

TPU 與 GPU:實際場景下效能與速度的比較差異

在本文中,我們將進行 TPU 與 GPU 的比較。但在我們深入研究之前,這是你必須知道的。
機器學習和人工智慧技術加速了智慧應用的發展。為此,半導體公司不斷創建加速器和處理器,包括 TPU 和 CPU,以處理更複雜的應用程式。
一些用戶在理解何時建議使用 TPU 以及何時使用 GPU 來完成他們的電腦任務時遇到了問題。
GPU 也稱為圖形處理單元,是您 PC 的視訊卡,可為您提供視覺和身臨其境的 PC 體驗。例如,如果您的PC 未偵測到 GPU ,您可以按照簡單的步驟操作。
為了更好地理解這些情況,我們還需要澄清什麼是 TPU 以及它與 GPU 的比較。
什麼是 TPU?
TPU 或張量處理單元是用於特定應用的專用積體電路 (IC),也稱為 ASIC(專用積體電路)。 Google 從頭開始創建 TPU,於 2015 年開始使用,並於 2018 年向公眾開放。

TPU 作為次要晶片或雲端版本提供。為了使用 TensorFlow 軟體加速神經網路的機器學習,雲端 TPU 以驚人的速度解決複雜的矩陣和向量運算。
借助 TensorFlow,Google Brain 團隊開發了一個開源機器學習平台,研究人員、開發人員和企業可以使用 Cloud TPU 硬體建立和操作 AI 模型。
在訓練複雜且穩健的神經網路模型時,TPU 會縮短達到準確值的時間。這意味著使用 GPU 訓練可能需要數週時間的深度學習模型所花費的時間不到此時間的一小部分。
TPU 和 GPU 一樣嗎?
它們在架構上是高度不同的。圖形處理單元本身就是一個處理器,儘管它是透過管道傳輸到向量化數值編程的。 GPU 實際上是下一代 Cray 超級電腦。
TPU 是不自行執行指令的協處理器;程式碼在 CPU 上執行,它為 TPU 提供小操作流。
我什麼時候應該使用 TPU?
