
上週,OpenAI發布的ChatGPT API和Whisper API,剛剛引來了一場開發者的狂歡。
3月6日,Google就推出了對標的模型-USM。不僅可以支援100多種語言,而且參數量也達到了20億。
當然了,模型仍然沒有對外開放,「這很Google」!
#簡單來說,USM模型在涵蓋1200萬小時語音、280億個句子和300種不同語言的無標註資料集中進行了預訓練,並在較小的標註訓練集中進行了微調。
Google的研究人員表示,雖然用於微調的標註訓練集僅有Whisper的1/7,但USM卻有著與其相當甚至更好的性能,並且還能夠有效地適應新的語言和數據。

#論文網址:https://arxiv.org/abs/2303.01037
結果顯示,USM不僅在多語言自動語音辨識和語音-文字翻譯任務評測中實現了SOTA,而且還可以實際用在YouTube的字幕生成上。
目前,支援自動偵測和翻譯的語種包括,主流的英語、漢語,以及阿薩姆語這類的小語種。
最重要的是,還能用於Google去年IO大會展示的未來AR眼鏡的即時翻譯。

當微軟和谷歌就誰家擁有更好的AI聊天機器人爭論不休時,要知道,大型語言模型的用途可不僅於此。
去年11月,Google先宣布了新計畫「開發一種支援全球1000種最常用語言的人工智慧語言模型」。

#同年,Meta也發表了一個名為「No Language Left Behind」模型,並稱可以翻譯200多種語言,旨在打造「通用翻譯器」。
而最新模型的發布,Google將其描述為通往目標的「關鍵一步」。
在打造語言模型上,可謂群雄逐鹿。
據傳言,Google計劃在今年的年度 I/O 大會上展示20多款由人工智慧驅動的產品。
目前,自動語音辨識面臨許多挑戰:
在傳統的方法中,音訊資料需要費時又費錢的手動標記,或從有預先存在的轉錄的來源中收集,而對於缺乏廣泛代表性的語言來說,這很難找到。 #
##這就要求演算法能夠使用來自不同來源的大量數據,在不需要完全重新訓練的情況下實現模型的更新,並且能夠推廣到新的語言和使用案例。
微調自監督學習根據論文介紹,USM的訓練採用了三種資料庫:未配對的音訊資料集、未配對的文本資料集、配對的ASR語料庫。
#包括YT-NTL-U(超1200萬小時YouTube無標籤音訊資料)和Pub-U(超429,000小時的51種語言的演講內容)
#Web-NTL(超1140種不同語言的280億個句子)
#YT-SUP 和Pub-S語料庫(超10,000小時的音訊內容和配對文字)

