

Python時間序列資料操作的常用方法總結

時間序列資料是一種在一段時間內收集的資料類型,它通常用於金融、經濟學和氣象學等領域,經常透過分析來了解隨著時間的推移的趨勢和模式
Pandas是Python中一個強大且受歡迎的資料操作庫,特別適合處理時間序列資料。它提供了一系列工具和函數可以輕鬆載入、操作和分析時間序列資料。
在本文中,我們介紹時間序列資料的索引和切片、重新採樣和滾動視窗計算以及其他有用的常見操作,這些都是使用Pandas操作時間序列資料的關鍵技術。
資料型別
Python
在Python中,沒有專門用來表示日期的內建資料型別。一般情況下都會使用datetime模組提供的datetime物件進行日期時間的操作。
import datetime
t = datetime.datetime.now()
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-12-26 14:20:51.278230一般情況下我們都會使用字串的形式儲存日期和時間。所以在使用時我們需要將這些字串進行轉換成datetime物件。
一般情況下時間的字串有以下格式:
- YYYY-MM-DD (e.g. 2022-01-01)
- YYYY/MM/DD (e.g. 2022/01/01)
- DD-MM-YYYY (e.g. 01-01-2022)
- DD/MM/YYYY (e.g. 01/01/2022)
- #MM-DD-YYYY (e.g. 01-01-2022)
- MM/DD/YYYY (e.g. 01/01/2022)
- HH:MM:SS (e.g. 11:30 :00)
- HH:MM:SS AM/PM (e.g. 11:30:00 AM)
- HH:MM AM/PM (e.g. 11:30 AM)
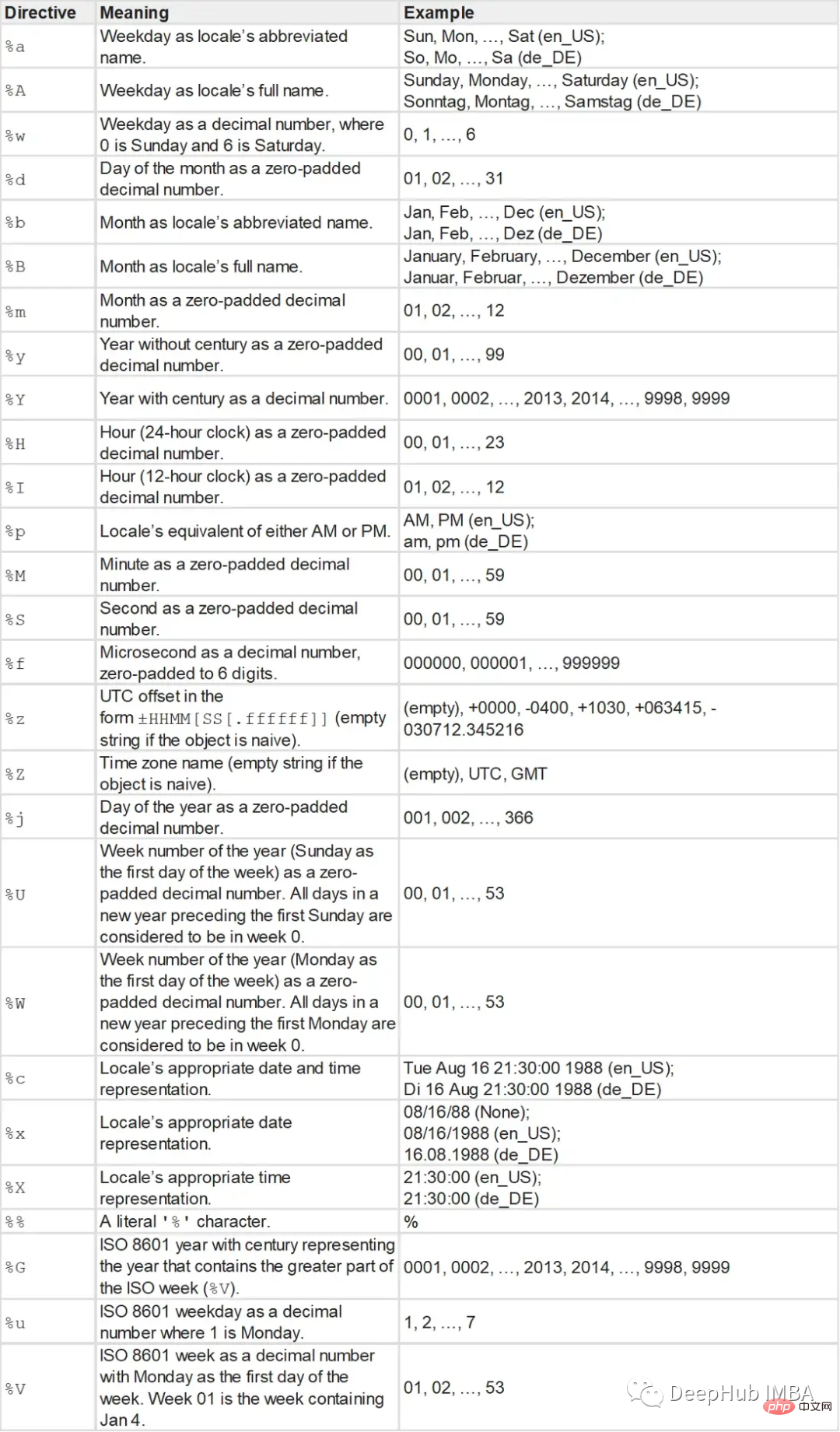
strptime 函數以字串和格式字串作為參數,傳回一個datetime物件。
string = '2022-01-01 11:30:09'
t = datetime.datetime.strptime(string, "%Y-%m-%d %H:%M:%S")
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-01-01 11:30:09格式字串如下:
也可以使用strftime函數將datetime物件轉換回特定格式的字串表示。
t = datetime.datetime.now()
t_string = t.strftime("%m/%d/%Y, %H:%M:%S")
#12/26/2022, 14:38:47
t_string = t.strftime("%b/%d/%Y, %H:%M:%S")
#Dec/26/2022, 14:39:32Unix時間(POSIX時間或epoch時間)是一種將時間表示為單一數值的系統。它表示自1970年1月1日星期四00:00:00協調世界時(UTC)以來經過的秒數。
Unix時間和時間戳通常可以互換使用。 Unix時間是建立時間戳記的標準版本。一般情況下使用整數或浮點數資料型別用於儲存時間戳記和Unix時間。
我們可以使用time模組的mktime方法將datetime物件轉換為Unix時間整數。也可以使用datetime模組的fromtimestamp方法。
#convert datetime to unix time import time from datetime import datetime t = datetime.now() unix_t = int(time.mktime(t.timetuple())) #1672055277 #convert unix time to datetime unix_t = 1672055277 t = datetime.fromtimestamp(unix_t) #2022-12-26 14:47:57
使用dateutil模組來解析日期字串來取得datetime物件。
from dateutil import parser
date = parser.parse("29th of October, 1923")
#datetime.datetime(1923, 10, 29, 0, 0)Pandas
Pandas提供了三種日期資料類型:
#1、Timestamp或DatetimeIndex:它的功能類似於其他索引類型,但也具有用於時間序列操作的專門函數。
t = pd.to_datetime("29/10/1923", dayfirst=True)
#Timestamp('1923-10-29 00:00:00')
t = pd.Timestamp('2019-01-01', tz = 'Europe/Berlin')
#Timestamp('2019-01-01 00:00:00+0100', tz='Europe/Berlin')
t = pd.to_datetime(["04/23/1920", "10/29/1923"])
#DatetimeIndex(['1920-04-23', '1923-10-29'], dtype='datetime64[ns]', freq=None)2、period或PeriodIndex:一個有開始和結束的時間間隔。它由固定的間隔組成。
t = pd.to_datetime(["04/23/1920", "10/29/1923"])
period = t.to_period("D")
#PeriodIndex(['1920-04-23', '1923-10-29'], dtype='period[D]')3、Timedelta或TimedeltaIndex:兩個日期之間的時間間隔。
