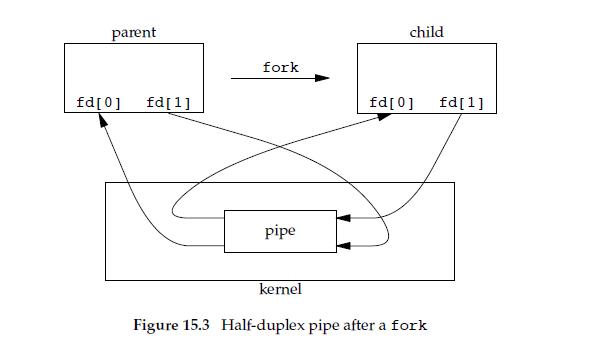
如图中描述,fork产生的子进程会继承父进程对应的文件描述符。利用这个特性,父进程先pipe创建管道之后,子进程也会得到同一个管道的读写文件描述符。从而实现了父子两个进程使用一个管道可以完成半双工通信。此时,父进程可以通过fd[1]给子进程发消息,子进程通过fd[0]读。子进程也可以通过fd[1]给父进程发消息,父进程用fd[0]读。程序实例如下:
[zorro@zorro-pc pipe]$ cat pipe_parent_child.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
bzero(buf, BUFSIZ);
snprintf(buf, BUFSIZ, "Message from child: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
} else {
/* this is parent */
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
sleep(1);
bzero(buf, BUFSIZ);
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
wait(NULL);
}
exit(0);
}父进程先给子进程发一个消息,子进程接收到之后打印消息,之后再给父进程发消息,父进程再打印从子进程接收到的消息。程序执行效果:
[zorro@zorro-pc pipe]$ ./pipe_parent_child Parent pid is: 8309 Child pid is: 8310 Message from parent: My pid is: 8309 Message from child: My pid is: 8310
从这个程序中我们可以看到,管道实际上可以实现一个半双工通信的机制。使用同一个管道的父子进程可以分时给对方发送消息。我们也可以看到对管道读写的一些特点,即:
在管道中没有数据的情况下,对管道的读操作会阻塞,直到管道内有数据为止。当一次写的数据量不超过管道容量的时候,对管道的写操作一般不会阻塞,直接将要写的数据写入管道缓冲区即可。
当然写操作也不会再所有情况下都不阻塞。这里我们要先来了解一下管道的内核实现。上文说过,管道实际上就是内核控制的一个内存缓冲区,既然是缓冲区,就有容量上限。我们把管道一次最多可以缓存的数据量大小叫做PIPESIZE。内核在处理管道数据的时候,底层也要调用类似read和write这样的方法进行数据拷贝,这种内核操作每次可以操作的数据量也是有限的,一般的操作长度为一个page,即默认为4k字节。我们把每次可以操作的数据量长度叫做PIPEBUF。POSIX标准中,对PIPEBUF有长度限制,要求其最小长度不得低于512字节。PIPEBUF的作用是,内核在处理管道的时候,如果每次读写操作的数据长度不大于PIPEBUF时,保证其操作是原子的。而PIPESIZE的影响是,大于其长度的写操作会被阻塞,直到当前管道中的数据被读取为止。
在Linux 2.6.11之前,PIPESIZE和PIPEBUF实际上是一样的。在这之后,Linux重新实现了一个管道缓存,并将它与写操作的PIPEBUF实现成了不同的概念,形成了一个默认长度为65536字节的PIPESIZE,而PIPEBUF只影响相关读写操作的原子性。从Linux 2.6.35之后,在fcntl系统调用方法中实现了F_GETPIPE_SZ和F_SETPIPE_SZ操作,来分别查看当前管道容量和设置管道容量。管道容量容量上限可以在/proc/sys/fs/pipe-max-size进行设置。
#define BUFSIZE 65536
......
ret = fcntl(pipefd[1], F_GETPIPE_SZ);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
printf("PIPESIZE: %d\n", ret);
ret = fcntl(pipefd[1], F_SETPIPE_SZ, BUFSIZE);
if (ret < 0) {
perror("fcntl()");
exit(1);
}
......PIPEBUF和PIPESIZE对管道操作的影响会因为管道描述符是否被设置为非阻塞方式而有行为变化,n为要写入的数据量时具体为:
O_NONBLOCK关闭,n <= PIPE_BUF:
n个字节的写入操作是原子操作,write系统调用可能会因为管道容量(PIPESIZE)没有足够的空间存放n字节长度而阻塞。
O_NONBLOCK打开,n <= PIPE_BUF:
如果有足够的空间存放n字节长度,write调用会立即返回成功,并且对数据进行写操作。空间不够则立即报错返回,并且errno被设置为EAGAIN。
O_NONBLOCK关闭,n > PIPE_BUF:
对n字节的写入操作不保证是原子的,就是说这次写入操作的数据可能会跟其他进程写这个管道的数据进行交叉。当管道容量长度低于要写的数据长度的时候write操作会被阻塞。
O_NONBLOCK打开,n > PIPE_BUF:
如果管道空间已满。write调用报错返回并且errno被设置为EAGAIN。如果没满,则可能会写入从1到n个字节长度,这取决于当前管道的剩余空间长度,并且这些数据可能跟别的进程的数据有交叉。
以上是在使用半双工管道的时候要注意的事情,因为在这种情况下,管道的两端都可能有多个进程进行读写处理。如果再加上线程,则事情可能变得更复杂。实际上,我们在使用管道的时候,并不推荐这样来用。管道推荐的使用方法是其单工模式:即只有两个进程通信,一个进程只写管道,另一个进程只读管道。实现为:
[zorro@zorro-pc pipe]$ cat pipe_parent_child2.c
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
#define STRING "hello world!"
