

NUS華人團隊發布最新模型:單視圖重建3D,快速準確!

2D影像的3D重建一直是CV領域的重頭戲。
層出不同的模型被發展出來試圖攻克這個難題。
今天,新加坡國立大學的學者共同發表了一篇論文,發展了一個全新的框架Anything-3D來解決這個老大難問題。

#論文網址:https://arxiv.org/pdf/2304.10261.pdf
#借助Meta「分割一切」模型,Anything-3D直接讓分割後的任意物體活起來了。

另外,再用上Zero-1-to-3模型,就可以得到不同角度的柯基。
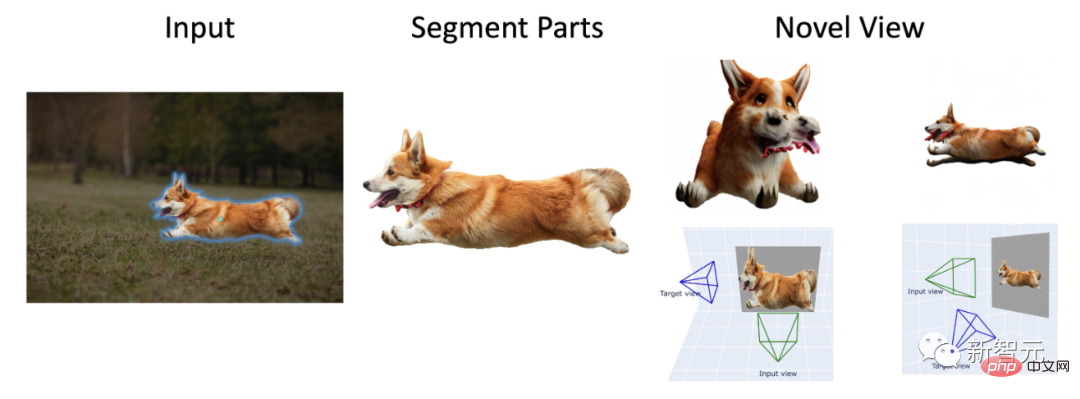
甚至,還可以進行人物3D重建。

