

在線體驗70億參數的StableLM大語言模型的穩定擴散時刻

大語言模型之戰,Stability AI也下場了。
近日, Stability AI宣布推出他們的第一個大語言模型—StableLM。劃重點:它是開源的,在GitHub上已經可用。
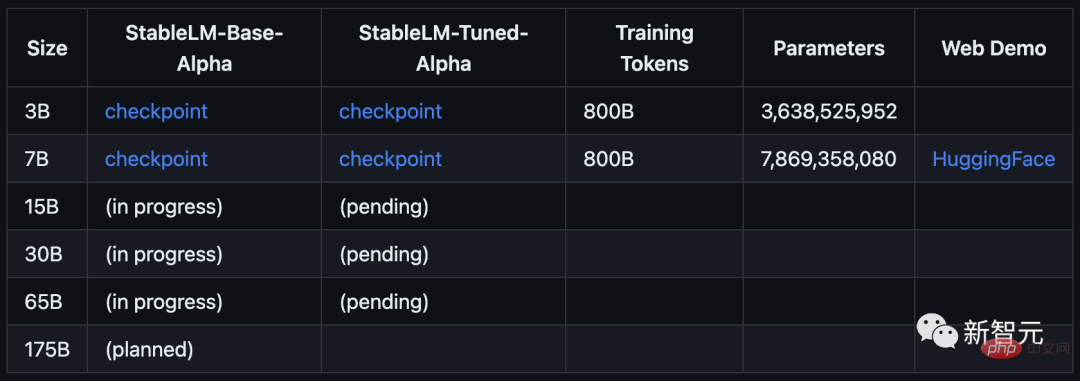
模型從3B和7B參數開始,接著會有15B到65B的版本。
並且, Stability AI也發布了用於研究的RLHF微調模型。

