

Python內建型別dict源碼解析

深入認識Python內建類型——dict
註:本篇是根據教程學習記錄的筆記,部分內容與教程是相同的,因為轉載需要填鏈接,但是沒有,所以填的原創,如果侵權會直接刪除。
「深入認識Python內建類型」這部分的內容會從原始碼角度為大家介紹Python中各種常用的內建類型。
dict是日常開發中最常用的內建類型之一,而且Python虛擬機器的運作也非常依賴dict物件。掌握好dict的底層知識,無論是對資料結構基礎知識的理解,或是對開發效率的提升,應該都是有一定幫助的。
1 執行效率
無論是Java中的Hashmap,或是Python中的dict,都是效率很高的資料結構。 Hashmap也是Java面試中的基本考點:陣列 鍊錶 紅黑樹的雜湊表,有著很高的時間效率。同樣地,Python中的dict也由於它底層的哈希表結構,在插入、刪除、查找等操作上都有著O(1)的平均複雜度(最壞情況下是O(n))。這裡我們將list和dict比較一下,看看二者的搜尋效率差異有多大:(資料來自原文章,大家可以自行測試下)
| 容器規模 | 規模成長係數 | dict消耗時間 | dict耗時成長係數 | list消耗時間 | list耗時成長係數 |
|---|---|---|---|---|---|
| 1000 | 1 | 0.000129s | 1 | #0.036s | 1 |
| 10000 | 10 | 0.000172s | 1.33 | 0.348s | 9.67 |
| 100000 | #100 | 0.000216s | 1.67 | #3.679s | 102.19 |
| 1000000 | 1000 | 0.000382s | #2.96 | 48.044s | 1335.56 |
思考:這裡原文章是比較的將需要搜尋的資料分別作為list的元素和dict的key,個人認為這樣的比較並沒有意義。因為本質上list也是哈希表,其中key是0到n-1,值就是我們要查找的元素;而這裡的dict是將要查找的元素作為key,而值是True(原文章中代碼是這樣設置的)。如果真要比較可以比較下查詢list的0~n-1和查詢dict的對應key,這樣才是控制變數法,hh。當然這裡我個人覺得不妥的本質原因是:list它有儲存意義的地方是它的value部分,而dict的key和value都有一定的儲存意義,個人認為沒必要過分糾結這兩者的搜尋效率,弄清楚二者的底層原理,在實際工程中選擇運用才是最重要的。
2 內部結構
2.1 PyDictObject
#由於關聯式容器使用的場景非常廣泛,幾乎所有現代程式語言都提供某種關聯式容器,而且特別關注鍵的搜尋效率。例如C 標準函式庫中的map就是一種關聯式容器,其內部基於紅黑樹實現,此外還有剛剛提到的Java中的Hashmap。紅黑樹是一種平衡二元樹,能夠提供良好的操作效率,插入、刪除、搜尋等關鍵操作的時間複雜度都是O(logn)。
Python虛擬機的運行重度依賴dict對象,像是名字空間、物件屬性空間等概念的底層都是由dict物件來管理資料的。因此,Python對dict物件的效率要求更為苛刻。於是,Python中的dict使用了效率優於O(logn)的雜湊表。
dict物件在Python內部由結構體PyDictObject表示,原始碼如下:
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;原始碼分析:
ma_used:物件目前所保存的鍵值對個數
ma_version_tag:物件目前版本號,每次修改時更新(版本號感覺在業務開發中也挺常見的)
ma_keys:指向由鍵物件對應的雜湊表結構,類型為PyDictKeysObject
ma_values:splitted模式下指向所有值物件組成的陣列(如果是combined模式,值會儲存在ma_keys中,此時ma_values為空)
2.2 PyDictKeysObject
從PyDictObject的原始碼中可以看到,相關的哈希表是透過PyDictKeysObject來實現的,原始碼如下:
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};原始碼分析:
dk_refcnt:引用計數,和映射視圖的實作有關,類似物件引用計數
dk_size:哈希表大小,必須是2的整數次冪,這樣可以將模運算最佳化成位元運算(
可以學習一下,結合實際業務運用)dk_lookup:雜湊查找函數指針,可以根據dict目前狀態選用最優函數
- ##dk_usable:鍵值對數組可用個數
- dk_nentries:鍵值對數組已用個數
