

分割後門訓練的後門防禦方法:DBD

香港中文大學(深圳)吳保元教授課題組和浙江大學秦湛教授課題組聯合發表了一篇後門防禦領域的文章,已順利被ICLR2022接收。
近年來,後門問題受到人們的廣泛關注。隨著後門攻擊的不斷提出,提出針對一般化後門攻擊的防禦方法變得愈加困難。該論文提出了一個基於分割後門訓練過程的後門防禦方法。
本文揭示了後門攻擊就是將後門投影到特徵空間的端對端監督訓練方法。在此基礎上,本文分割訓練過程來避免後門攻擊。該方法與其他後門防禦方法進行了比較實驗,證明了該方法的有效性。
收錄會議:ICLR2022
#文章連結:https://arxiv.org/pdf/ 2202.03423.pdf
#程式碼連結:https://github.com/SCLBD/DBD
# 1 背景介紹
後門攻擊的目標是透過修改訓練資料或控制訓練過程等方法使得模型預測正確乾淨樣本,但是對於有後門的樣本判斷為目標標籤。例如,後門攻擊者為圖片增加固定位置的白塊(即中毒圖片)並且修改圖片的標籤為目標標籤。用這些中毒資料訓練模型過後,模型就會判斷有特定白塊的圖片為目標標籤(如下圖所示)。
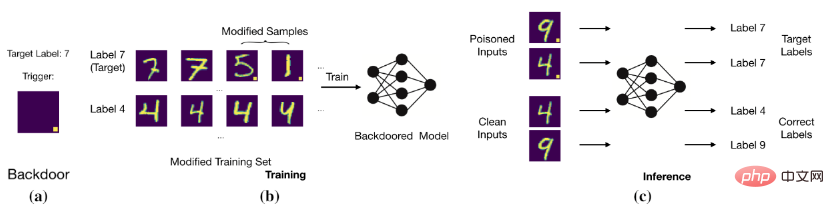 基本的後門攻擊
基本的後門攻擊
#模型建立了觸發器(trigger)和目標標籤(target label)之間的關係。
2 相關工作
2.1 後門攻擊
現有的後門攻擊方法依照中毒圖片的標籤修改情況分為以下兩類,修改中毒圖片標籤的投毒標籤攻擊(Poison-Label Backdoor Attack),維持中毒圖片原本標籤的乾淨標籤攻擊(Clean-Label Backdoor Attack)。
1.投毒標籤攻擊: BadNets (Gu et al., 2019)是第一個也是最具代表性的投毒標籤攻擊。之後(Chen et al., 2017)提出中毒圖片的隱身性應與其良性版本相似,並在此基礎上提出了混合攻擊(blended attack)。最近,(Xue et al., 2020; Li et al., 2020; 2021)進一步探討如何更隱密地進行中毒標籤後門攻擊。最近,一種更隱形和有效的攻擊,WaNet (Nguyen & Tran, 2021年)被提出。 WaNet採用影像扭曲作為後門觸發器,在變形的同時保留了影像內容。
2.乾淨標籤攻擊: 為了解決使用者可以透過檢查影像-標籤關係來注意到後門攻擊的問題,Turner等人(2019)提出了乾淨標籤攻擊範式,其中目標標籤與中毒樣本的原始標籤一致。在(Zhao et al,2020b)中將此想法推廣到攻擊影片分類中,他們採用了目標通用對抗擾動(Moosavi-Dezfooli et al., 2017)作為觸發。儘管乾淨標籤後門攻擊比投毒標籤後門攻擊更隱蔽,但它們的性能通常相對較差,甚至可能無法創建後門(Li et al., 2020c)。
2.2 後門防禦
現有的後門防禦大多是經驗性的,可分為五大類,包括
1.基於探測的防禦(Xu et al,2021;Zeng et al,2011;Xiang et al,2022)檢查可疑的模型或樣本是否受到攻擊,它將拒絕使用惡意物件。