delta = pd.TimedeltaIndex(data =['1 days 03:00:00', '2 days 09:05:01.000030']) """ TimedeltaIndex(['1 days 02:00:00', '1 days 06:05:01.000030'], dtype='timedelta64[ns]', freq=None) """
在Pandas中,可以使用to_datetime方法將物件轉換為datetime資料類型或進行任何其他轉換。
import pandas as pd
df = pd.read_csv("dataset.txt")
df.head()
"""
date value
0 1991-07-01 3.526591
1 1991-08-01 3.180891
2 1991-09-01 3.252221
3 1991-10-01 3.611003
4 1991-11-01 3.565869
"""
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null object
1 value 204 non-null float64
dtypes: float64(1), object(1)
memory usage: 3.3+ KB
"""
# Convert to datetime
df["date"] = pd.to_datetime(df["date"], format = "%Y-%m-%d")
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""
# Convert to Unix
df['unix_time'] = df['date'].apply(lambda x: x.timestamp())
df.head()
"""
date value unix_time
0 1991-07-01 3.526591 678326400.0
1 1991-08-01 3.180891 681004800.0
2 1991-09-01 3.252221 683683200.0
3 1991-10-01 3.611003 686275200.0
4 1991-11-01 3.565869 688953600.0
"""
df["date_converted_from_unix"] = pd.to_datetime(df["unix_time"], unit = "s")
df.head()
"""
date value unix_time date_converted_from_unix
0 1991-07-01 3.526591 678326400.0 1991-07-01
1 1991-08-01 3.180891 681004800.0 1991-08-01
2 1991-09-01 3.252221 683683200.0 1991-09-01
3 1991-10-01 3.611003 686275200.0 1991-10-01
4 1991-11-01 3.565869 688953600.0 1991-11-01
"""我們也可以使用parse_dates參數在任何檔案載入時直接宣告日期列。
df = pd.read_csv("dataset.txt", parse_dates=["date"])
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""如果是單一時間序列的數據,最好將日期列作為資料集的索引。
df.set_index("date",inplace=True)
"""
Value
date
1991-07-01 3.526591
1991-08-01 3.180891
1991-09-01 3.252221
1991-10-01 3.611003
1991-11-01 3.565869
... ...
2008-02-01 21.654285
2008-03-01 18.264945
2008-04-01 23.107677
2008-05-01 22.912510
2008-06-01 19.431740
"""Numpy也有自己的datetime型別np.Datetime64。特別是在大型資料集時,向量化是非常有用的,應該優先使用。
import numpy as np
arr_date = np.array('2000-01-01', dtype=np.datetime64)
arr_date
#array('2000-01-01', dtype='datetime64[D]')
#broadcasting
arr_date = arr_date + np.arange(30)
"""
array(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
'2000-01-05', '2000-01-06', '2000-01-07', '2000-01-08',
'2000-01-09', '2000-01-10', '2000-01-11', '2000-01-12',
'2000-01-13', '2000-01-14', '2000-01-15', '2000-01-16',
'2000-01-17', '2000-01-18', '2000-01-19', '2000-01-20',
'2000-01-21', '2000-01-22', '2000-01-23', '2000-01-24',
'2000-01-25', '2000-01-26', '2000-01-27', '2000-01-28',
'2000-01-29', '2000-01-30'], dtype='datetime64[D]')
"""有用的函數
下面列出的是一些可能對時間序列有用的函數。
df = pd.read_csv("dataset.txt", parse_dates=["date"])
df["date"].dt.day_name()
"""
0 Monday
1 Thursday
2 Sunday
3 Tuesday
4 Friday
...