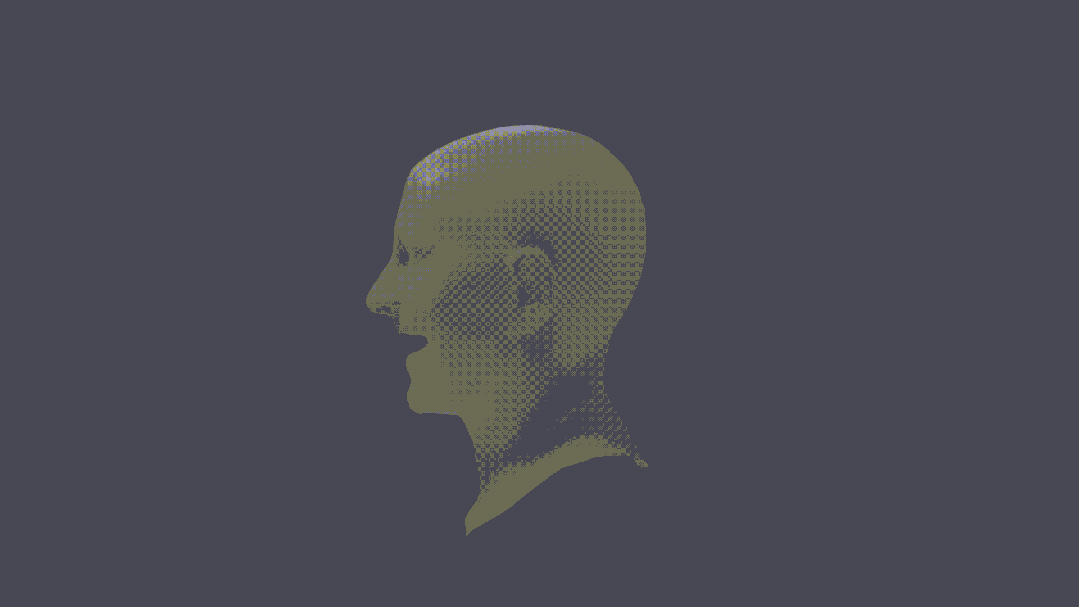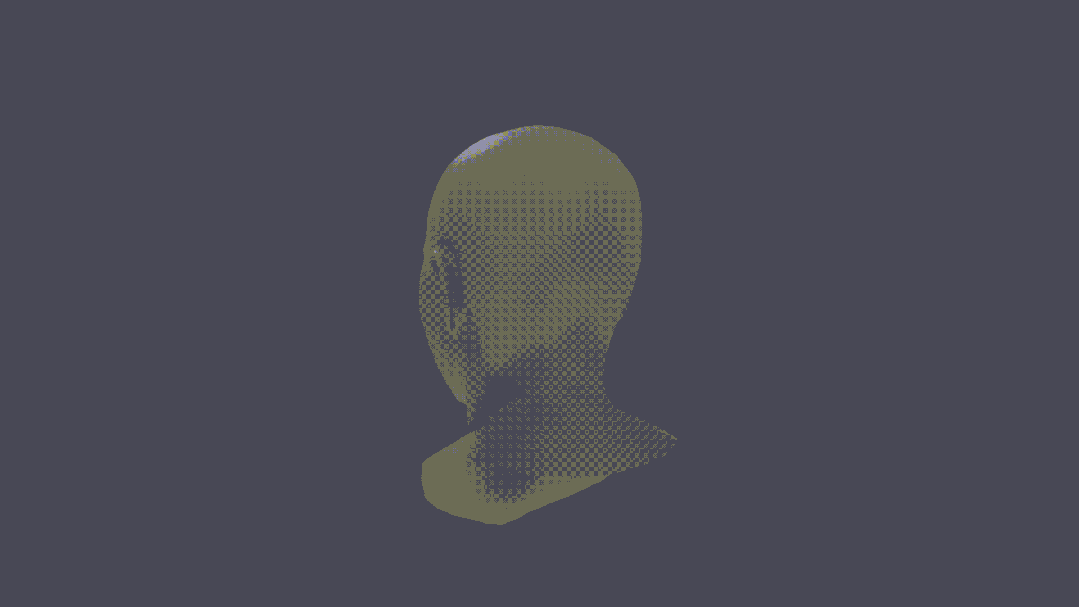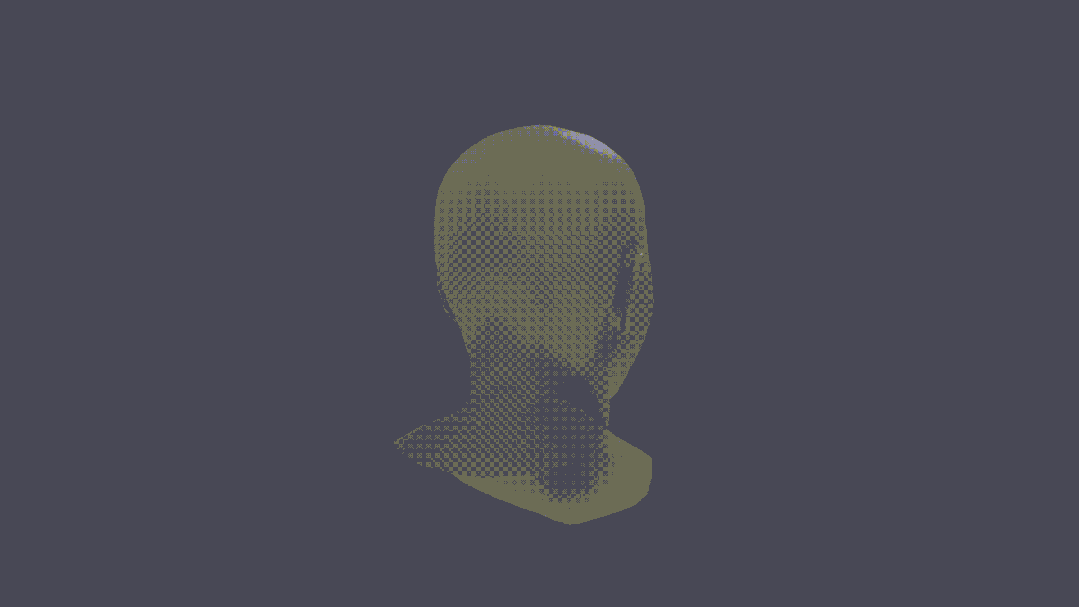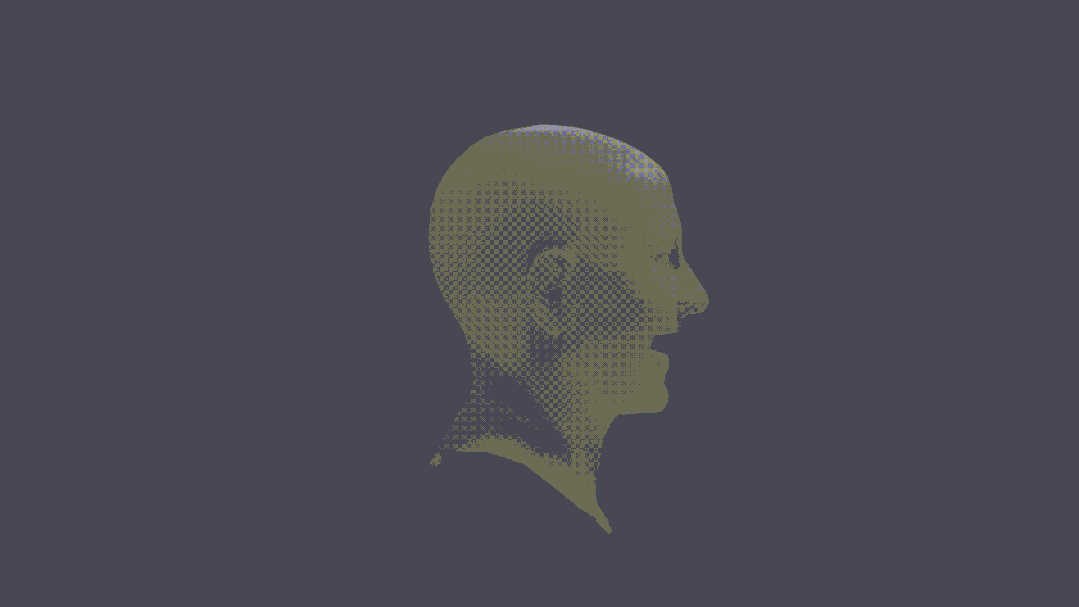
可以說,這把真突破了。
Anything-3D!
在現實世界中,各種物件和各類環境既多元又複雜。所以,在不受限制的情況下,從單一RGB影像中進行三維重建面臨許多困難。
在此,新加坡國立大學研究人員結合了一系列視覺語言模型和SAM(Segment-Anything)物件分割模型,產生了一個功能多、可靠的系統— —Anything-3D。
目的就是在單一視角的條件下,完成3D重建的任務。
他們採用BLIP模型產生紋理描述,用SAM模型擷取影像中的物體,然後利用文字→影像的擴散模型Stable Diffusion將物體放置到Nerf(神經輻射場)中。
在後續的實驗中,Anything-3D展現了其強大的三維重建的能力。不僅準確,適用面也非常廣泛。
Anything-3D在解決現有方法的限制這方面,效果明顯。研究者透過對各類資料集的測驗和評估,展現了這種新框架的優點。

