
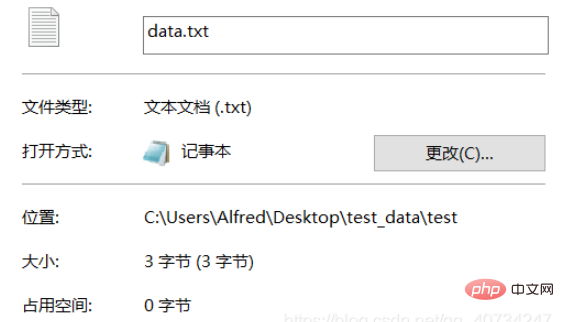
註:測試文字採用UTF-8編碼,通常漢字是佔三個位元組。 GBK中漢字通常是佔2個位元組。
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号控制台輸出 這個函數執行的輸出沒有什麼意義,只是我要知道它執行了沒,所以列印的。

測試資料夾 data1.txt是轉換編碼後的文字。
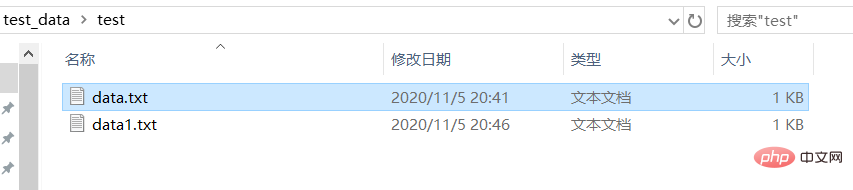
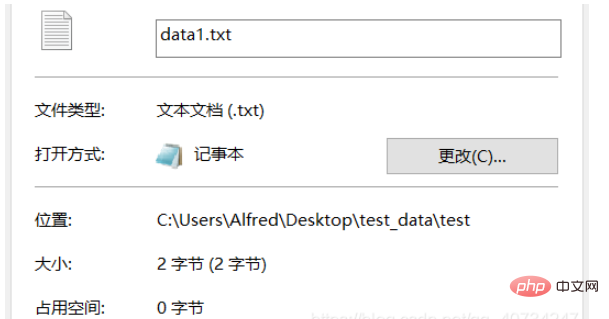
從產生的檔案來看,因為只含有一個字,所以只比較大小就知道是否轉換成功了。當然了,直接打開查看也是可以的,但是直接打開查看的話,沒有什麼效果,都會顯示一個漢字龍。所以,這裡我們另闢蹊徑,使用不一樣的檢視方式!
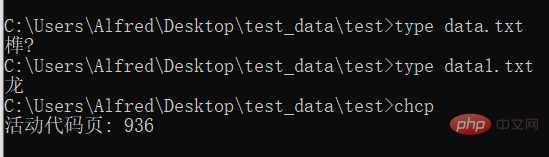
注意:data.txt是採用的UTF-8編碼的,而data1.txt是採用的GBK編碼的。因為國內使用的Windows預設採用的中國的編碼方式,所以它顯示不了UTF-8編碼的文字。第三個輸出是查看目前使用的編碼,它回傳的是編碼的代號,詳見下圖:
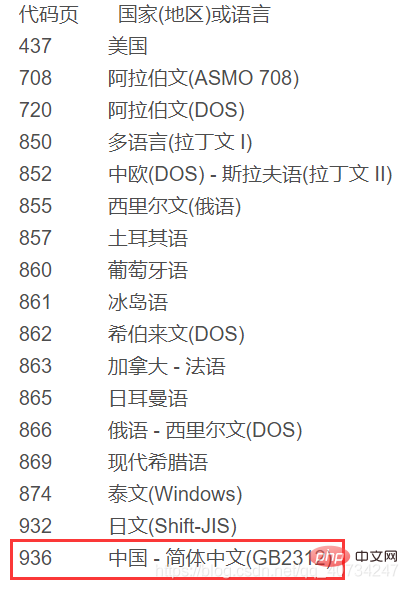
註:GBK是相容GB2312的編碼。
使用python的話,對於單一檔案進行編碼轉換,只需要7行程式碼就夠了!上面我寫了兩個函數,但是功能是一樣的,差別在於第一個函數是以特定的編碼方式讀取文字訊息,然後直接以另一種編碼方式寫入。第二個函數是以二進位形式讀取檔案內容,然後解碼再轉碼寫入。它的原理都是一樣的,即必須包括依序解碼和轉碼操作。
編碼、解碼、字元集本身是很複雜的,往深入了講我也不會了。這裡可以這樣簡化理解,兩個不同編碼的字符集具有相同的字符,所以將UTF-8編碼文件讀取出來,是為了得到它映射的字符,然後再寫入,是為了將它映射為另一種編碼字元集,所以說字元類似中繼站的功能。 而直接使用一種字元集去讀取另一種字元集的內容,就會出現上面cmd中顯示的亂碼。
PS: 所以,也可以解釋一個問題,就是為什麼開啟一個大的文字文件,會導致程式卡死!因為一個大的文字文件,裡麵包含了很多需要解碼的字元。這就和排隊有點類似,每一個字元等待被解碼,雖然處理一個字元很快,但是一個大的文字文件,包含了大量的字元。例如,notepad 打開大文本毫無壓力, 我打開這個超大型的文本,還是直接把它卡死了! (這裡的排隊只是一個比喻,實際的情況我也不太清楚,但是它一定是需要挨個處理的。)
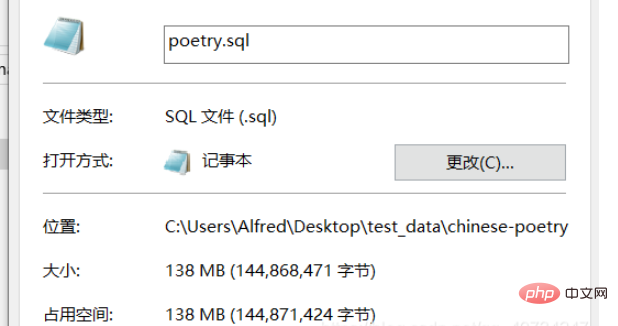
我們對其進行估計,假設所有字元都是中文(實際的話,還是包含一些英文的,當總的來說還是中文佔多數。)這裡顯示是大約5千萬的字符需要解碼,所以計算機處理起來仍然是很吃力的,notepad 可以查看摘要,但是直接打開就卡死了,這裡就不進行嘗試了。

以上是如何解決Python中文字檔轉換編碼的問題?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















