

Stable Diffusion-XL開啟公測,讓你擺脫繁瑣的長prompt!

自从Midjourney发布v5之后,在生成图像的人物真实程度、手指细节等方面都有了显著改善,并且在prompt理解的准确性、审美多样性和语言理解方面也都取得了进步。
相比之下,Stable Diffusion虽然免费、开源,但每次都要写一大长串的prompt,想生成高质量的图像全靠多次抽卡。

最近Stability AI的官宣,正在研发的Stable Diffusion XL开始面向公众测试,目前可以在Clipdrop平台免费试用。

试用链接:https://clipdrop.co/stable-diffusion
Stability AI的创始人兼首席执行官Emad Mostaque表示,目前该模型仍然处于训练阶段,等参数稳定后将会开源;SD-XL在「握手」等图像细节方面会表现更好,几乎完全可控。
Stable Diffusion XL也并不是最终发布版的名字,并且也并非是v3,因为SD-XL的架构和SD-v2系列的模型架构非常相似。

Minimalistic home gym with rubber flooring, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mats, high-tech equipment, high detail, organized and efficient.
简约的家庭健身房,橡胶地板,壁挂式电视,举重凳,药球,哑铃,瑜伽垫,高科技设备,高细节,组织和效率
下面几张SD-XL官方发布的例图,可以看出图像的质量已经非常能打了。



不过有时候less并不代表more,有网友认为SD-XL为了摆脱「糟糕的品味」,设定了太多的规则,定制化空间越来越小,不符合大多数人的喜好。目前v1.5的Stable Diffusion仍然是社区内最流行的基座模型。

网友表示希望新版SD能够和SD 2.1版本的嵌入、hypernetworkds和Lora模型保持兼容,再从零开始重训的话就太难受了。

也有网友认为,SD-XL的表现和civit网站上网友分享的模型差不多,新模型的效果也并不是特别惊艳,也就是平均水平。

SD-XL:開源版Midjourney
關於Stable Diffusion XL模型的具體信息,官方並沒有透露太多,目前只知道是與v2模型架構相似、但規模和參數量較大的模型。
SD-v2.1包含9億參數,SD-XL大約有23億參數,Emad表示正式版可能會額外發表一個較小的蒸餾版本。
SD-XL相比先前版本的改進如下:
- #使用較短的描述性prompt即可產生高品質圖像
- 可以產生更貼合prompt的圖像
- #圖片中的人體結構更合理
- 與v2.1和v1.5版本(程度較輕)相比,SD-XL產生的圖片更符合大眾美學
- 負面提示詞(negative prompt)是可選項
- 產生的肖像圖更逼真
- #圖片中的文字更清晰
要注意的是,SD-XL可能與先前版本的插件不相容。
清晰可讀的文字
在v1系列和v2.1版本的Stable Diffusion模型中,並不具備在圖片中生成可讀文本的能力。
雖然SD-XL產生的文字訊息並不總是準確,但確實得到了巨大的提升。

Photo of a woman sitting in a restaurant holding a menu that says “Menu”
一個女人坐在餐廳裡拿著寫著「Menu」的選單

Photo of a man holding a sign that says “Stable Diffusion”
##一個男人寫著寫著“ Stable Diffusion」的牌子
a young female holding a sign that says “Stable Diffusion”, highlights in hair, sitting outside restaurant, brown eyes, wearing a dress , side light
一個年輕的女性舉著一個牌子,上面寫著“Stable Diffusion”,頭髮高亮,坐在餐廳外面,棕色的眼睛,穿著裙子,側燈
更好的人體結構
Stable Diffusion在產生人體解剖結構方面一直存在諸多問題,多幾條腿、少個手臂實在是太常見不過的問題,通常需要使用inpaint功能進一步對圖像細節進行修正;或者是使用ControlNet的Open Pose功能從參考圖像中復制人體的姿態。
比如說SD-v1.5產生瑜珈的圖像,常常會出現扭曲的人體。

Photo of a woman in yoga outfit, triangle pose, beach in evening, rim lighting
#一個女人的照片在瑜珈服裝,三角形的姿勢,海灘在晚上,邊緣照明
SD-XL虽然生成的图像并不完美,不过在人体姿态方面已经有了显著的进步。