2.基於預處理的防禦(Doan et al,2020;Li et al,2021;Zeng et al,2021)旨在破壞攻擊樣本中包含的觸發模式,透過在將影像輸入模型之前引入預處理模組來防止後門啟動。
3.基於模型重構的防禦(Zhao et al,2020a;Li et al,2021;)是透過直接修改模型來消除模型中隱藏的後門。
4.觸發綜合防禦(Guo et al,2020;Dong et al,2021;Shen et al,2021)是先學習後門,其次透過抑制其影響來消除隱藏的後門。
5.基於中毒抑制的防禦(Du et al,2020;Borgnia et al,2021)在訓練過程中降低中毒樣本的有效性,以防止隱藏後門的產生
2.3 半監督學習與自監督學習
1.半監督學習:在許多現實世界的應用程式中,標記資料的獲取通常依賴手動標記,這是非常昂貴的。相比之下,獲得未標記的樣本要容易得多。為了同時利用未標記樣本和標記樣本的力量,提出了大量的半監督學習方法(Gao et al.,2017;Berthelot et al,2019;Van Engelen & Hoos,2020)。最近,半監督學習也被用來提高模型的安全性(Stanforth et al,2019;Carmon et al,2019),他們在對抗訓練中使用了未標記的樣本。最近,(Yan et al,2021)討論如何後門半監督學習。然而,此方法除了修改訓練樣本外,還需要控制其他訓練成分(如訓練損失)。
2.自監督學習:自監督學習範式是無監督學習的子集,模型使用資料本身產生的訊號進行訓練(Chen et al,2020a;Grill et al ,2020;Liu et al,2021)。它被用來增加對抗魯棒性(Hendrycks et al,2019;Wu et al,2021;Shi et al,2021)。最近,一些文章(Saha et al,2021;Carlini & Terzis, 2021;Jia et al,2021)探討如何投入後門於自監督學習。然而,這些攻擊除了修改訓練樣本外,它們還需要控制其他訓練成分(例如,訓練損失)。
3 後門特徵
我們對CIFAR-10資料集(Krizhevsky, 2009)進行了BadNets和乾淨標籤攻擊。對有毒資料集進行監督學習以及對未標記資料集進行自監督學習SimCLR(Chen et al., 2020a)。
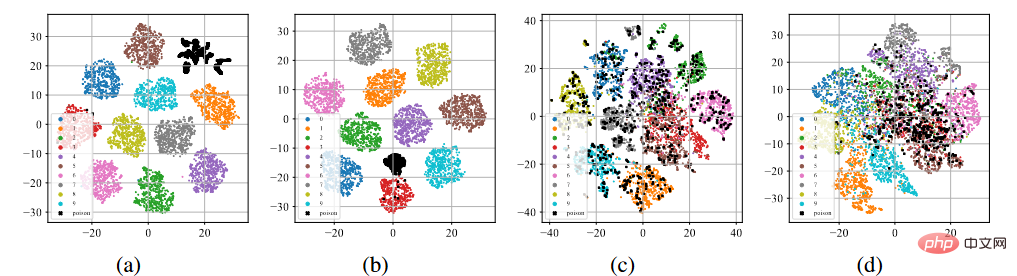
#後門特徵的t-sne展示
如上圖(a )-(b)所示,在經過標準監督訓練過程後,無論在投毒標籤攻擊還是乾淨標籤攻擊下,中毒樣本(用黑點表示)都傾向於聚在一起形成單獨的聚類。這種現象暗示了現有的基於投毒的後門攻擊成功原因。過度的學習能力允許模型學習後門觸發器的特徵。與端到端監督訓練範式結合,模型可以縮小特徵空間中中毒樣本之間的距離,並將學習到的觸發器相關特徵與目標標籤連接起來。相反,如上圖(c)-(d)所示,在未標記的中毒資料集上,經過自監督訓練過程後,中毒樣本與帶有原有標籤的樣本非常接近。這表明我們可以透過自監督學習來防止後門的產生。