int main()
{
int pipefd[2];
pid_t pid;
char buf[BUFSIZ];
if (pipe(pipefd) == -1) {
perror("pipe()");
exit(1);
}
pid = fork();
if (pid == -1) {
perror("fork()");
exit(1);
}
if (pid == 0) {
/* this is child. */
close(pipefd[1]);
printf("Child pid is: %d\n", getpid());
if (read(pipefd[0], buf, BUFSIZ) < 0) {
perror("write()");
exit(1);
}
printf("%s\n", buf);
} else {
/* this is parent */
close(pipefd[0]);
printf("Parent pid is: %d\n", getpid());
snprintf(buf, BUFSIZ, "Message from parent: My pid is: %d", getpid());
if (write(pipefd[1], buf, strlen(buf)) < 0) {
perror("write()");
exit(1);
}
wait(NULL);
}
exit(0);
}这个程序实际上比上一个要简单,父进程关闭管道的读端,只写管道。子进程关闭管道的写端,只读管道。整个管道的打开效果最后成为下图所示:
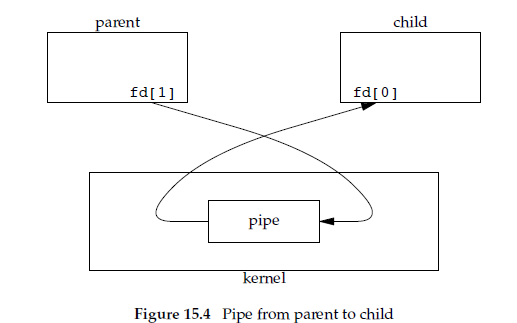
此时两个进程就只用管道实现了一个单工通信,并且这种状态下不用考虑多个进程同时对管道写产生的数据交叉的问题,这是最经典的管道打开方式,也是我们推荐的管道使用方式。另外,作为一个程序员,即使我们了解了Linux管道的实现,我们的代码也不能依赖其特性,所以处理管道时该越界判断还是要判断,该错误检查还是要检查,这样代码才能更健壮。
FIFO
命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用。再程序中创建一个命名管道文件的方法有两种,一种是使用mkfifo函数。另一种是使用mknod系统调用,例子如下:
[zorro@zorro-pc pipe]$ cat mymkfifo.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
if (argc != 2) {
fprintf(stderr, "Argument error!\n");
exit(1);
}
/*
if (mkfifo(argv[1], 0600) < 0) {
perror("mkfifo()");
exit(1);
}
*/
if (mknod(argv[1], 0600|S_IFIFO, 0) < 0) {
perror("mknod()");
exit(1);
}
exit(0);
}我们使用第一个参数作为创建的文件路径。创建完之后,其他进程就可以使用open()、read()、write()标准文件操作等方法进行使用了。其余所有的操作跟匿名管道使用类似。需要注意的是,无论命名还是匿名管道,它的文件描述都没有偏移量的概念,所以不能用lseek进行偏移量调整。
相关推荐:《Linux视频教程》
以上是linux 頻道是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 vscode上一步下一步快捷鍵
Apr 15, 2025 pm 10:51 PM
vscode上一步下一步快捷鍵
Apr 15, 2025 pm 10:51 PM
VS Code 一步/下一步快捷鍵的使用方法:一步(向後):Windows/Linux:Ctrl ←;macOS:Cmd ←下一步(向前):Windows/Linux:Ctrl →;macOS:Cmd →
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
在 Sublime 中運行代碼的方法有六種:通過熱鍵、菜單、構建系統、命令行、設置默認構建系統和自定義構建命令,並可通過右鍵單擊項目/文件運行單個文件/項目,構建系統可用性取決於 Sublime Text 的安裝情況。
 Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要用途包括:1.服務器操作系統,2.嵌入式系統,3.桌面操作系統,4.開發和測試環境。 Linux在這些領域表現出色,提供了穩定性、安全性和高效的開發工具。
 laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
要安裝 Laravel,需依序進行以下步驟:安裝 Composer(適用於 macOS/Linux 和 Windows)安裝 Laravel 安裝器創建新項目啟動服務訪問應用程序(網址:http://127.0.0.1:8000)設置數據庫連接(如果需要)