雲端中的 TPU 是針對特定應用程式量身定制的。在某些情況下,您可能會喜歡使用 GPU 或 CPU 執行機器學習任務。一般來說,以下原則可以幫助您評估TPU 是否是您工作負載的最佳選擇:
- 矩陣運算在模型中占主導地位
- 在模型的主訓練循環中,沒有自訂TensorFlow 操作
- 他們是經過數週或數月訓練的模特兒
- 它們是具有廣泛、有效批量大小的大型模型。
現在讓我們直接進行 TPU 與 GPU 的比較。
GPU和TPU有什麼差別?
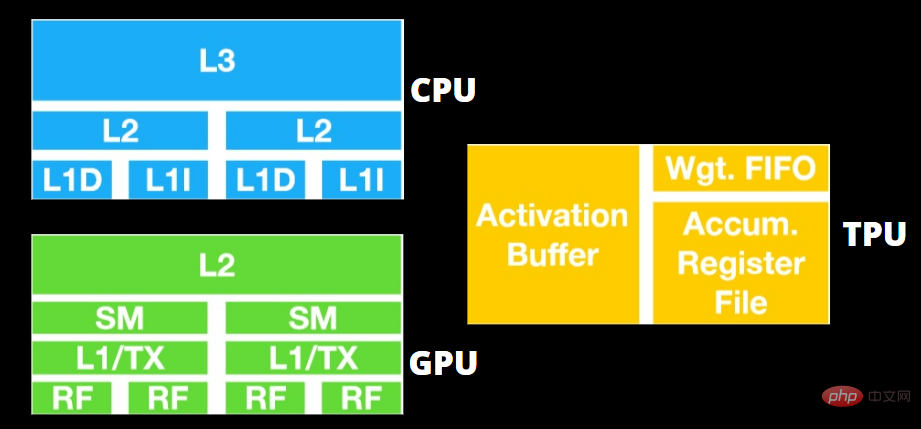
TPU 與 GPU 架構
TPU 不是高度複雜的硬件,感覺就像是用於雷達應用的訊號處理引擎,而不是傳統的 X86 衍生架構。
儘管有許多矩陣乘法除法,但它更像是一個協處理器而不是 GPU;它只執行主機收到的命令。
由於要輸入到矩陣乘法組件的權重太多,因此 TPU 的 DRAM 會作為單一單元並行運作。
此外,由於 TPU 只能進行矩陣運算,因此 TPU 板與基於 CPU 的主機系統相連,以完成 TPU 無法處理的任務。
主機負責將資料傳送到 TPU、預處理以及從雲端儲存中取得詳細資訊。
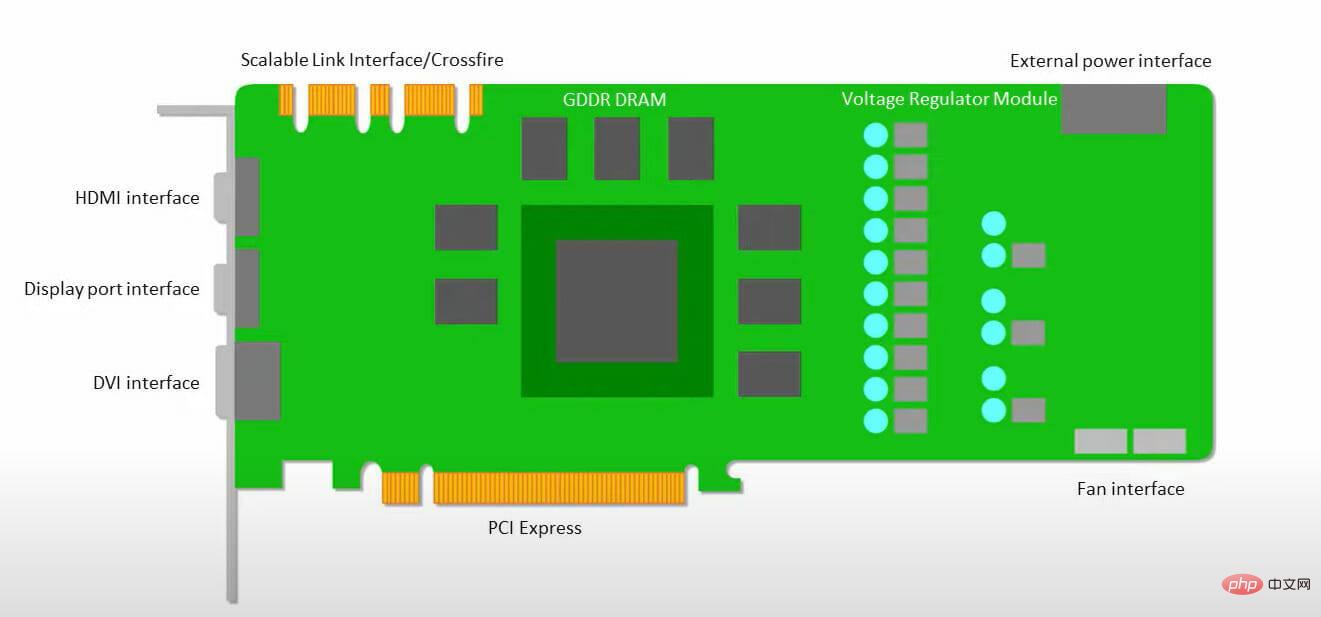
GPU 更關心應用程式可用核心來運作,而不是存取低延遲快取。
許多具有多個 SM(串流多處理器)的 PC(處理器叢集)成為單一 GPU 小工具,每個 SM 中都包含第一層指令快取層和隨附的核心。
在從全域 GDDR-5 記憶體中提取資料之前,一個 SM 通常使用兩個快取的共享層和一個快取的專用層。 GPU 架構可以容忍記憶體延遲。
GPU 以最少數量的記憶體快取等級運作。但是,由於 GPU 具有更多專用於處理的晶體管,因此它不太關心存取記憶體中資料的時間。
由於 GPU 一直被足夠的運算佔用,可能的記憶體存取延遲被隱藏了。
TPU 與 GPU 速度
這個原始的 TPU 產生有針對性的推理,它使用學習模型而不是訓練模型。
在使用神經網路推理的商業 AI 應用程式上,TPU 比目前的 GPU 和 CPU 快 15 到 30 倍。