199 Friday
200 Saturday
201 Tuesday
202 Thursday
203 Sunday
Name: date, Length: 204, dtype: object
"""DataReader
Pandas_datareader是pandas函式庫的一個輔助函式庫。它提供了許多常見的金融時間序列資料。
#pip install pandas-datareader from pandas_datareader import wb #GDP per Capita From World Bank df = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'FR', 'GB', 'DK', 'NO'], start=1960, end=2019) """ NY.GDP.PCAP.KD country year Denmark 2019 57203.027794 2018 56563.488473 2017 55735.764901 2016 54556.068955 2015 53254.856370 ... ... United States 1964 21599.818705 1963 20701.269947 1962 20116.235124 1961 19253.547329 1960 19135.268182 [300 rows x 1 columns] """
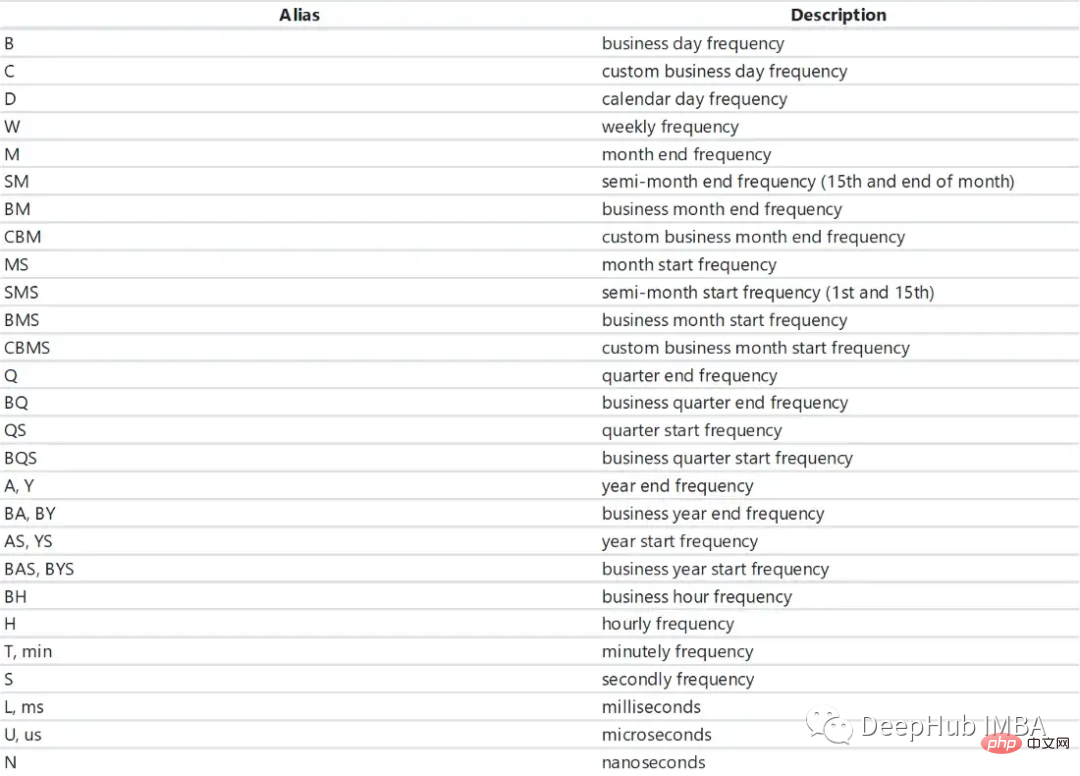
日期範圍
我們可以使用pandas的date_range方法定義一個日期範圍。
pd.date_range(start="2021-01-01", end="2022-01-01", freq="D")
"""
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
'2021-01-09', '2021-01-10',
...