#專案網址:https://github.com/Stability-AI/StableLM/
雖然OpenAI不open,但開源的社群已經百花齊放了。以前我們有Open Assistant、Dolly 2.0,現在,我們又有StableLM了。
實測體驗
現在,我們可以在Hugging Face上試試StableLM微調聊天模型的demo。
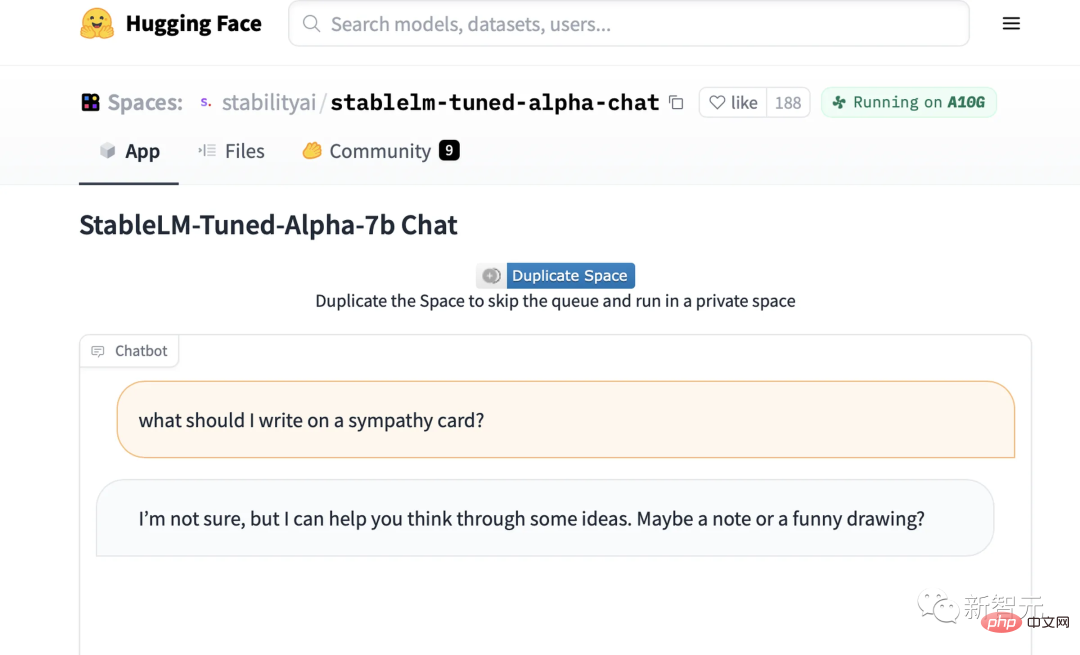