USM使用標準的編碼器-解碼器結構,其中解碼器可以是CTC、RNN -T或LAS。
對於編碼器,USM使用了Conformor,或卷積增強Transformer。
訓練過程共分為三個階段。
在初始階段,使用BEST-RQ(基於BERT的隨機投影量化器的語音預訓練)進行無監督的預訓練。目標是為了優化RQ。
在下一階段,進一步訓練語音表徵學習模型。
使用MOST(多目標監督預訓練)來整合來自其他文字資料的資訊。
該模型引入了一個額外的編碼器模組,以文字作為輸入,並引入了額外的層來組合語音編碼器和文字編碼器的輸出,並在未標記的語音、標記的語音和文字資料上聯合訓練模型。
最後一步是,對ASR(自動語音辨識)和AST(自動語音翻譯)任務進行微調,經過預訓練的USM模型只需少量監督數據就可以取得很好的效能。
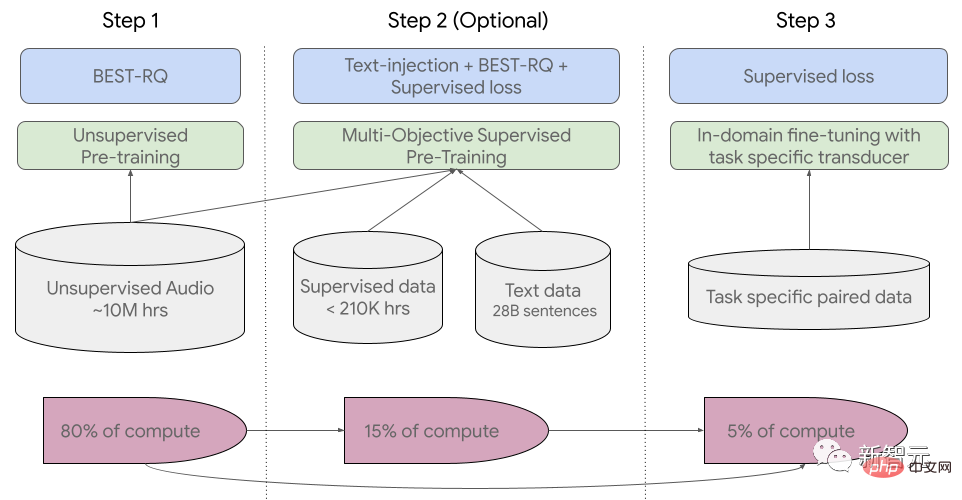
USM整體訓練流程
USM的表現如何,Google對其在YouTube字幕、下游ASR任務的推廣、以及自動語音翻譯上進行了測試。
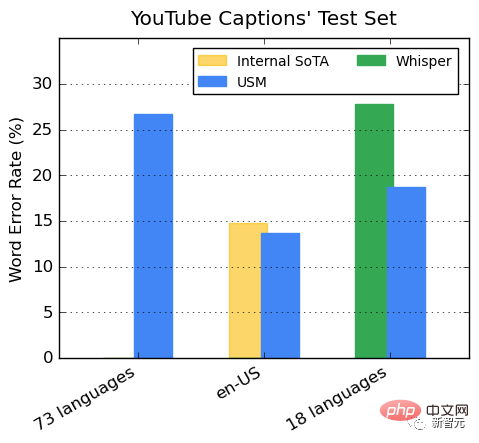
YouTube多國語言字幕上的表現#
受監督的YouTube資料包括73種語言,每種語言的資料時長平均不到3000小時。儘管監督數據有限,但模型在73種語言中實現了平均不到30%的單字錯誤率(WER),這比美國內部最先進的模型相比還要低。
此外,Google與超40萬小時標註資料訓練出的Whisper模型 (big-v2) 進行了比較。
在Whisper能解碼的18種語言中,其解碼錯誤率低於40%,而USM平均錯誤率僅32.7%。
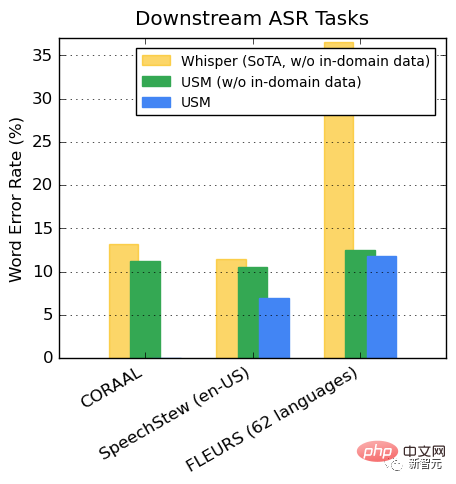
#對下游ASR任務的推廣
#在公開的資料集上,與Whisper相比,USM在CORAAL(非裔美國人的方言英語)、SpeechStew(英文-美國)和FLEURS(102種語言)上顯示出更低的WER,不論是否有域內訓練資料。
兩種模型在FLEURS上的差異尤其明顯。
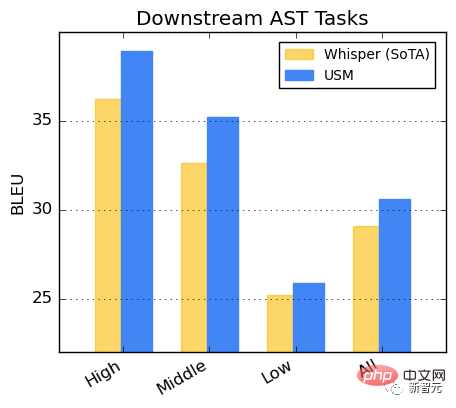
#在AST任務上的表現
在CoVoST資料集上對USM進行微調。
將資料集中的語言依資源可用性分為高、中、低三類,在每一類上計算BLEU分數(越高越好) ,USM在每一類的表現的優於Whisper。
研究發現,BEST-RQ預訓練是將語音表徵學習擴展到大資料集的有效方法。
當與MOST中的文字注入相結合時,它提高了下游語音任務的質量,在FLEURS和CoVoST 2基準上實現了最好的性能。
透過訓練輕量級剩餘適配器模組,MOST表示能夠快速適應新的領域。而這些剩餘適配器模組只增加2%的參數。
#Google稱,目前,USM支援100多種語言,到未來將擴展到1000多種語言。有了這項技術,或許對於每個人來講走到世界各地都穩妥了。
甚至,未來即時翻譯GoogleAR眼鏡產品將會吸引眾多粉絲。
不過,現在這項技術的應用還是有很長的路要走。
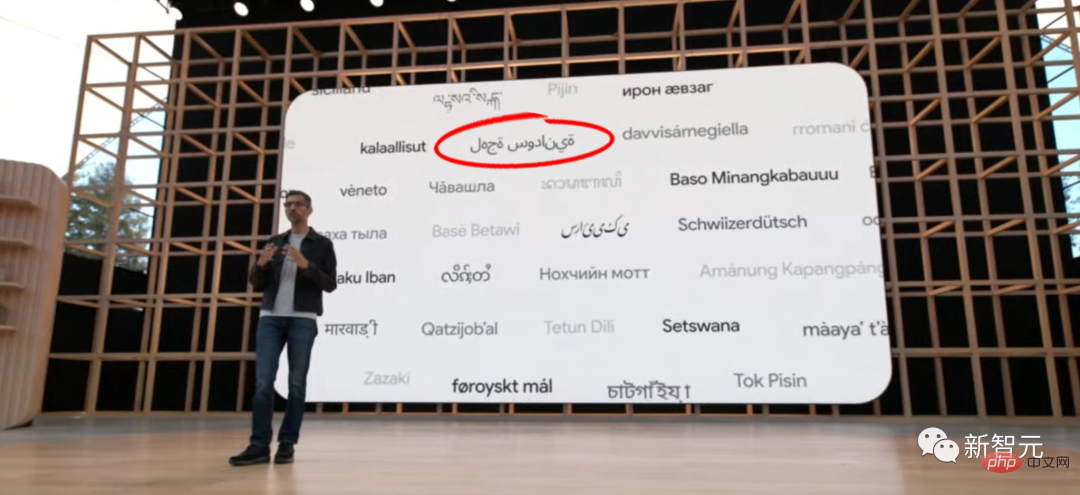
畢竟在面向世界的IO大會演講中,Google還把阿拉伯文寫反了,引來眾多網友圍觀。
以上是再勝OpenAI!谷歌發布20億參數通用模型,100多種語言自動辨識翻譯的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