- dk_indices:哈希表起始位址,哈希表後緊接著鍵值對數組dk_entries,dk_entries的型別為PyDictKeyEntry
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;- me_hash:鍵物件的雜湊值,避免重複計算
- me_key :鍵物件指標
- me_value:值物件指標
##dict內部的hash表圖如圖所示:
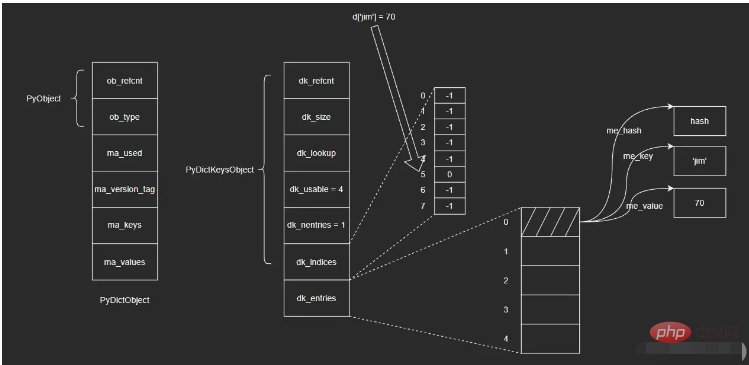 dict物件真正的核心在於PyDictKeysObject中,它包含兩個關鍵數組:一個是哈希索引數組dk_indices,另一個是鍵值對數組dk_entries 。 dict所維護的鍵值對,會依照先來後到的順序儲存於鍵值對數組中;而雜湊索引數組對應槽位則保存鍵值對在數組中的位置。
dict物件真正的核心在於PyDictKeysObject中,它包含兩個關鍵數組:一個是哈希索引數組dk_indices,另一個是鍵值對數組dk_entries 。 dict所維護的鍵值對,會依照先來後到的順序儲存於鍵值對數組中;而雜湊索引數組對應槽位則保存鍵值對在數組中的位置。
以向空dict物件d中插入{'jim': 70}為例,步驟如下:
i. 將鍵值對保存在dk_entries陣列結尾(這裡陣列初始為空,末尾即數組下標為”0“的位置);
ii. 計算鍵對象'jim'的哈希值並取右3位(即對8取模,dk_indices數組長度為8,這裡前面提到了保持數組長度為2的整數次冪,可以將模運算轉換為位元運算,這裡直接取右3位即可),假設最後得到的值為5,即對應dk_indices數組中下標為5的位置;
iii. 將被插入的鍵值對在dk_entries數組中對應的下標」0“,保存於哈希索引數組dk_indices中下標為5的位置。
進行查找操作,步驟如下:
i. 計算鍵物件'jim'的雜湊值,並取右3位,得到該鍵在雜湊索引數組dk_indices中的下標5;
ii. 找到哈希索引數組dk_indices下標為5的位置,取出其中保存的值——0,即鍵值對在dk_entries數組中的位置;
iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码)
这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。
3 容量策略
示例:
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。
为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义:
# define USABLE_FRACTION(n) (((n) << 1)/3)
此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。
4 内存优化
在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色:
entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
由于哈希表必须保持稀疏,最多只有2/3满(太满会导致哈希冲突频发,性能下降),这意味着至少要浪费1/3的内存空间,而一个键值对条目PyDictKeyEntry的大小达到了24字节。试想一个规模为65536的哈希表,将浪费:
65536 * 1/3 * 24 = 524288 B 大小的空间(512KB)
为了尽量节省内存,Python将键值对数组压缩到原来的2/3(原来只能2/3满,现在可以全满),只负责存储,索引由另一个数组负责。由于索引数组indices只需要保存键值对数组的下标,即保存整数,而整数占用的空间很小(例如int为4字节),因此可以节省大量内存。
此外,索引数组还可以根据哈希表的规模,选择不同大小的整数类型。对于规模不超过256的哈希表,选择8位整数即可;对于规模不超过65536的哈希表,16位整数足以;其他以此类推。
对比一下两种方式在内存上的开销:
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
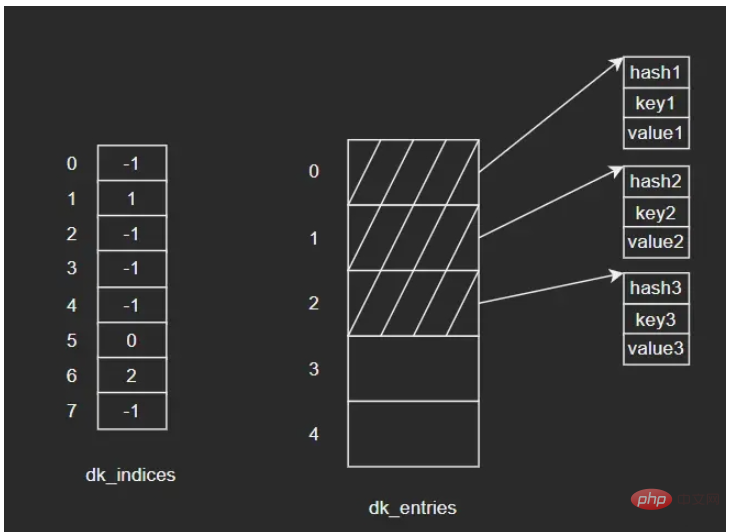
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
以上是Python內建型別dict源碼解析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