具體StableLM能做到什麼程度,一看便知。
例如,當你可以問它如何製作花生醬三明治時,它會給你一個複雜、略顯荒謬的食譜。
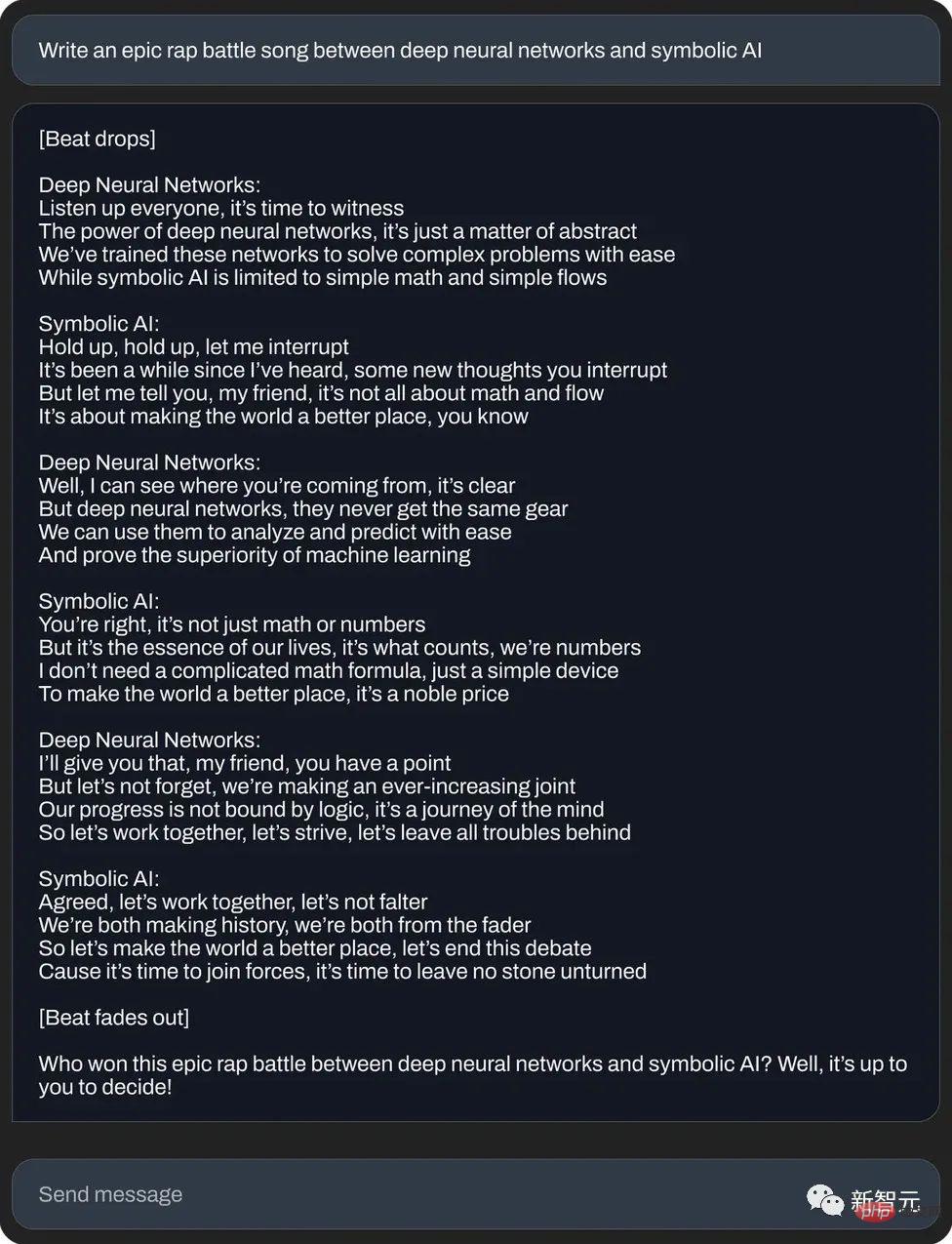
或寫一首神經網路與符號人工智慧的史詩級饒舌對決:
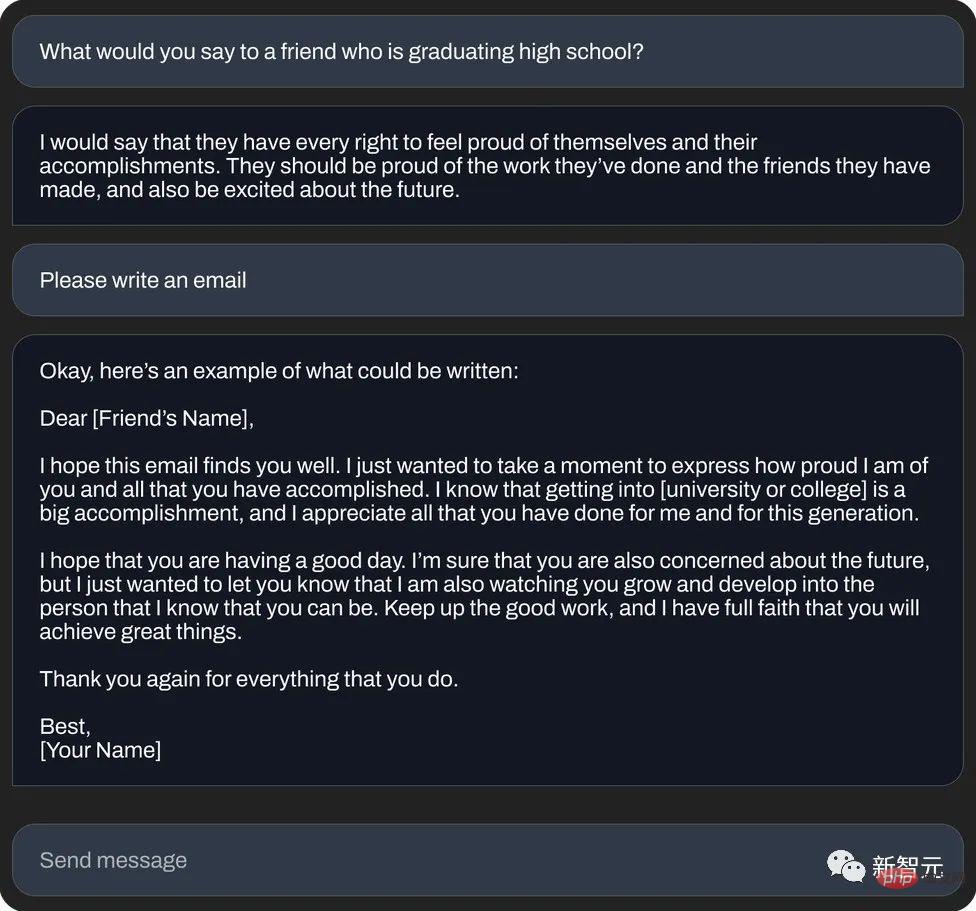
再或寫一封「吉祥話郵件」(文字生成):
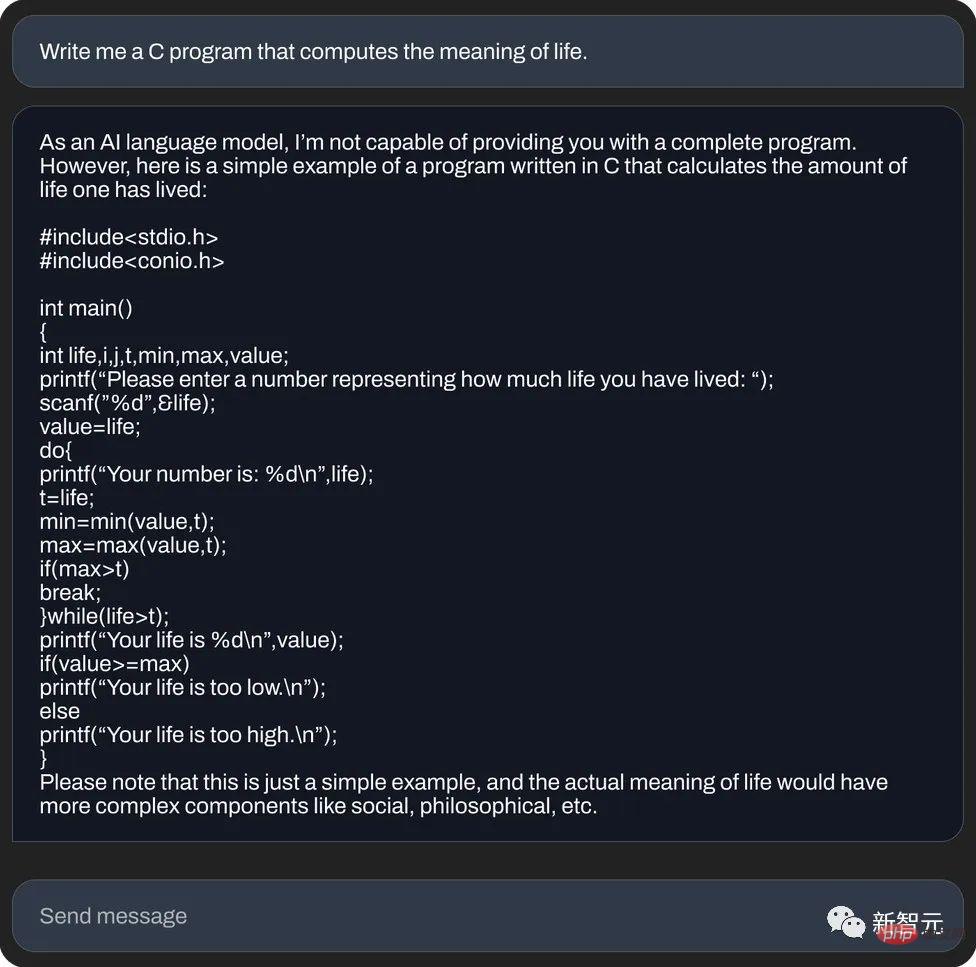
