
現代電腦用二進位(bit,位元)作為資訊的基礎單位,1 個位元組等於8 位,例如big字串是由3 個位元組組成,但實際在電腦儲存時將其以二進位表示,big分別對應的ASCII 碼分別是98、105、103,對應的二進位分別是01100010、01101001 和01100111。
許多開發語言都提供了操作位的功能,合理地使用位元能夠有效地提高記憶體使用率和開發效率。
Bit-map 的基本想法就是用一個 bit 位元來標記某個元素對應的 value,而 key 就是該元素。由於採用了 bit 為單位來儲存數據,因此在儲存空間方面,可以大幅節省。
在Java 中,int 佔4 個位元組,1 個位元組= 8位元(1 byte = 8 bit),如果我們用這個32 個bit 位元的每一位的值來表示一個數的話是不是就可以表示32 個數字,也就是說32 個數字只需要一個int 所佔的空間大小就可以了,那就可以縮小空間32 倍。
1 Byte = 8 Bit,1 KB = 1024 Byte,1 MB = 1024 KB,1GB = 1024 MB
假設網站有1 億用戶,每天獨立訪問的用戶有5 千萬,如果每天用集合類型和BitMap 分別儲存活躍用戶:
1.假如用戶id 是int 型,4 字節,32 位,則集合類型佔據的空間為50 000 000 * 4/1024/1024 = 200M;
2.如果按位存儲,5 千萬個數就是5 千萬位,佔據的空間為50 000 000/8/1024/1024 = 6M。
那麼要如何用 BitMap 來表示一個數字呢?
上面說了用bit 位元來標記某個元素對應的value,而key 即是該元素,我們可以把BitMap 想像成一個以位為單位的數組,數組的每個單元只能儲存0 和1(0 表示這個數不存在,1 表示存在),陣列的下標在BitMap 中叫做偏移量。例如我們需要表示{1,3,5,7}這四個數,如下:
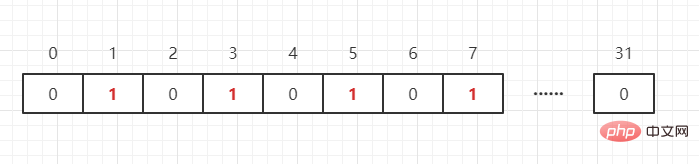
那如果還存在一個數 65 呢?只需要開int[N/32 1]個int 陣列就可以儲存完這些資料(其中N 表示這群資料中的最大值),即:
int [0]:可以表示0~31
int[1]:可以表示32~63
int[2] :可以表示64~95
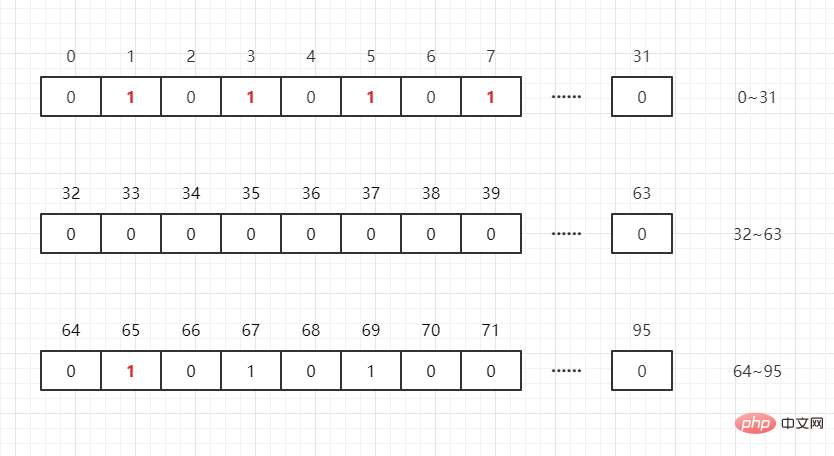
假設我們要判斷任一整數是否在列表中,則 M/32 就得到下標, M2就知道它在此下標的哪個位置,如:
65/32 = 2,652=1,即65 在 int[2] 中的第1 位元。
本質上布隆過濾器是一種資料結構,比較巧妙的機率型資料結構,特點是高效地插入和查詢,可以用來告訴你“某樣東西一定不存在或可能存在」。
相比於傳統的 List、Set、Map 等資料結構,它更有效率、佔用空間更少,但是缺點是其傳回的結果是機率性的,而不是確切的。
實際上,布隆過濾器廣泛應用於網頁黑名單系統、垃圾郵件過濾系統、爬蟲網址判重系統等,Google 著名的分散式資料庫Bigtable 使用了布隆過濾器來尋找不存在的行或列,以減少磁碟查找的IO 次數,Google Chrome 瀏覽器使用了布隆過濾器加速安全瀏覽服務。
在許多Key-Value 系統中也使用了布隆過濾器來加快查詢過程,如Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁碟中,存取磁碟需要花費大量時間,然而使用布隆過濾器可以快速判斷某個Key 對應的Value 是否存在,因此可以避免許多不必要的磁碟IO 操作。
透過一個 Hash 函數將一個元素映射成一個位元陣列(Bit Array)中的一個點。這樣一來,我們只要看看這個點是不是 1 就知道可以集合中有沒有它了。這就是布隆過濾器的基本想法。
1、目前有 10 億數量的自然數,亂序排列,需要對其排序。限制條件在 32 位元機器上面完成,記憶體限制為 2G。如何完成?