4 基於分割的後門防禦
#基於後門特徵的分析,我們提出分割訓練階段的後門防禦。如下圖所示,它包括三個主要階段,(1)透過自監督學習學習一個純化的特徵提取器,(2)透過標籤雜訊學習過濾高可信樣本,(3)半監督微調。
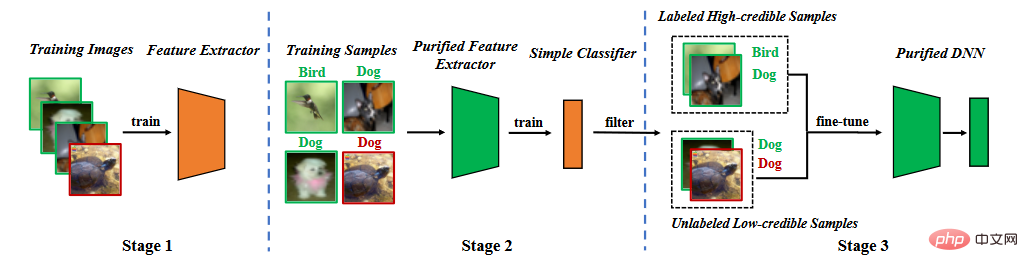 方法流程圖
方法流程圖
#4.1 學習特徵擷取器
我們用訓練資料集去學習模型。模型的參數包含兩個部分,一部分是骨幹模型(backbone model)的參數另一部分是全連接層(fully connected layer)的參數。我們利用自監督學習來優化骨幹模型的參數。
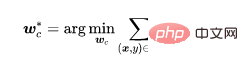
其中是自監督損失(例如,NT-Xent在SimCLR (Chen et al,2020)). 透過前面的分析,我們可以知道特徵提取器很難學習到後門特徵。
4.2 標籤雜訊學習過濾樣本
一旦特徵提取器被訓練好後,我們固定特徵提取器的參數並用訓練資料集進一步學習全連接層參數,
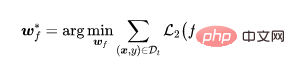
其中是監督學習損失(例如,交叉熵損失(cross entropy))。
雖然這樣的分割流程會讓模型很難學到後門,但是它有兩個問題。首先,與透過監督學習訓練的方法相比,由於學習到的特徵提取器在第二階段被凍結,預測乾淨樣本的準確率會有一定的下降。其次,當中毒標籤攻擊出現時,中毒樣本將作為“離群值”,進一步阻礙第二階段的學習。這兩個問題顯示我們需要去除中毒樣本,並對整個模型進行再訓練或微調。
我們要判斷樣本是否有後門。我們認為模型對於後門樣本難以學習,因此採用置信度作為區分指標,高置信度的樣本為乾淨樣本,而低置信度的樣本為中毒樣本。透過實驗發現,利用對稱交叉熵損失訓練的模型對於兩個樣本的損失差距較大,因此區分度較高,如下圖所示。
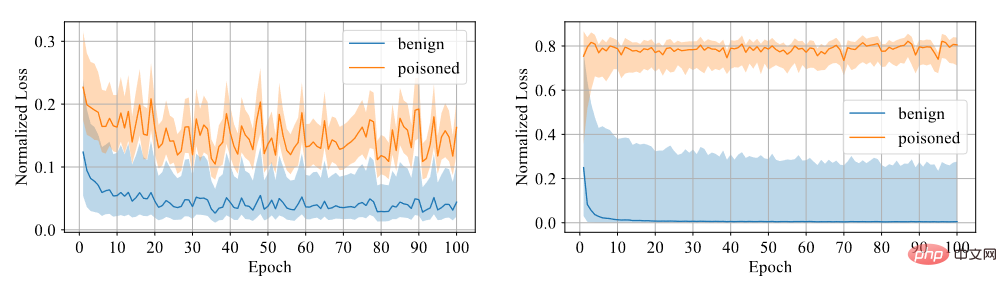
#對稱交叉熵損失和交叉熵損失對比
因此,我們固定特徵提取器利用對稱交叉熵損失訓練全連接層,並且透過置信度的大小篩選資料集為高置信度資料和低置信度資料。
4.3 半監督微調
#首先,我們刪除低置信度資料的標籤。我們利用半監督式學習微調整個模式 。

其中是半監督損失(例如,在MixMatch(Berthelot et al,2019)中的損失函數)。
半監督微調既可以避免模型學習到後門觸發器,又可以讓模型在乾淨資料集上表現良好。
5 實驗
5.1 資料集與基準
文章在兩個經典基準數據集上評估所有防禦,包括CIFAR-10 (Krizhevsky, 2009)和ImageNet (Deng等人,2009)(一個子集)。文章採用ResNet18模型(He et al.,2016)
文章研究了防禦四種典型攻擊的所有防禦方法,即badnets(Gu et al,2019)、混合策略的後門攻擊(blended)(Chen et al,2017)、WaNet (Nguyen & Tran, 2021)和帶有對敵擾動的乾淨標籤攻擊(label-consistent)(Turner et al,2019)。