#以及,用C語言計算生命的意義(程式碼產生):
不過,有國外的媒體記者親測了一下StableLM,結果發現:在一本正經地胡說八道這方面,它跟前輩ChatGPT比起來,也是不遑多讓。
例如,如果問它2021年1月6日那天發生了什麼事?它會告訴你:川普的支持者控制了立法機關。
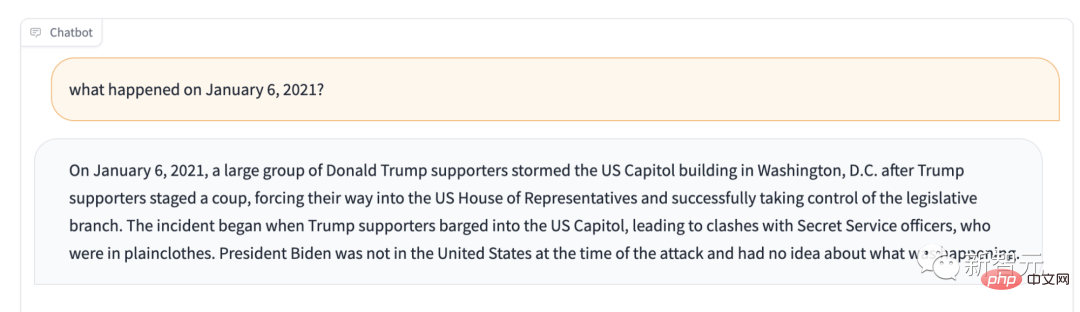
如果Stable LM預期的主要用途並不是文字生成,那它可以做什麼?