此外,TPU 非常節能,TOPS/Watt 值增加了 30 到 80 倍。
因此,在進行 TPU 與 GPU 速度比較時,可能性偏向張量處理單元。
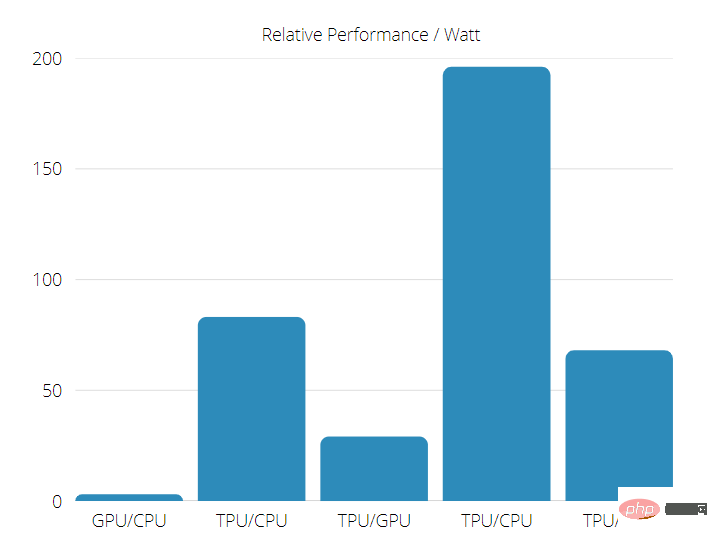
TPU 與 GPU 效能
TPU 是張量處理機器,旨在加速 Tensorflow 圖表運算。
在一塊板上,每個 TPU 可提供高達 64 GB 的高頻寬記憶體和 180 teraflops 的浮點效能。
Nvidia GPU 與 TPU 之間的比較如下所示。 Y 軸表示每秒的照片數量,而 X 軸表示各種型號。
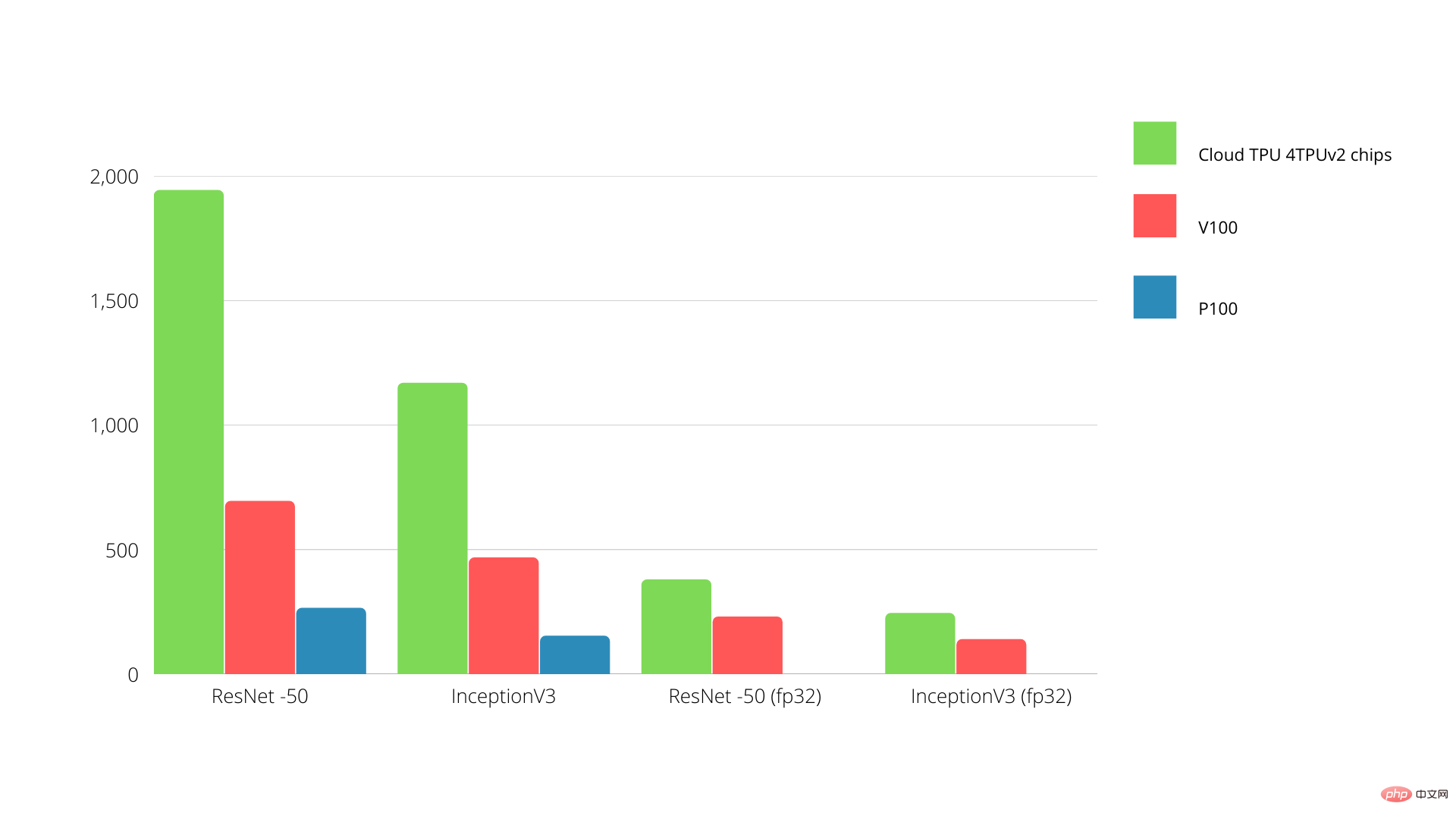
TPU 與GPU 機器學習
以下是使用不同批次大小和每個Epoch 迭代的CPU 和GPU 的訓練時間:
- 迭代次數/時期:100,批次大小:1000,總時期:25,參數:1.84 M,模型類型:Keras Mobilenet V1(alpha 0.75)。
| 加速器 | GPU (英偉達K80) | 熱塑性聚氨酯 |
| #訓練準確率(%) | 96.5 | 94.1 |
| 驗證準確率(%) | 65.1 | 68.6 |
| 每次迭代的時間(毫秒) | 69 | 173 |
- 69
| #30 | 72 | |
| Iterations/epoch: 1000, Batch size: 100, Total epochs: 25, Parameters: 1.84 M, and Model type: Keras Mobilenet V1 (alpha 0.75) | ||
| 」加速器 | GPU (英偉達K80) | #熱塑性聚氨酯 |
| 訓練準確率(%) | 97.4 | #96.9 |
| 驗證準確率(%) | 45.2 | 45.3 |
| 每次迭代的時間(毫秒) | 185 | 252 |