2、如何快速在億級黑名單中快速定位 URL 位址是否在黑名單中? (每個 URL 平均 64 位元組)
3、需要進行使用者登陸行為分析,來確定使用者的活躍狀況?
4、網路爬蟲-如何判斷 URL 是否被爬過?
5、快速定位使用者屬性(黑名單、白名單等)?
6、資料儲存在磁碟中,如何避免大量的無效 IO?
7、判斷一個元素在億級資料中是否存在?
8、快取穿透。
一般來說,將網頁 URL 存入資料庫進行查找,或建立一個哈希表進行查找就 OK 了。
當資料量小的時候,這麼思考是對的,確實可以將值對應到 HashMap 的 Key,然後可以在 O(1) 的時間複雜度內 傳回結果,效率奇高。但是HashMap 的實作也有缺點,例如儲存容量佔比高,考慮到負載因子的存在,通常空間是不能被用滿的,舉個例子如果一個1000 萬HashMap,Key=String(長度不超過16 字符,且重複性極小),Value=Integer,會佔據多少空間呢? 1.2 個 G。
實際上用bitmap,1000 萬個int 型,只需要40M( 10 000 000 * 4/1024/1024 =40M)左右空間,佔3%,1000 萬個Integer,需要161M 左右空間,佔13.3%。
可見一旦你的值很多例如上億的時候,那 HashMap 佔據的記憶體大小就可想而知了。
但如果整個網頁黑名單系統包含100 億個網頁URL,在資料庫中尋找是很費時的,如果每個URL 空間為64B,那麼需要記憶體為640GB,一般的伺服器很難達到這個需求。
假設我們有個集合 A,A 中有 n 個元素。利用k個雜湊雜湊函數,將A中的每個元素映射到長度為a 位元的陣列B中的不同位置上,這些位置上的二進制數均設定為1。如果要檢查的元素,經過這k個雜湊函數的映射後,發現其k 個位置上的二進制數全部為1,這個元素很可能屬於集合A,反之,一定不屬於集合A。
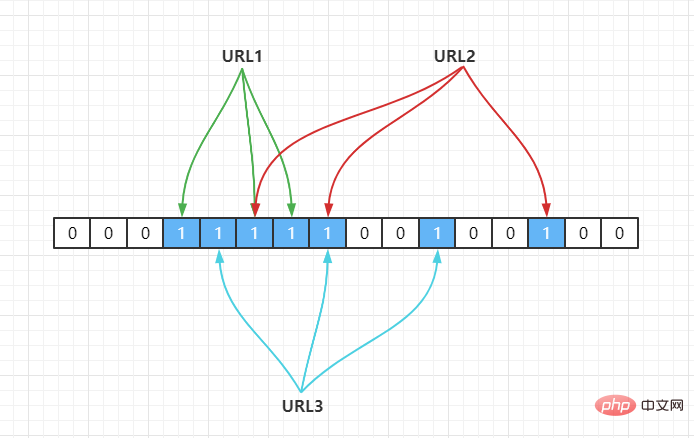
例如我們有3 個URL {URL1,URL2,URL3},透過一個hash 函數把它們對應到一個長度為16 的陣列上,如下:
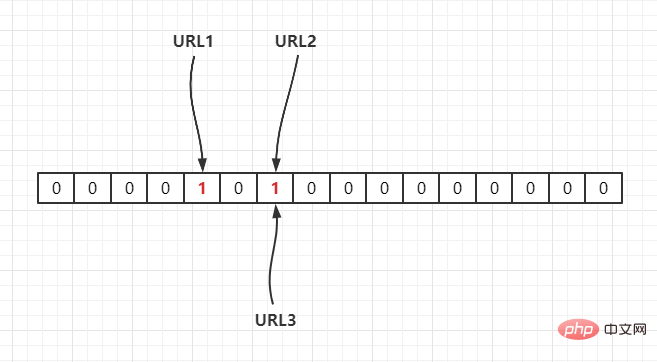
若目前雜湊函數為 Hash2(),透過雜湊運算對應到陣列中,假設Hash2(URL1) = 3,Hash2(URL2) = 6,Hash2(URL3) = 6,如下:
因此,如果我們需要判斷 URL1是否在這個集合中,則透過Hash(1)計算出其下標,並得到其值若為1 則說明存在。
由於Hash 存在雜湊衝突,如上面URL2,URL3都定位到一個位置上,假設Hash 函數是良好的,如果我們的陣列長度為m 個點,那麼如果我們要將衝突率降低到例如 1%, 這個散列表就只能容納 m/100 個元素,顯然空間利用率就變低了,也就是沒辦法做到空間有效(space-efficient)。