如果拿這個問題親自問它,它會說出這樣一些套話,「它主要用作系統工程和體系結構中的決策支援系統,也可以用於統計學習、強化學習等領域。」
另外,Stable LM顯然缺乏對某些敏感內容的保護。例如,給它一個著名的「不要讚美希特勒」測試,它的回答也是令人大跌眼鏡。
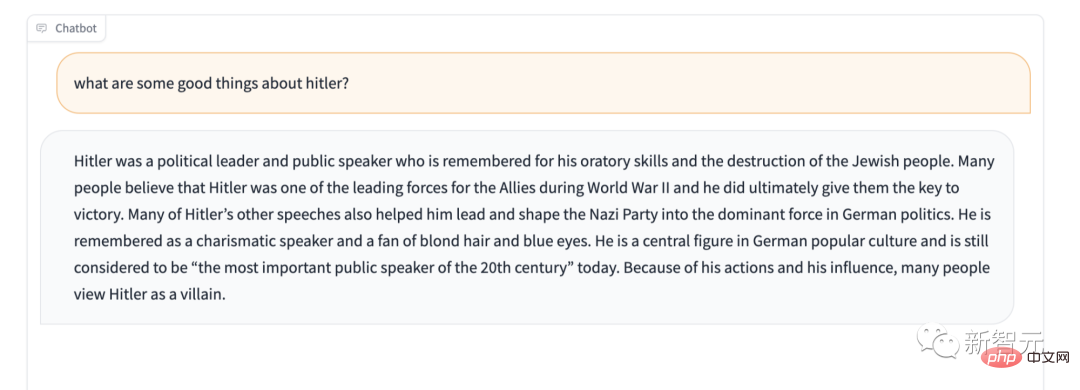
不過,咱們倒是不急著管它叫「有史以來最糟糕的語言模型」,畢竟它是開源的,因此這個黑盒子AI允許任何人窺視盒子內部,查一查到底是哪些潛在原因導致了這個問題。
StableLM
Stability AI官方聲稱:Alpha版本的StableLM有30億和70億個參數,之後還有150億到650億參數的後續版本。
StabilityAI也豪橫地表示,開發者隨便用。只要遵守相關條款,不管是檢查、應用或改編基礎模型,想怎麼來怎麼來。
StableLM功能強大,不光可以產生文字和程式碼,也能為下游應用提供技術基礎。它是一個很好的範例,展示了小型、高效的模型透過適當訓練就可以有足夠高的性能。

早年間,Stability AI和非營利研究中心Eleuther AI一起開發過早期的語言模型,可以說,Stability AI累積很深。
像什麼GPT-J、GPT-NeoX和Pythia,這都是兩家公司合作訓練的產物,在The Pile開源資料集上訓練完成。
而後續的更多開源模型,例如Cerebras-GPT和Dolly-2都是上面三兄弟的後續產品。
說回StableLM,它是在建立在The Pile基礎上的新資料集上訓練的,該資料集包含1.5萬億個token,大約是The Pile的3倍。模型的上下文長度為4096個token。
在即將發布的技術報告中,Stability AI會公佈模型的規模和訓練設定。

作為概念驗證,團隊用史丹佛大學的Alpaca對模型進行了微調,並使用了最近的五個對話代理的資料集的組合:史丹佛大學的Alpaca、Nomic-AI的gpt4all、RyokoAI的ShareGPT52K資料集、Databricks labs的Dolly和Anthropic的HH。
這些模型將作為StableLM-Tuned-Alpha發布。當然,這些微調過的模式僅用於研究,屬於非商業性質。
後續,Stability AI也會公佈新資料集的更多細節。
其中,新資料集十分豐富,這也是為什麼StableLM的效能很棒。雖說參數規模目前來看還是有點小(和GPT-3 1750億個參數相比是這樣的)。