從訓練時間可以看出,使用較小的批次大小,TPU 需要更長的訓練時間。但是,隨著批次大小的增加,TPU 效能更接近 GPU。
因此,在進行 TPU 與 GPU 訓練比較時,很大程度上與時期和批量大小有關。
TPU 與 GPU 基準測試
憑藉 0.5 瓦/TOPS,單一 Edge TPU 每秒可以執行 4 兆次操作。有幾個變數會影響這轉化為應用程式效能的程度。
神經網路模型有不同的需求,整體輸出取決於 USB 加速器裝置的主機 USB 速度、CPU 和其他系統資源。
考慮到這一點,下圖比較了使用各種標準模型在 Edge TPU 上進行單一推理所花費的時間。當然,為了比較,所有運行的模型都是 TensorFlow Lite 版本。
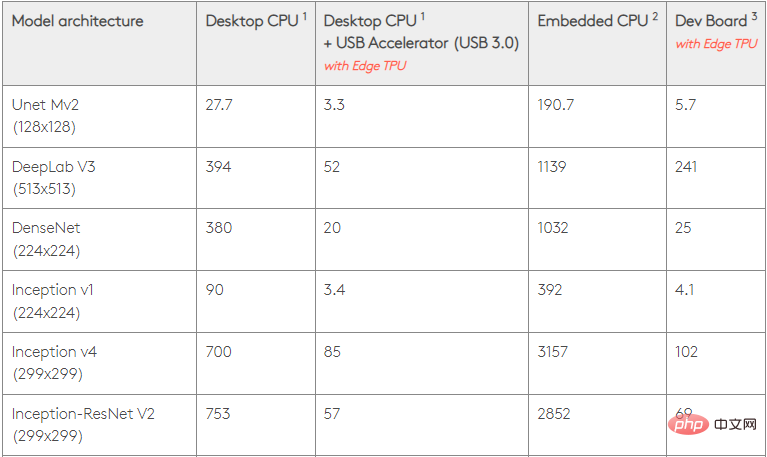
請注意,上面的給定資料顯示了運行模型所需的時間。但是,它不包括處理輸入資料所需的時間,這因應用程式和系統而異。
將 GPU 基準測試的結果與使用者期望的遊戲品質設定和解析度進行比較。
基於對超過 70,000 個基準測試的評估,我們精心構建了複雜的演算法,以產生 90% 的遊戲性能可靠估計。
儘管顯示卡的表現因遊戲而異,但下面這張比較圖給出了一些顯示卡的廣泛評級指數。
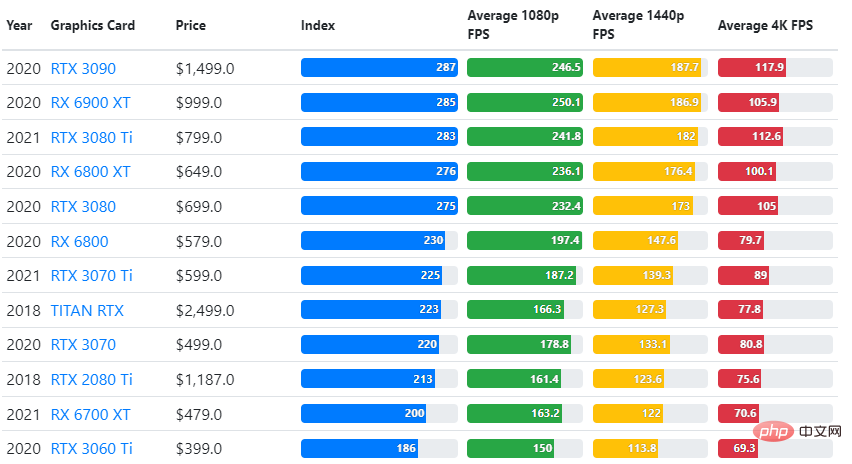
TPU 與 GPU 價格
他們有很大的價格差異。 TPU 的成本是 GPU 的五倍。這裡有些例子:
- Nvidia Tesla P100 GPU 每小時1.46 美元
- Google TPU v3 每小時收費8.00 美元
- 具有GCP 按需存取的TPUv2 每小時$4.50
如果以最佳化成本為目標,那麼只有當TPU 訓練模型的速度是GPU 的5 倍時,您才應該選擇TPU。
CPU、GPU 和 TPU 有什麼不同?
TPU、GPU 和 CPU 之間的差異在於 CPU 是一種非特定用途的處理器,它處理電腦的所有運算、邏輯、輸入和輸出。