'2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26',
'2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30',
'2021-12-31', '2022-01-01'],
dtype='datetime64[ns]', length=366, freq='D')
"""
pd.date_range(start="2021-01-01", end="2022-01-01", freq="BM")
"""
DatetimeIndex(['2021-01-29', '2021-02-26', '2021-03-31', '2021-04-30',
'2021-05-31', '2021-06-30', '2021-07-30', '2021-08-31',
'2021-09-30', '2021-10-29', '2021-11-30', '2021-12-31'],
dtype='datetime64[ns]', freq='BM')
"""
fridays= pd.date_range('2022-11-01', '2022-12-31', freq="W-FRI")
"""
DatetimeIndex(['2022-11-04', '2022-11-11', '2022-11-18', '2022-11-25',
'2022-12-02', '2022-12-09', '2022-12-16', '2022-12-23',
'2022-12-30'],
dtype='datetime64[ns]', freq='W-FRI')
"""
我們可以使用timedelta_range方法來建立一個時間序列。
t = pd.timedelta_range(0, periods=10, freq="H") """ TimedeltaIndex(['0 days 00:00:00', '0 days 01:00:00', '0 days 02:00:00', '0 days 03:00:00', '0 days 04:00:00', '0 days 05:00:00', '0 days 06:00:00', '0 days 07:00:00', '0 days 08:00:00', '0 days 09:00:00'], dtype='timedelta64[ns]', freq='H') """
格式化
我們dt.strftime方法改變日期列的格式。
df["new_date"] = df["date"].dt.strftime("%b %d, %Y")
df.head()
"""
date value new_date
0 1991-07-01 3.526591 Jul 01, 1991
1 1991-08-01 3.180891 Aug 01, 1991