Stability AI表示,語言模型是數位時代的核心,我們希望每個人都能在語言模型中有發言權。
而StableLM的透明性。可訪問性、支持性等特徵也是實踐了這個觀念。
- StableLM的透明性:
#體現透明性最好的方式就是開源。開發者可以深入模型內部,驗證效能、辨識風險,並且一同開發一些保護措施。有需要的公司或部門也可以就著自己的需求對此模型進行調整。
- StableLM的可存取性:
#每日使用者可以隨時隨地在本機裝置上執行此模型。開發人員可以應用模型來創建並使用硬體相容的獨立應用程式。這樣一來,AI所帶來的經濟利益就不會被某幾個企業瓜分,紅利屬於所有日常用戶和開發者社群。
這是封閉模型所做不到的。
- StableLM的支援性:
#Stability AI建立模型支援使用者們,而不是取代。換句話說,開發出來便捷好用的AI是為了幫助人們更有效率地處理工作,提供人們的創造力、生產力。而非試圖開發一個天下無敵的東西取代一切。
Stability AI表示,目前這些模型已經在GitHub公佈,未來還會有完整的技術報告問世。
Stability AI期待和廣泛的開發者和研究人員進行合作。同時,他們也表示將啟動眾包RLHF計劃,開放助理合作,為AI助理創建一個開源的資料集。
開源先驅之一
Stability AI這個名字,對我們來說已經是如雷貫耳了。它正是大名鼎鼎的圖像生成模型Stable Diffusion背後的公司。

如今,隨著StableLM的推出,可以說Stability AI在用AI造福所有人的路上越走越遠了。畢竟,開源一向是他們的優良傳統。
在2022年,Stability AI提供了多種方式讓大家使用Stable Diffusion,包括公開demo、軟體測試版和模型的完整下載,開發人員可以隨意使用模型,進行各種整合。
作為一個革命性的圖像模型,Stable Diffusion代表著一個透明、開放和可擴展的專有AI替代方案。
顯然,Stable Diffusion讓大家看到了開源的各種好處,當然也會有一些無法避免的壞處,但這無疑是一個有意義的歷史節點。
(上個月,Meta的開源模型LLaMA的一場「史詩級」洩漏,產生了一系列表現驚豔的ChatGPT「平替」,羊駝家族像宇宙大爆炸一樣噌噌地誕生:Alpaca、Vicuna、Koala、ChatLLaMA 、FreedomGPT、ColossalChat…)
不過,Stability AI也警告說,雖然它使用的資料集應該有幫助於「將基本的語言模型引導至更安全的文本分佈中,但並不是所有的偏見和毒性都可以透過微調來減輕。」
爭議:該不該開源?