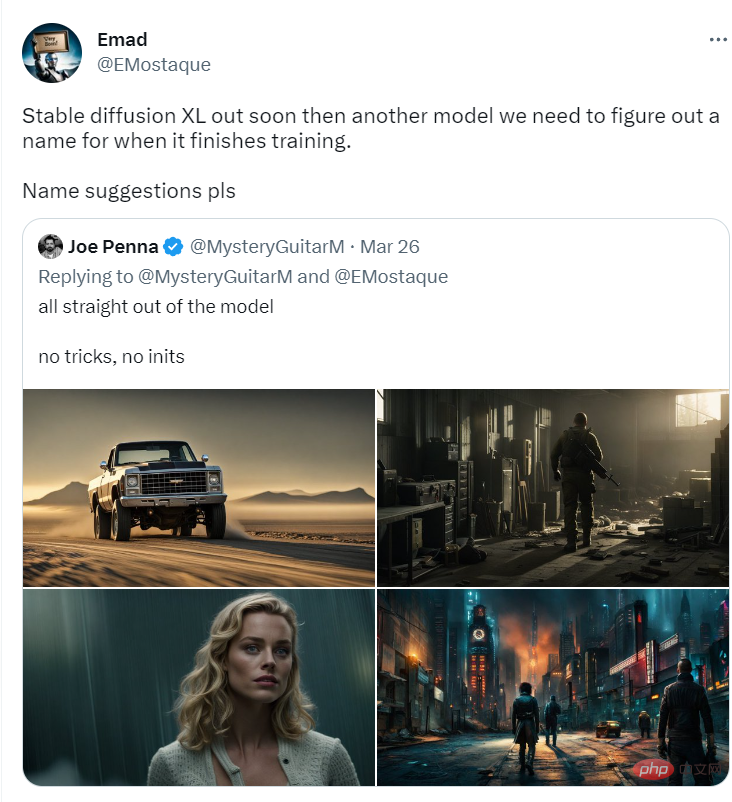
更有美感(more aesthetic)
比如同样以屋子为主题,SD-XL可以生成更对称、视觉效果更好的照片。

SD-XL在肖像照片上也有显著改进。
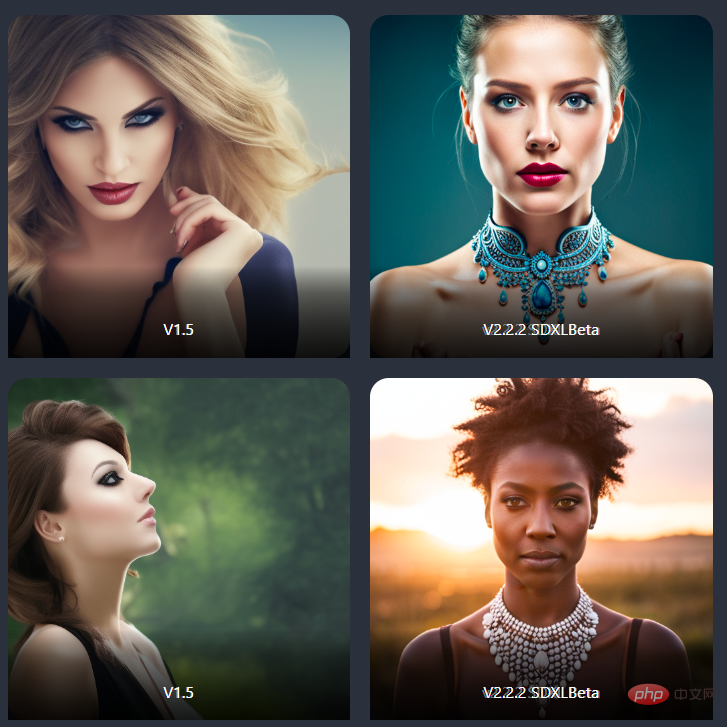
photo shot of a woman
一个女人的照片
更贴合prompt的图像
SD-XL可以更好地理解输入的prompt,并生成更精确的图像。
比如以duotone(双色)为例,SD-v1.5只会生成黑白图像,而SD-XL则可以生成具有多种颜色的双色调图像。
与 v1模型相比,理解提示符的能力有所提高。

duotone portrait of a woman
一个女人的双色调肖像
因为SD-XL同属v2系列模型,所以文本模型尺寸更大,可以比v1模型更好地理解提示词。