2 1991-09-01 3.252221 Sep 01, 1991
3 1991-10-01 3.611003 Oct 01, 1991
4 1991-11-01 3.565869 Nov 01, 1991
"""解析
解析datetime物件並取得日期的子物件。
df["year"] = df["date"].dt.year df["month"] = df["date"].dt.month df["day"] = df["date"].dt.day df["calendar"] = df["date"].dt.date df["hour"] = df["date"].dt.time df.head() """ date value year month day calendar hour 0 1991-07-01 3.526591 1991 7 1 1991-07-01 00:00:00 1 1991-08-01 3.180891 1991 8 1 1991-08-01 00:00:00 2 1991-09-01 3.252221 1991 9 1 1991-09-01 00:00:00 3 1991-10-01 3.611003 1991 10 1 1991-10-01 00:00:00 4 1991-11-01 3.565869 1991 11 1 1991-11-01 00:00:00 """
也可以重新組合它們。
df["date_joined"] = pd.to_datetime(df[["year","month","day"]]) print(df["date_joined"]) """ 0 1991-07-01 1 1991-08-01 2 1991-09-01 3 1991-10-01 4 1991-11-01 ... 199 2008-02-01 200 2008-03-01 201 2008-04-01 202 2008-05-01 203 2008-06-01 Name: date_joined, Length: 204, dtype: datetime64[ns]
過濾查詢
使用loc方法來過濾DataFrame。
df = df.loc["2021-01-01":"2021-01-10"]
truncate 可以查詢兩個時間間隔中的資料
df_truncated = df.truncate('2021-01-05', '2022-01-10')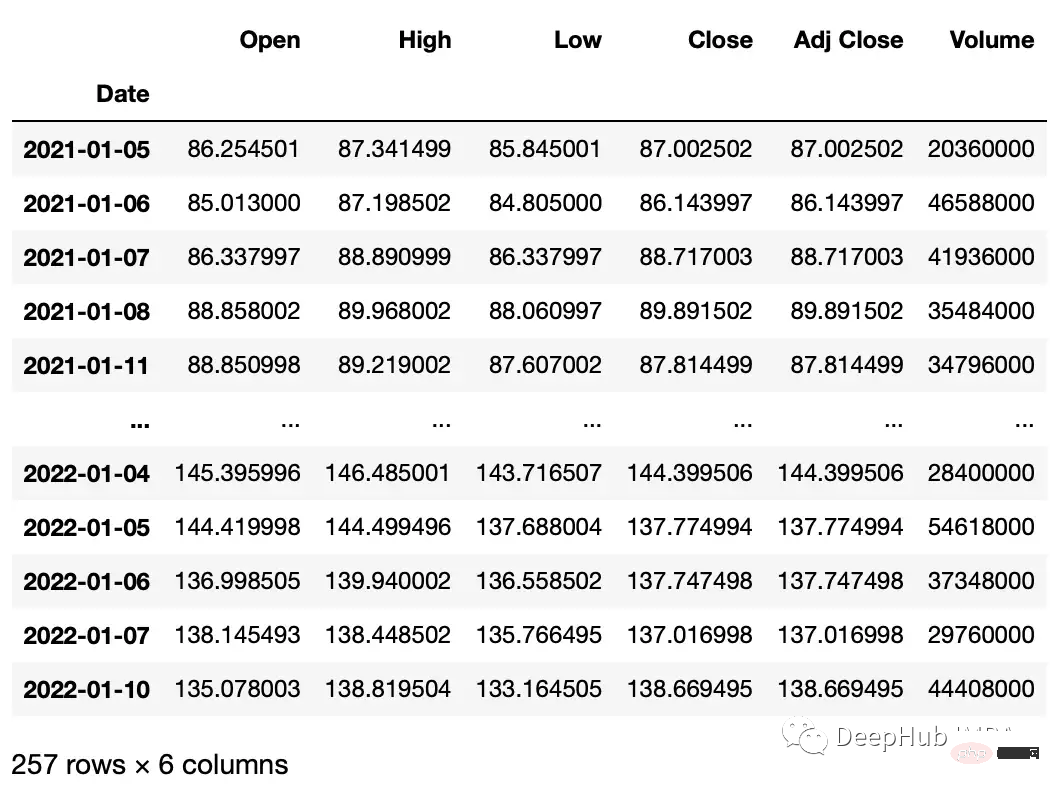
常見資料運算
下面就是對時間序列資料集中的值執行操作。我們使用yfinance庫建立一個用於範例的股票資料集。