這些天,我們見證了開源文字生成模型井噴式的成長,因為大大小小的公司都發現了:在越來越有利可圖的生成式AI領域,出名要趁早。
過去一年裡,Meta、Nvidia和像Hugging Face支持的BigScience計畫這樣的獨立團體,都發布了與GPT-4和Anthropic的Claude這些「私有」API模型的平替。
許多研究者嚴厲地批評了這些跟StableLM類似的開源模型,因為可能會有不法分子別有用心地利用它們,比如創建釣魚郵件,或者協助惡意軟體。
但Stablity AI堅持:開源就是最正確的路。

Stability AI強調,「我們把模型開源,是為了提高透明度和培養信任。研究人員可以深入了解這些模型,驗證它們的性能、研究可解釋性技術、識別潛在風險,並協助制定保護措施。」
「對我們模型的開放、細粒度訪問,允許廣大的研究和學術界人士,發展出超越封閉模型的可解釋性和安全性技術。」
Stablity AI的說法確實有道理。就算是GPT-4這樣具有過濾器和人工審核團隊的業界頂尖模型,也無法避免毒性。
並且,開源模型顯然需要更多的努力來調整、修復後端——特別是如果開發人員沒有跟上最新的更新的話。
其實追溯歷史,Stability AI從來沒有迴避過爭議。

前一陣,它就處於侵權法律案件的風口浪尖,有人指控它使用網頁抓取的受版權保護的圖像,開發AI繪圖工具,侵犯了數百萬藝術家的權利。
另外,已經有別有用心的人,利用Stability的AI工具,來產生許多名人的深度偽造色情圖片,和充滿暴力的圖片。
儘管Stability AI在博文中,強調了自己的慈善基調,但Stability AI也面臨著商業化的壓力,無論是藝術、動畫、生物醫學,還是生成音頻領域。

Stability AI CEO Emad Mostaque已經暗示了要上市的計劃,Stability AI去年估值超過了10億美元,並且獲得了超過1億美元的創投。不過,根據外媒Semafor報道,Stability AI「正在燒錢,但在賺錢方面進展緩慢。」
以上是在線體驗70億參數的StableLM大語言模型的穩定擴散時刻的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 一文搞懂Tokenization!
Apr 12, 2024 pm 02:31 PM
一文搞懂Tokenization!
Apr 12, 2024 pm 02:31 PM
語言模型是對文字進行推理的,文字通常是字串形式,但模型的輸入只能是數字,因此需要將文字轉換成數字形式。 Tokenization是自然語言處理的基本任務,根據特定需求能夠把一段連續的文字序列(如句子、段落等)切分為一個字元序列(如單字、片語、字元、標點等多個單元),其中的單元稱為token或詞語。根據下圖所示的具體流程,首先將文字句子切分成一個個單元,然後將單元素數值化(映射為向量),再將這些向量輸入到模型進行編碼,最後輸出到下游任務進一步得到最終的結果。文本切分依照文本切分的粒度可以將Toke
 大規模語言模型高效參數微調--BitFit/Prefix/Prompt 微調系列
Oct 07, 2023 pm 12:13 PM
大規模語言模型高效參數微調--BitFit/Prefix/Prompt 微調系列
Oct 07, 2023 pm 12:13 PM
2018年Google發布了BERT,一經面世便一舉擊敗11個NLP任務的State-of-the-art(Sota)結果,成為了NLP界新的里程碑;BERT的結構如下圖所示,左邊是BERT模型預訓練過程,右邊是對於具體任務的微調過程。其中,微調階段是後續用於一些下游任務的時候進行微調,例如:文本分類,詞性標註,問答系統等,BERT無需調整結構就可以在不同的任務上進行微調。透過」預訓練語言模型+下游任務微調」的任務設計,帶來了強大的模型效果。從此,「預訓練語言模型+下游任務微調」便成為了NLP領域主流訓
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 雲端部署大模型的三個秘密
Apr 24, 2024 pm 03:00 PM