比如下面的例子中,v1.5模型始终无法理解图像中的两个主题(机器人和人类),但SD-XL模型可以生成正常的图像(虽然机器人还是不够big)。
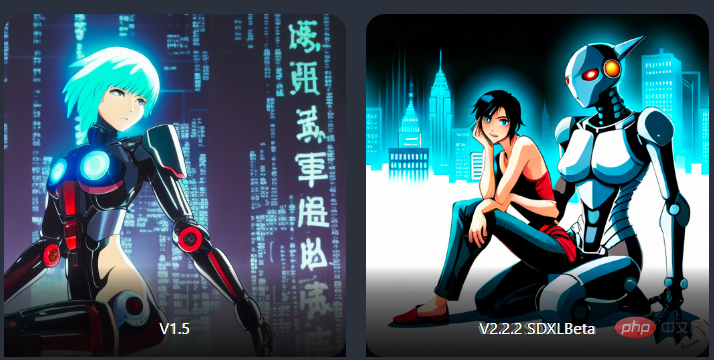
big robot friend sitting next to a human, ghost in the shell style, anime wallpaper
大机器人朋友坐在人类旁边攻壳机动队风格的动漫壁纸

a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
一个年轻人,头发染得很亮,棕色眼睛,穿着白衬衫和蓝色牛仔裤,站在海滩上,背景是一座火山
艺术风格
在艺术风格上,SD-XL并没有显著改进,和之前的版本各有千秋。
比如两个模型以不同的角度生成了Edward Hopper风格的图像。

New York city by Edward Hopper
Edward Hopper繪製的紐約
Leonid Afmov 的風格中,SD-v1.5更準確,SD-XL缺少了不同顏色的筆刷(unmistakable colorful board brushstrokes)。

New York city by Leonid Afremov
Leonid Afemov在繪製的紐約
William-Adolphe Bouguereau風格中,V1.5和SDXL都可以產生一些類似的內容,其中SD-XL更接近Bouguereau創作的經典學院派繪畫,並且臉部細節更多。

Portrait of beautiful woman by William-Adolphe Bouguereau
William-Adolphe Bouguereau繪製的美女肖像
風格轉變問題
在添加一些無關緊要的關鍵字後,模型的風格可能會突然轉變。
例如先生成一張照片風格的圖像。

a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
一個年輕人,頭髮染得很亮,棕色眼睛,穿著白襯衫和藍色牛仔褲,站在海灘上,背景是一座火山
再增加一條黃色的圍巾後,圖像風格就變成了卡通風格。