#get google stock price data import yfinance as yf start_date = '2020-01-01' end_date = '2023-01-01' ticker = 'GOOGL' df = yf.download(ticker, start_date, end_date) df.head() """ Date Open High Low Close Adj Close Volume 2020-01-02 67.420502 68.433998 67.324501 68.433998 68.433998 27278000 2020-01-03 67.400002 68.687500 67.365997 68.075996 68.075996 23408000 2020-01-06 67.581497 69.916000 67.550003 69.890503 69.890503 46768000 2020-01-07 70.023003 70.175003 69.578003 69.755501 69.755501 34330000 2020-01-08 69.740997 70.592499 69.631500 70.251999 70.251999 35314000 """
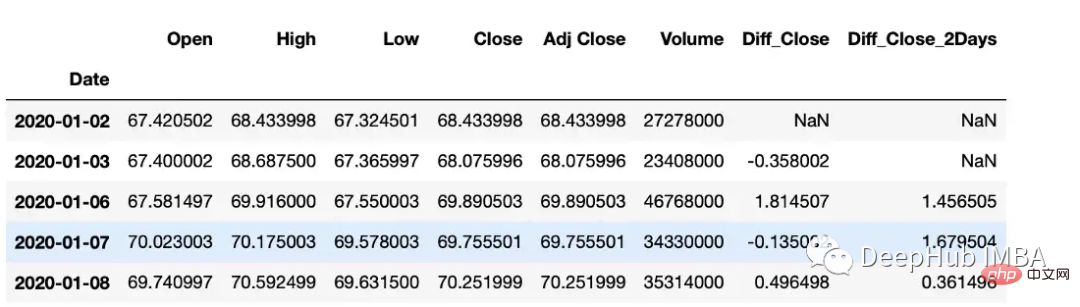
計算差值
diff函數可以計算一個元素與另一個元素之間的內插。
#subtract that day's value from the previous day df["Diff_Close"] = df["Close"].diff() #Subtract that day's value from the day's value 2 days ago df["Diff_Close_2Days"] = df["Close"].diff(periods=2)
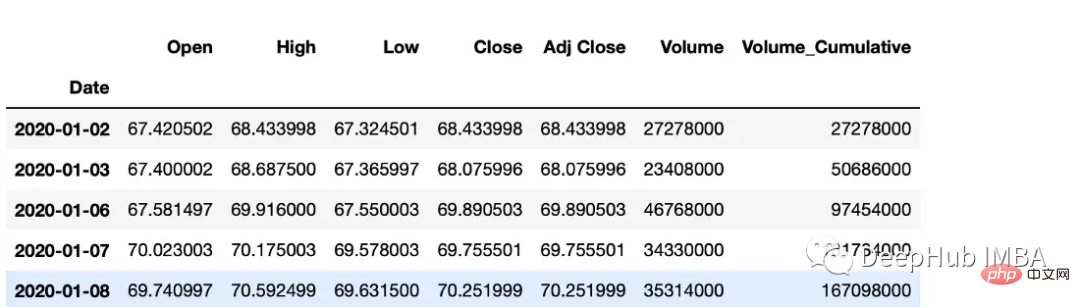
累计总数
df["Volume_Cumulative"] = df["Volume"].cumsum()
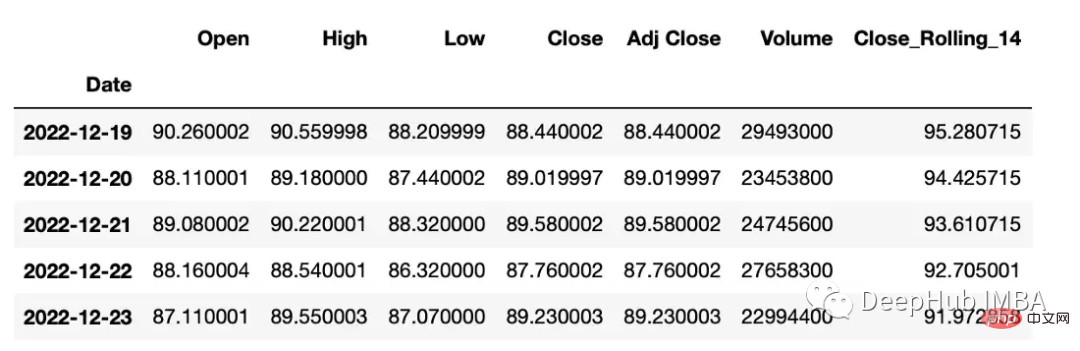
滚动窗口计算
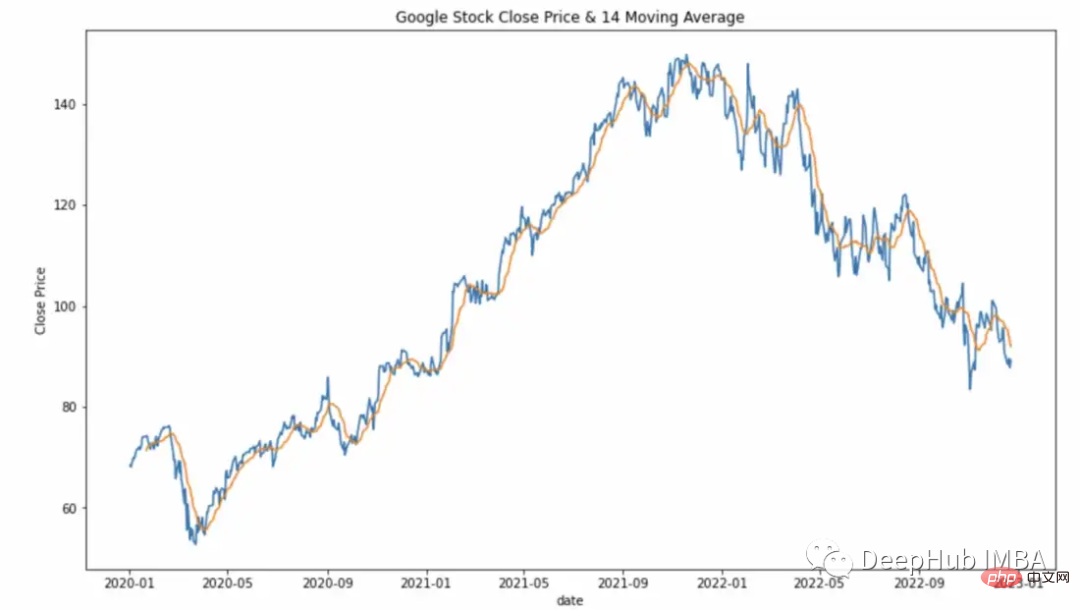
滚动窗口计算(移动平均线)。
df["Close_Rolling_14"] = df["Close"].rolling(14).mean() df.tail()
可以对我们计算的移动平均线进行可视化
常用的参数:
- center:决定滚动窗口是否应以当前观测值为中心。
- min_periods:窗口中产生结果所需的最小观测次数。
s = pd.Series([1, 2, 3, 4, 5]) #the rolling window will be centered on each observation rolling_mean = s.rolling(window=3, center=True).mean() """ 0 NaN 1 2.0 2 3.0 3 4.0 4 NaN dtype: float64 Explanation: first window: [na 1 2] = na second window: [1 2 3] = 2 """ # the rolling window will not be centered, #and will instead be anchored to the left side of the window rolling_mean = s.rolling(window=3, center=False).mean() """ 0 NaN 1 NaN 2 2.0 3 3.0 4 4.0 dtype: float64 Explanation: first window: [na na 1] = na second window: [na 1 2] = na third window: [1 2 3] = 2 """
平移
Pandas有两个方法,shift()和tshift(),它们可以指定倍数移动数据或时间序列的索引。Shift()移位数据,而tshift()移位索引。
#shift the data df_shifted = df.shift(5,axis=0) df_shifted.head(10) #shift the indexes df_tshifted = df.tshift(periods = 4, freq = 'D') df_tshifted.head(10)
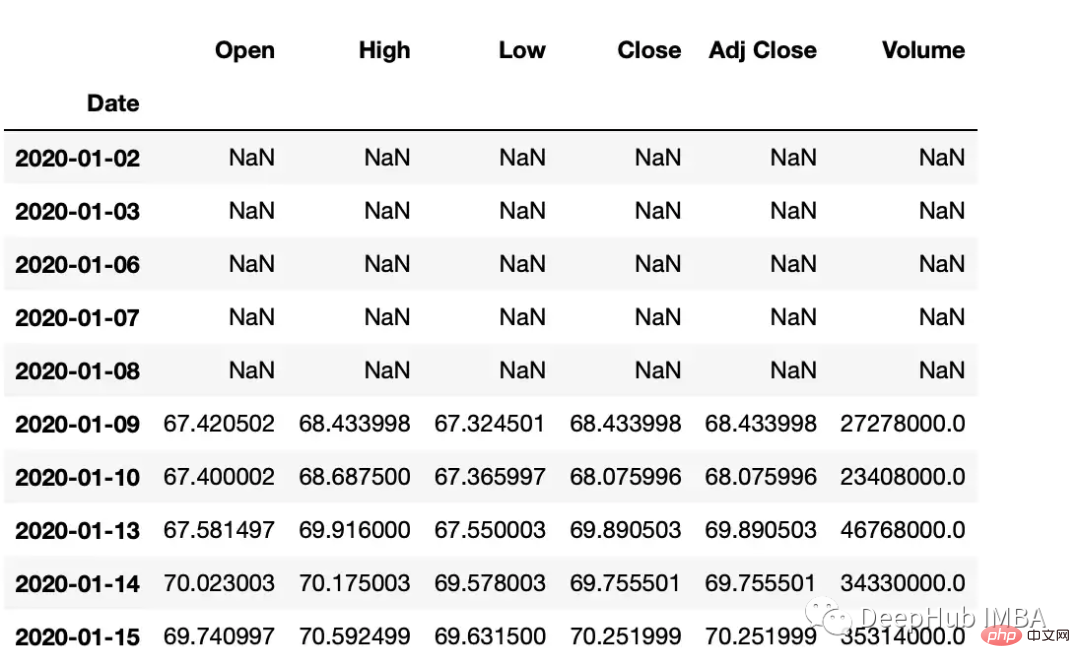
df_shifted
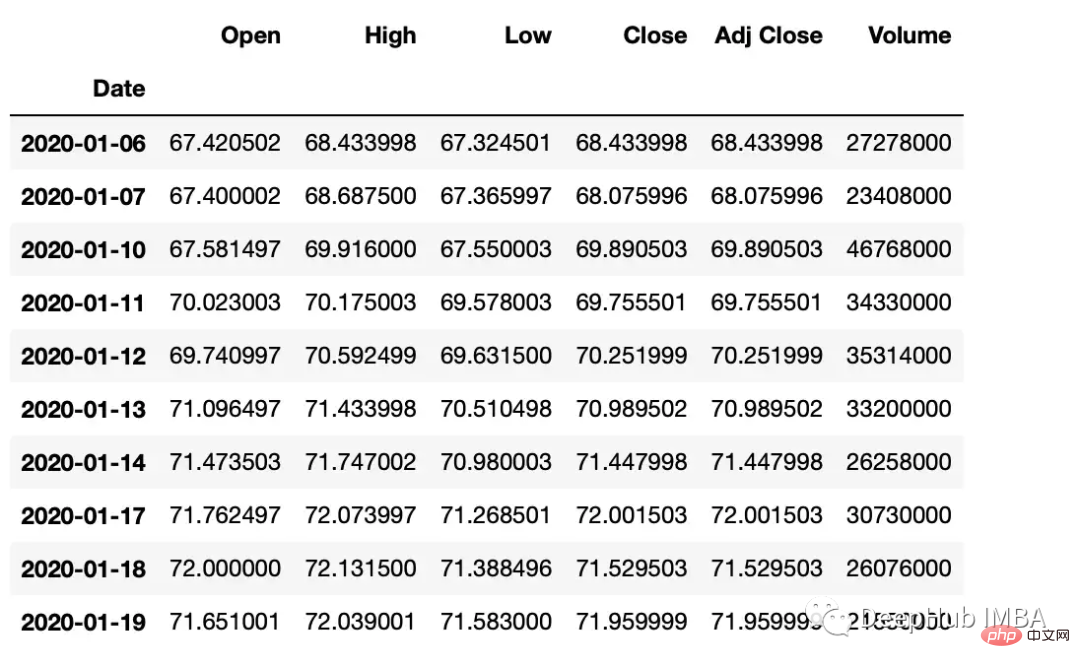
df_tshifted
时间间隔转换
在 Pandas 中,操 to_period 函数允许将日期转换为特定的时间间隔。可以获取具有许多不同间隔或周期的日期
df["Period"] = df["Date"].dt.to_period('W')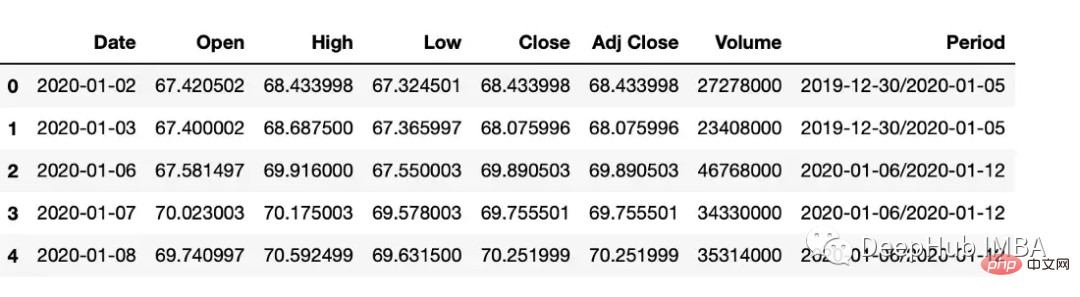
频率
Asfreq方法用于将时间序列转换为指定的频率。
monthly_data = df.asfreq('M', method='ffill')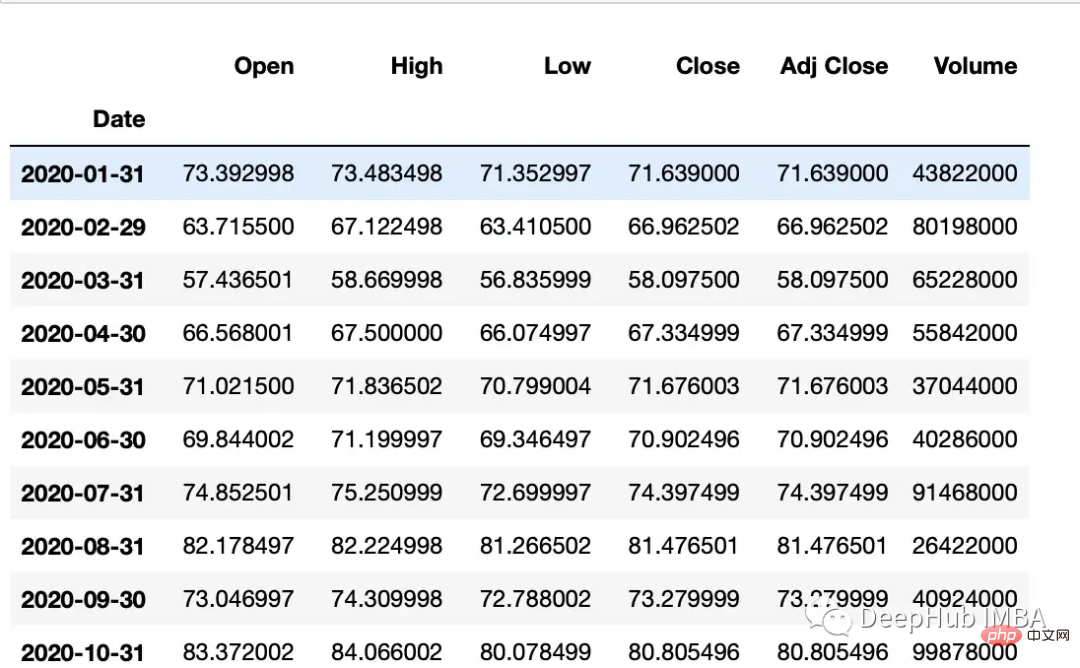
常用参数:
freq:数据应该转换到的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
method:如何在转换频率时填充缺失值。这可以是'ffill'(向前填充)或'bfill'(向后填充)之类的字符串。
采样
resample可以改变时间序列频率并重新采样。我们可以进行上采样(到更高的频率)或下采样(到更低的频率)。因为我们正在改变频率,所以我们需要使用一个聚合函数(比如均值、最大值等)。
resample方法的参数:
rule:数据重新采样的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