#後門攻擊範例圖片
5.2 實驗結果
實驗的判斷標準為BA是乾淨樣本的判斷準確率和ASR是中毒樣本的判斷準確率。
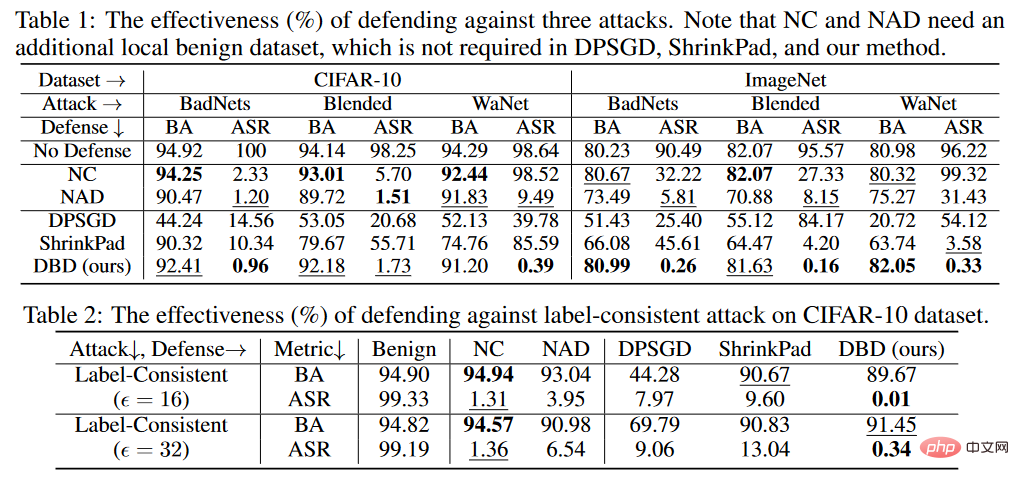
後門防禦對比結果
#######################################################如上表所示,DBD在防禦所有攻擊方面明顯優於具有相同要求的防禦(即DPSGD和ShrinkPad)。在所有情況下,DBD比DPSGD的BA超過20%,而ASR低5%。 DBD模型的ASR在所有情況下都小於2%(大多數情況下低於0.5%),驗證了DBD可以成功地防止隱藏後門的創建。 DBD與另外兩種方法(即NC和NAD)進行比較,這兩種方法都要求防禦者擁有乾淨的本地資料集。
如上表所示,NC和NAD優於DPSGD和ShrinkPad,因為它們採用了來自本地的乾淨資料集的額外資訊。特別是,儘管NAD和NC使用了額外的信息,但DBD比它們更好。特別是在ImageNet資料集上,NC對ASR的降低效果有限。相較之下,DBD達到最小的ASR,而DBD的BA在幾乎所有情況下都是最高或第二高。此外,與未經任何防禦訓練的模型相比,防禦中毒標籤攻擊時的BA下降不到2%。在相對較大的資料集上,DBD甚至更好,因為所有的基準方法都變得不那麼有效。這些結果驗證了DBD的有效性。
5.3 消融實驗
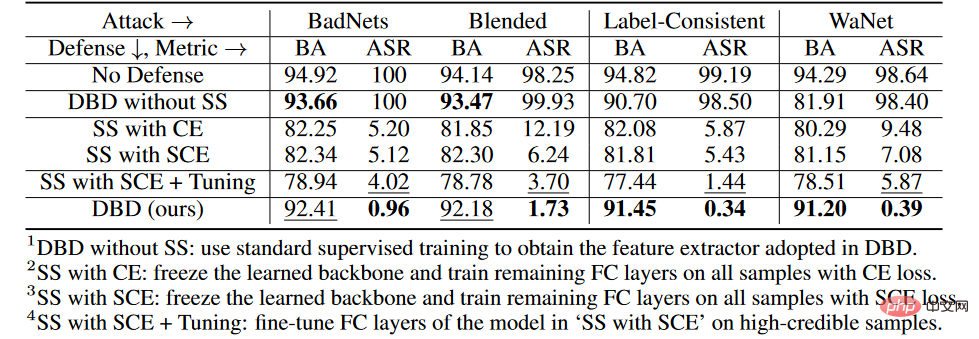
各階段消融實驗
在CIFAR-10資料集上,我們比較了提出的DBD及其四個變體,包括
1.DBD不帶SS,將由自監督學習產生的骨幹替換為以監督方式訓練的主幹,並保持其他部分不變
2.SS帶CE,凍結了透過自監督學習學習到的骨幹,並在所有訓練樣本上訓練剩下的全連接層的交叉熵損失
3.SS帶SCE, 與第二種變體類似,但使用了對稱交叉熵損失訓練。
4.SS帶SCE Tuning,進一步微調第三個變體過濾的高置信度樣本上的全連接層。
如上表所示,解耦原始的端對端監督訓練過程在防止隱藏後閘的建立方面是有效的。此外,比較第二個和第三個DBD變體來驗證SCE損失對防禦毒藥標籤後門攻擊的有效性。另外,第4個DBD變異的ASR和BA相對於第3個DBD變異要低一些。這現像是由於低可信度樣本的去除。這表明,在採用低可信度樣本的有用資訊的同時減少其副作用對防禦很重要。
5.4 對於潛在的自適應性攻擊的抵抗
如果攻擊者知道DBD的存在,他們可能會設計自適應性攻擊。如果攻擊者能夠知道防禦者使用的模型結構,他們可以透過優化觸發模式,在自監督學習後,使中毒樣本仍然在一個新的集群中,從而設計自適應性攻擊,如下所示:
攻擊設定
對於一個-分類問題,讓代表那些需要被投毒的乾淨樣本,代表原標籤為的樣本,以及是一個被訓練的骨幹。給定攻擊者預定的中毒圖像生成器,自適應性攻擊旨在優化觸發模式,透過最小化有毒圖像之間的距離,同時最大化有毒圖像的中心與具有不同標籤的良性圖像集群的中心之間的距離,即。
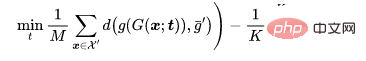