a young man, highlights in hair, brown eyes, wearing a yellow scarf, in white shirt and blue jean on a beach with a volcano in background
一個年輕人,頭髮染得很亮,棕色的眼睛,圍著黃色的圍巾,穿著白襯衫和藍色牛仔褲,站在一個火山為背景的海灘上
問題的故障可能源於預覽問題,在正式發布後該問題不知能否得到解決。
以上是Stable Diffusion-XL開啟公測,讓你擺脫繁瑣的長prompt!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 十個推薦開源免費文字標註工具
Mar 26, 2024 pm 08:20 PM
十個推薦開源免費文字標註工具
Mar 26, 2024 pm 08:20 PM
文字標註工作是將標籤或標記與文字中特定內容相對應的工作。其主要目的是為文本提供額外的信息,以便進行更深入的分析和處理,尤其是在人工智慧領域。文字標註對於人工智慧應用中的監督機器學習任務至關重要。用於訓練AI模型,有助於更準確地理解自然語言文本訊息,並提高文本分類、情緒分析和語言翻譯等任務的表現。透過文本標註,我們可以教導AI模型識別文本中的實體、理解上下文,並在出現新的類似數據時做出準確的預測。本文主要推薦一些較好的開源文字標註工具。 1.LabelStudiohttps://github.com/Hu
 15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
圖像標註是將標籤或描述性資訊與圖像相關聯的過程,以賦予圖像內容更深層的含義和解釋。這個過程對於機器學習至關重要,它有助於訓練視覺模型以更準確地識別圖像中的各個元素。透過為圖像添加標註,使得電腦能夠理解圖像背後的語義和上下文,從而提高對圖像內容的理解和分析能力。影像標註的應用範圍廣泛,涵蓋了許多領域,如電腦視覺、自然語言處理和圖視覺模型具有廣泛的應用領域,例如,輔助車輛識別道路上的障礙物,幫助疾病的檢測和診斷透過醫學影像識別。本文主要推薦一些較好的開源免費的圖片標註工具。 1.Makesens
 建議:優秀JS開源人臉偵測辨識項目
Apr 03, 2024 am 11:55 AM
建議:優秀JS開源人臉偵測辨識項目
Apr 03, 2024 am 11:55 AM
人臉偵測辨識技術已經是一個比較成熟且應用廣泛的技術。而目前最廣泛的網路應用語言非JS莫屬,在Web前端實現人臉偵測辨識相比後端的人臉辨識有優勢也有弱勢。優點包括減少網路互動、即時識別,大大縮短了使用者等待時間,提高了使用者體驗;弱勢是:受到模型大小限制,其中準確率也有限。如何在web端使用js實現人臉偵測呢?為了實現Web端人臉識別,需要熟悉相關的程式語言和技術,如JavaScript、HTML、CSS、WebRTC等。同時也需要掌握相關的電腦視覺和人工智慧技術。值得注意的是,由於Web端的計
 25個AI智能體源碼現已公開,靈感來自史丹佛的「虛擬小鎮」和《西方世界》
Aug 11, 2023 pm 06:49 PM
25個AI智能體源碼現已公開,靈感來自史丹佛的「虛擬小鎮」和《西方世界》
Aug 11, 2023 pm 06:49 PM
熟悉《西方世界》的觀眾都了解,這部劇設定在未來世界的一個巨大高科技成人主題樂園中,機器人們具備與人類相似的行為能力,能夠記憶所見所聞,重複核心故事情節。每天,這些機器人都會被重置,回到初始狀態在斯坦福論文《GenerativeAgents:InteractiveSimulacraofHumanBehavior》發布後,這種情景不再僅限於影視劇中,AI已經成功復現了這一場景Smallville的“虛擬小鎮」概覽圖論文網址:https://arxiv.org/pdf/2304.03442v1.pdf
 阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模態文件理解能力新SOTA!阿里mPLUG團隊發布最新開源工作mPLUG-DocOwl1.5,針對高解析度圖片文字辨識、通用文件結構理解、指令遵循、外部知識引入四大挑戰,提出了一系列解決方案。話不多說,先來看效果。複雜結構的圖表一鍵識別轉換為Markdown格式:不同樣式的圖表都可以:更細節的文字識別和定位也能輕鬆搞定:還能對文檔理解給出詳細解釋:要知道,“文檔理解”目前是大語言模型實現落地的一個重要場景,市面上有許多輔助文檔閱讀的產品,有的主要透過OCR系統進行文字識別,配合LLM進行文字理
 剛剛發布!一鍵產生動漫風格圖片的開源模型
Apr 08, 2024 pm 06:01 PM
剛剛發布!一鍵產生動漫風格圖片的開源模型
Apr 08, 2024 pm 06:01 PM
向大家介紹一個最新的AIGC開源專案-AnimagineXL3.1。這個專案是動漫主題文字到圖像模型的最新迭代,旨在為用戶提供更優化和強大的動漫圖像生成體驗。在AnimagineXL3.1中,開發團隊專注於優化了幾個關鍵方面,以確保模型在效能和功能上達到新的高度。首先,他們擴展了訓練數據,不僅包括了先前版本中的遊戲角色數據,還加入許多其他知名動漫系列的數據納入訓練集中。這項舉措豐富了模型的知識庫,使其能夠更全面地理解各種動漫風格和角色。 AnimagineXL3.1引入了一組新的特殊標籤和美學標
 單卡跑Llama 70B快過雙卡,微軟硬生把FP6搞到A100哩 | 開源
Apr 29, 2024 pm 04:55 PM
單卡跑Llama 70B快過雙卡,微軟硬生把FP6搞到A100哩 | 開源
Apr 29, 2024 pm 04:55 PM
FP8和更低的浮點數量化精度,不再是H100的「專利」了!老黃想讓大家用INT8/INT4,微軟DeepSpeed團隊在沒有英偉達官方支援的條件下,硬生在A100上跑起FP6。測試結果表明,新方法TC-FPx在A100上的FP6量化,速度接近甚至偶爾超過INT4,而且比後者擁有更高的精度。在此基礎之上,還有端到端的大模型支持,目前已經開源並整合到了DeepSpeed等深度學習推理框架中。這項成果對大模型的加速效果也是立竿見影──在這種框架下用單卡跑Llama,吞吐量比雙卡還要高2.65倍。一名
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