#down sample
monthly_data = df.resample('M').mean()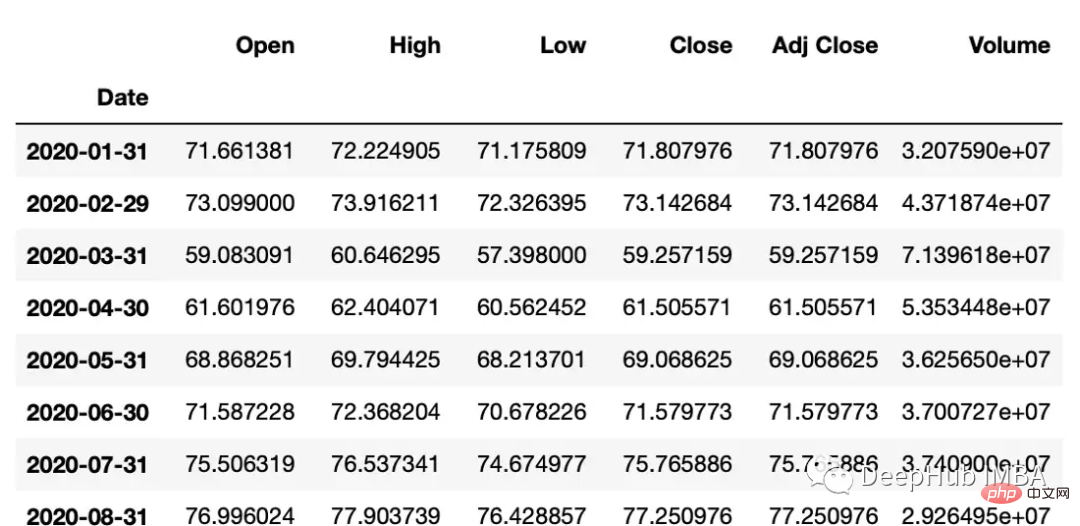
#up sample
minute_data = data.resample('T').ffill()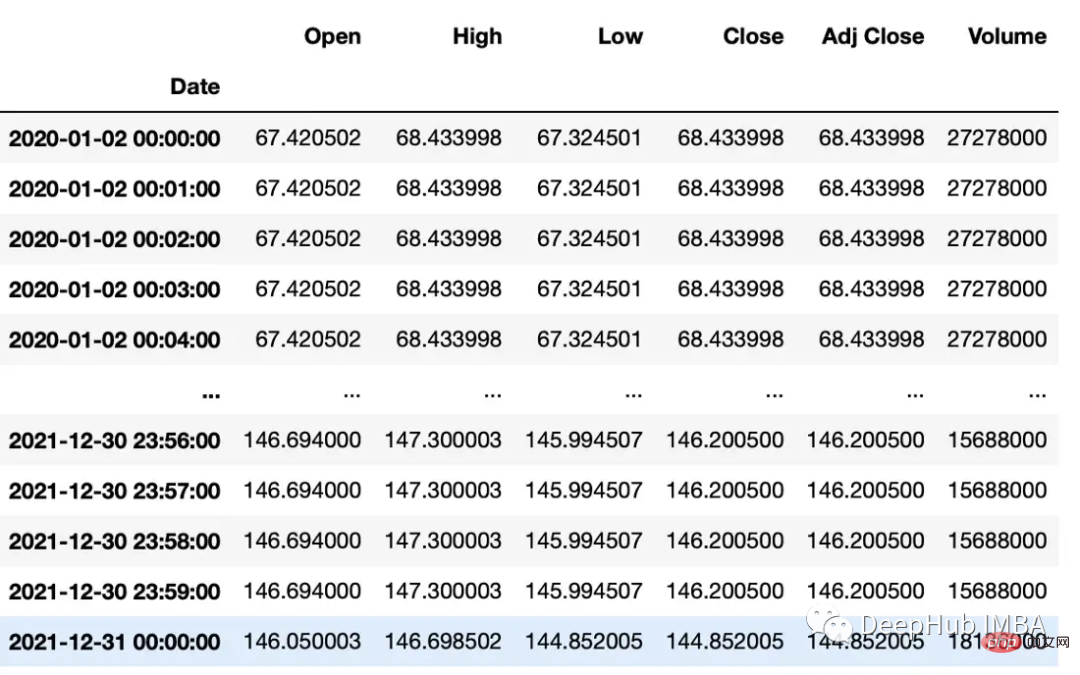
百分比变化
使用pct_change方法来计算日期之间的变化百分比。
df["PCT"] = df["Close"].pct_change(periods=2) print(df["PCT"]) """ Date 2020-01-02 NaN 2020-01-03 NaN 2020-01-06 0.021283 2020-01-07 0.024671 2020-01-08 0.005172 ... 2022-12-19 -0.026634 2022-12-20 -0.013738 2022-12-21 0.012890 2022-12-22 -0.014154 2022-12-23 -0.003907 Name: PCT, Length: 752, dtype: float64 """
总结
在Pandas和NumPy等库的帮助下,可以对时间序列数据执行广泛的操作,包括过滤、聚合和转换。本文介绍的是一些在工作中经常遇到的常见操作,希望对你有所帮助。
以上是Python時間序列資料操作的常用方法總結的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
 CentOS上PyTorch版本怎麼選
Apr 14, 2025 pm 06:51 PM
CentOS上PyTorch版本怎麼選
Apr 14, 2025 pm 06:51 PM
在CentOS系統上安裝PyTorch,需要仔細選擇合適的版本,並考慮以下幾個關鍵因素:一、系統環境兼容性:操作系統:建議使用CentOS7或更高版本。 CUDA與cuDNN:PyTorch版本與CUDA版本密切相關。例如,PyTorch1.9.0需要CUDA11.1,而PyTorch2.0.1則需要CUDA11.3。 cuDNN版本也必須與CUDA版本匹配。選擇PyTorch版本前,務必確認已安裝兼容的CUDA和cuDNN版本。 Python版本:PyTorch官方支
 CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
在CentOS上更新PyTorch到最新版本,可以按照以下步驟進行:方法一:使用pip升級pip:首先確保你的pip是最新版本,因為舊版本的pip可能無法正確安裝最新版本的PyTorch。 pipinstall--upgradepip卸載舊版本的PyTorch(如果已安裝):pipuninstalltorchtorchvisiontorchaudio安裝最新