其中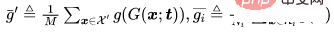 ,是一個距離判定。
,是一個距離判定。
實驗結果
自適應性攻擊在沒有防禦的情況下的BA為94.96%,和ASR為99.70%。然而,DBD的防禦結果為BA93.21%以及ASR1.02%。換句話說,DBD是抵抗這種適應性攻擊的。
6 總結
基於投毒的後門攻擊的機制是在訓練過程中在觸發模式和目標標籤之間建立潛在的連結。本文揭示了這種連接主要是由於端到端監督訓練範式學習。基於這個認知,本文提出了一種基於解耦的後門防禦方法。大量的實驗驗證了DBD防禦在減少後門威脅的同時保持了預測良性樣本的高精度。
以上是分割後門訓練的後門防禦方法:DBD的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 模型合併就進化,直接拿下SOTA! Transformer作者創業新成果火了
Mar 26, 2024 am 11:30 AM
模型合併就進化,直接拿下SOTA! Transformer作者創業新成果火了
Mar 26, 2024 am 11:30 AM
把Huggingface上的現成模型拿來「攢一攢」-直接就能組合出新的強大模型? !日本大模型公司sakana.ai腦洞大開(正是「Transformer八子」之一所創辦的公司),想出了這麼一個進化合併模式的妙招。該方法不僅能自動產生新的基礎模型,而且性能絕不賴:他們利用一個包含70億個參數的日語數學大型模型,在相關基準測試中取得了最先進的結果,超越了700億參數的Llama- 2等先前模型。最重要的是,得出這樣的模型不需要任何梯度訓練,因此所需的計算資源大大減少。英偉達科學家JimFan看完大讚
 美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
最近,軍事圈被這個消息刷屏了:美軍的戰鬥機,已經能由AI完成全自動空戰了。是的,就在最近,美軍的AI戰鬥機首次公開,揭開了神秘面紗。這架戰鬥機的全名是可變穩定性飛行模擬器測試飛機(VISTA),由美空軍部長親自搭乘,模擬了一對一的空戰。 5月2日,美國空軍部長FrankKendall在Edwards空軍基地駕駛X-62AVISTA升空注意,在一小時的飛行中,所有飛行動作都由AI自主完成! Kendall表示——在過去的幾十年中,我們一直在思考自主空對空作戰的無限潛力,但它始終顯得遙不可及。然而如今,
 只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
我們熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21實驗室推出的Jamba等開源大語言模型已經成為OpenAI的競爭對手。在大多數情況下,使用者需要根據自己的資料對這些開源模型進行微調,才能充分釋放模型的潛力。在單一GPU上使用Q-Learning對比小的大語言模型(如Mistral)進行微調不是難事,但對像Llama370b或Mixtral這樣的大模型的高效微調直到現在仍然是一個挑戰。因此,HuggingFace技術主管PhilippSch