另一方面,GPU 是一個額外的處理器,用於改進圖形介面 (GI) 並進行高階活動。 TPU 是強大的特製處理器,用於執行使用特定框架(例如 TensorFlow)開發的專案。
我們將它們分類如下:
- 中央處理器(CPU) – 控制電腦的所有面向
- 圖形處理單元(GPU) – 提高電腦的圖形效能
- 張量處理單元(TPU) – 專為TensorFlow 專案設計的ASIC
以上是TPU 與 GPU:實際場景下效能與速度的比較差異的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Beelink EX顯示卡擴充座承諾GPU效能零損失
Aug 11, 2024 pm 09:55 PM
Beelink EX顯示卡擴充座承諾GPU效能零損失
Aug 11, 2024 pm 09:55 PM
最近推出的 Beelink GTi 14 的突出特點之一是迷你 PC 下方有一個隱藏的 PCIe x8 插槽。該公司在發佈時表示,這將使外部顯示卡更容易連接到系統。 Beelink有n
 AMD FSR 3.1 推出:幀產生功能也適用於 Nvidia GeForce RTX 和 Intel Arc GPU
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 推出:幀產生功能也適用於 Nvidia GeForce RTX 和 Intel Arc GPU
Jun 29, 2024 am 06:57 AM
AMD 兌現了 24 年 3 月的最初承諾,將於今年第二季推出 FSR 3.1。 3.1 版本的真正與眾不同之處在於幀生成方面與升級方面的解耦。這使得 Nvidia 和 Intel GPU 擁有者可以應用 FSR 3。
 本地運作效能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服務,太方便了!