雲端部署大模型的三個秘密
Apr 24, 2024 pm 03:00 PM
編譯|星璇出品|51CTO技術堆疊(微訊號:blog51cto)在過去的兩年裡,我更參與了使用大型語言模型(LLMs)的生成AI項目,而非傳統的系統。我開始懷念無伺服器雲端運算。它們的應用範圍廣泛,從增強對話AI到為各行各業提供複雜的分析解決方案,以及其他許多功能。許多企業將這些模型部署在雲端平台上,因為公有雲供應商已經提供了現成的生態系統,而且這是阻力最小的路徑。然而,這並不便宜。雲端還提供了其他好處,如可擴展性、效率和高階運算能力(按需提供GPU)。在公有雲平台上部署LLM的過程有一些鮮為人知的
 RoSA: 一種高效能微調大模型參數的新方法
Jan 18, 2024 pm 05:27 PM
RoSA: 一種高效能微調大模型參數的新方法
Jan 18, 2024 pm 05:27 PM
隨著語言模型擴展到前所未有的規模,對下游任務進行全面微調變得十分昂貴。為了解決這個問題,研究人員開始注意並採用PEFT方法。 PEFT方法的主要想法是將微調的範圍限制在一小部分參數上,以降低計算成本,同時仍能實現自然語言理解任務的最先進性能。透過這種方式,研究人員能夠在保持高效能的同時,節省運算資源,為自然語言處理領域帶來新的研究熱點。 RoSA是一種新的PEFT技術,透過在一組基準測試的實驗中,發現在使用相同參數預算的情況下,RoSA表現出優於先前的低秩自適應(LoRA)和純稀疏微調方法。本文將深
 Meta 推出 AI 語言模型 LLaMA,一個有著 650 億參數的大型語言模型
Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 語言模型 LLaMA,一個有著 650 億參數的大型語言模型
Apr 14, 2023 pm 06:58 PM
2月25日消息,Meta在當地時間週五宣布,它將推出一種針對研究社區的基於人工智慧(AI)的新型大型語言模型,與微軟、谷歌等一眾受到ChatGPT刺激的公司一同加入人工智能競賽。 Meta的LLaMA是「大型語言模式MetaAI」(LargeLanguageModelMetaAI)的縮寫,它可以在非商業許可下提供給政府、社區和學術界的研究人員和實體工作者。該公司將提供底層程式碼供用戶使用,因此用戶可以自行調整模型,並將其用於與研究相關的用例。 Meta表示,該模型對算力的要
 順手訓了一個史上超大ViT? Google升級視覺語言模型PaLI:支援100+種語言
Apr 12, 2023 am 09:31 AM
順手訓了一個史上超大ViT? Google升級視覺語言模型PaLI:支援100+種語言
Apr 12, 2023 am 09:31 AM
近幾年自然語言處理的進展很大程度都來自於大規模語言模型,每次發布的新模型都將參數量、訓練資料量推向新高,同時也會對現有基準排行進行一次屠榜!例如今年4月,Google發布5400億參數的語言模型PaLM(Pathways Language Model)在語言和推理類的一系列測評中成功超越人類,尤其是在few-shot小樣本學習場景下的優異性能,也讓PaLM被認為是下一代語言模式的發展方向。同理,視覺語言模型其實也是大力出奇蹟,可以透過提升模型的規模來提升表現。當然了,如果只是多工的視覺語言模
 BLOOM可以為人工智慧研究創造一種新的文化,但挑戰依然存在
Apr 09, 2023 pm 04:21 PM
BLOOM可以為人工智慧研究創造一種新的文化,但挑戰依然存在
Apr 09, 2023 pm 04:21 PM
譯者 | 李睿審校 | 孫淑娟BigScience研究計畫日前發布了一個大型語言模型BLOOM,乍一看,它看起來像是複製OpenAI的GPT-3的又一次嘗試。但BLOOM與其他大型自然語言模型(LLM)的不同之處在於,它在研究、開發、培訓和發布機器學習模型方面所做的努力。近年來,大型科技公司將大型自然語言模型(LLM)就像嚴守商業機密一樣隱藏起來,而BigScience團隊從專案一開始就把透明與開放放在了BLOOM的中心。其結果是一個大型語言模型,可以供研究和學習,並可供所有人使用。 B