解決方法也簡單,就是使用多個Hash 演算法,如果它們有一個說元素不在集合中,那肯定就不在,如下:
Hash2(URL1) = 3,Hash3(URL1) = 5,Hash4(URL1) = 6 Hash2(URL2) = 5,Hash3(URL2) = 8,Hash4(URL2) = 14 Hash2(URL3) = 4,Hash3(URL3) = 7,Hash4(URL3) = 10
上面的做法同樣有問題,因為隨著增加的值越來越多,被置為1 的bit 位元也會越來越多,這樣某個值即使沒有被儲存過,但是萬一哈希函數回傳的三個bit 位元都被其他值置位了1 ,那麼程式還是會判斷這個值存在。例如此時來一個不存在的 URL1000,經過哈希計算後,發現bit 位元為下:
Hash2(URL1000) = 7,Hash3(URL1000) = 8,Hash4(URL1000) = 14
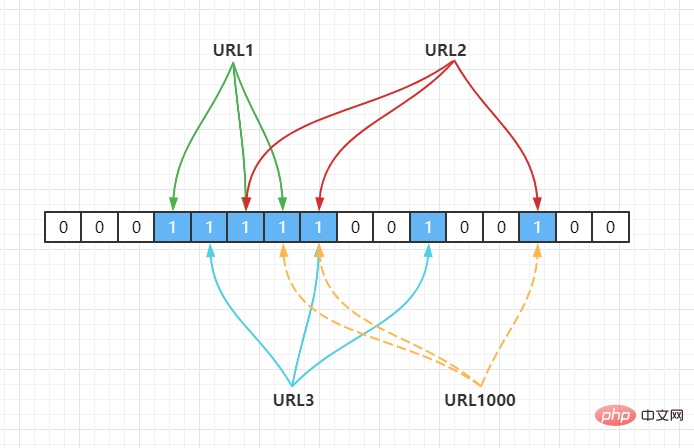
URL1,URL2,URL3置為1 了,此時程式就會判斷 URL1000 值存在。
布隆過濾器判斷存在的不一定存在,但是,判斷不存在的一定不存在。
布隆濾鏡可精確的代表一個集合,可精確判斷某一元素是否在此集合中,精確程度由使用者的具體設計決定,達到100% 的正確是不可能的。但是布隆過濾器的優勢在於,利用很少的空間可以達到較高的精確率。
實作Redis 的 bitmap基於redis 的 bitmap資料結構的相關指令來執行。 RedisBloom布林過濾器可以使用Redis 中的點陣圖(bitmap)操作實現,直到Redis4.0 版本提供了插件功能,Redis 官方提供的布隆過濾器才正式登場,布隆過濾器作為一個插件載入到Redis Server 中,官網推薦了一個RedisBloom 作為Redis 布隆過濾器的Module。 Guava 的 BloomFilterGuava 專案發布版本11.0時,新加入的功能之一是BloomFilter類別。 RedissonRedisson 底層基於位圖實作了一個布林過濾器。public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。
因此我们可以用布隆过滤器来解决,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如:一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
注:布隆过滤器可能会误判,放过部分请求,当不影响整体,所以目前该方案是处理此类问题最佳方案
以上是Java的布隆過濾器如何實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