Apr 15, 2024 am 09:01 AM
本地運作效能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服務,太方便了!
Apr 15, 2024 am 09:01 AM
Ollama是一款超實用的工具,讓你能夠在本地輕鬆運行Llama2、Mistral、Gemma等開源模型。本文我將介紹如何使用Ollama實現對文本的向量化處理。如果你本地還沒有安裝Ollama,可以閱讀這篇文章。本文我們將使用nomic-embed-text[2]模型。它是一種文字編碼器,在短的上下文和長的上下文任務上,效能超越了OpenAItext-embedding-ada-002和text-embedding-3-small。啟動nomic-embed-text服務當你已經成功安裝好o
 PHP 陣列鍵值翻轉:不同方法的效能比較分析
May 03, 2024 pm 09:03 PM
PHP 陣列鍵值翻轉:不同方法的效能比較分析
May 03, 2024 pm 09:03 PM
PHP數組鍵值翻轉方法效能比較顯示:array_flip()函數在大型數組(超過100萬個元素)下比for迴圈效能更優,耗時更短。手動翻轉鍵值的for迴圈方法耗時相對較長。
 不同Java框架的效能對比
Jun 05, 2024 pm 07:14 PM
不同Java框架的效能對比
Jun 05, 2024 pm 07:14 PM
不同Java框架的效能比較:RESTAPI請求處理:Vert.x最佳,請求速率達SpringBoot2倍,Dropwizard3倍。資料庫查詢:SpringBoot的HibernateORM優於Vert.x及Dropwizard的ORM。快取操作:Vert.x的Hazelcast客戶端優於SpringBoot及Dropwizard的快取機制。合適框架:根據應用需求選擇,Vert.x適用於高效能Web服務,SpringBoot適用於資料密集型應用,Dropwizard適用於微服務架構。
 桌面解析度影響《黑神話:悟空》幀數下降一半? RTX 4060 幀數測試勘誤
Aug 16, 2024 am 09:35 AM
桌面解析度影響《黑神話:悟空》幀數下降一半? RTX 4060 幀數測試勘誤
Aug 16, 2024 am 09:35 AM
前幾天遊戲科學放出了《黑神話:悟空》的基準測試軟體,在測試中我們發現,當外接顯示器時(獨顯直連視訊輸出介面),如果顯示器的桌面解析度大於遊戲內的分辨率,遊戲幀數將會有非常明顯的下降,在某些情況下甚至幀數會下跌一半。於是我們重新開始進行了測試,並尋找到了原因所在,這篇文章就來對我的上一篇測試:《2種分辨率x13種畫質=26個測試結果,RTX4060在《黑神話:悟空》中的幀數到底如何? 》進行修正、勘誤,在這裡也先跟大家說一聲抱歉,RTX4060理論上來講在《黑神話:悟空》中會比我之前測試的成績高出不
 有望成為英特爾下代獨顯首發 GPU ,bmg_g21 核心率先現身 LLVM 更新
Jun 09, 2024 am 09:42 AM
有望成為英特爾下代獨顯首發 GPU ,bmg_g21 核心率先現身 LLVM 更新
Jun 09, 2024 am 09:42 AM
本站5月13日訊息,X平台人士@miktdt發現,英特爾近日向oneAPIDPC++編譯器的LLVM文件增加了bmg_g21(BattlemageG21、BMG-G21)核心相關程式碼。這也是首次有Battlemage架構獨顯相關程式碼現身該文檔,暗示BattlemageG21GPU可望成為英特爾下代獨顯首發型號。本站注意到,文件中將bmg_g21的GPU架構稱為intel_gpu_20_1_4,與據信採用核顯版Battlemage架構的lnl_m(LunarLake-M)處理器共享相同的「inte
 C++中如何優化多執行緒程式的效能?
Jun 05, 2024 pm 02:04 PM
C++中如何優化多執行緒程式的效能?
Jun 05, 2024 pm 02:04 PM
優化C++多執行緒效能的有效技術包括:限制執行緒數量,避免爭用資源。使用輕量級互斥鎖,減少爭用。優化鎖的範圍,最小化等待時間。採用無鎖定資料結構,提高並發性。避免忙等,透過事件通知執行緒資源可用性。