上圖中,我們可以看到,「柯基吐舌頭千里奔襲圖」、「銀翅女神像委身豪車圖」 ,以及「田野棕牛頭戴藍繩圖」。
這是一個初步展示,Anything-3D框架能夠熟練地將在任意的環境中拍攝的單視角圖像中恢復成的3D的形態,並生成紋理。
儘管相機視角和物件屬性有很大的變化,但這種新框架總是能提供準確度較高的結果。
要知道,從2D影像重建3D物件是電腦視覺領域主題的核心,對機器人、自動駕駛、擴增實境、虛擬現實,以及三維列印等領域都有巨大影響。
雖說這幾年來取得了一些不錯的進展,但在非結構化環境中進行單一影像物件重建的任務仍然是一個具有很大吸引力且亟待解決的問題。
目前,研究人員的任務就是從一張單一的二維影像中產生一個或多個物體的三維表示,表示方法包括點雲、網格或體積表示。
然而,這個問題根本上並不成立。
由於二維投影所產生的內在模糊性,無法明確地確定一個物體的三維結構。
再加上形狀、大小、紋理和外觀的巨大差異,重建自然環境下的物體非常複雜。此外,現實世界影像中的物體經常會被遮擋,這會阻礙被遮蔽部分的精確重建。
同時,光照和陰影等變數也會大幅影響物體的外觀,而角度和距離的不同也會導致二維投影的明顯變化。
困難說夠了,Anything-3D可以出場了。
論文中,研究人員詳細介紹了這個開創性的系統框架,將視覺語言模型和物件分割模型融合在一起,輕鬆鬆就能把2D物件搞成3D的。
這樣,一個功能強大、自適應能力強的系統就成了。單視圖重建? Easy.
研究人員表示,將這兩種模型結合,就可以擷取並確定給定影像的三維紋理和幾何形狀。
Anything-3D利用BLIP模型(Bootstrapping語言-圖像模型)預先訓練圖像的文字描述,然後再用SAM模型辨識物件的分佈區域。
接下來,利用分割出來的物件和文字描述來執行3D重建任務。
換句話說,論文利用預先訓練好的2D文字→影像擴散模型來進行影像的3D合成。此外,研究人員以分數蒸餾訓練一個專門用於影像的Nerf.
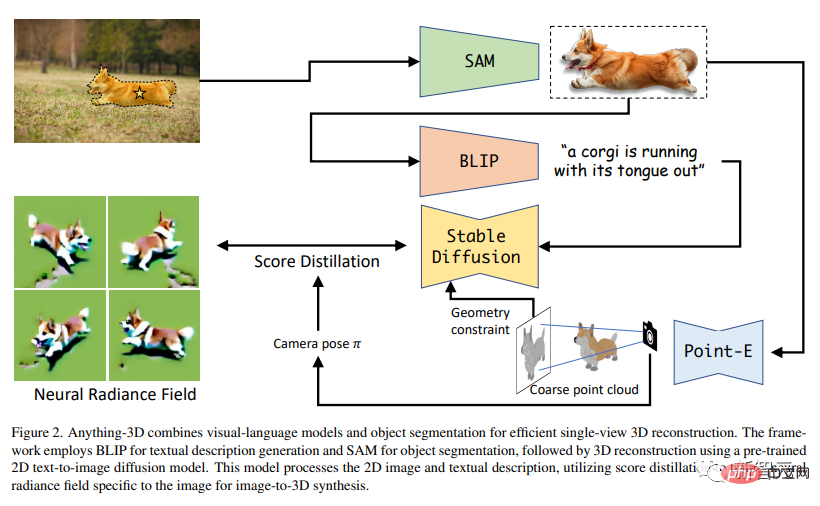
上圖就是產生3D影像的整個過程。左上角是2D原圖,先經過SAM,分割出柯基,再經過BLIP,生成文本描述,再用分數蒸餾搞個Nerf出來。
透過對不同資料集的嚴格實驗,研究人員展示了這種方法的有效性和適應性,同時,在準確性、穩健性和概括能力方面都超過了現有的方法。
研究人員也對自然環境中3D物件重建中已有的挑戰進行了全面深入地分析,探討了新框架如何解決此類問題。
最終,透過將基礎模型中的零距離視覺和語言理解能力融合,新框架更能從真實世界的各類影像中重建物體,產生精確、複雜、適用面廣的3D表示。
可以說,Anything-3D是3D物件重建領域的一個重大突破。
以下是更多的例子:

酷黑色內裝小白保時捷,亮麗橙色挖機吊車,綠帽小黃橡皮鴨
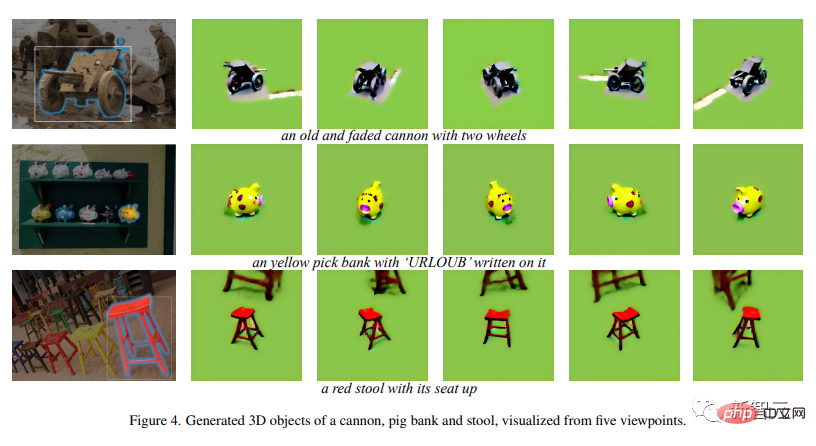
時代眼淚褪色大砲、小豬可愛迷你存錢筒、硃砂紅四腳高腳凳
這個新框架可以互動式地辨識單視角影像中的區域,並以最佳化的文字嵌入來表示2D物體。最終,使用一個3D感知的分數蒸餾模型有效地產生高品質的3D物體。
總之,Anything-3D展示了從單視角影像重建自然3D物體的潛力。
研究者稱,新框架3D重建的品質還可以更完美,研究人員正在不斷努力提高生成的品質。
此外,研究人員表示,目前沒有提供3D資料集的定量評估,如新的視圖合成和誤差重建,但在未來的工作迭代中會納入這些內容。
同時,研究人員的最終目標是擴大這個框架,以適應更多的實際情況,包括稀疏視圖下的物件復原。
作者介紹
Wang目前是新加坡國立大學(NUS)ECE系的終身助理教授。
在加入新加坡國立大學之前,他曾是Stevens理工學院CS系的助理教授。在加入Stevens之前,我曾在伊利諾大學厄巴納-香檳分校Beckman研究所的Thomas Huang教授的圖像形成小組擔任博士後。
Wang在洛桑聯邦理工學院(EPFL)電腦視覺實驗室獲得博士學位,由Pascal Fua教授指導,並在2010年獲得香港理工大學計算機系的一等榮譽學士學位。

以上是NUS華人團隊發布最新模型:單視圖重建3D,快速準確!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
四款值得推薦的AI輔助程式工具
Apr 22, 2024 pm 05:34 PM
這個AI輔助程式工具在這個AI快速發展的階段,挖掘出了一大批好用的AI輔助程式工具。 AI輔助程式設計工具能夠提升開發效率、提升程式碼品質、降低bug率,是現代軟體開發過程中的重要助手。今天大姚給大家分享4款AI輔助程式工具(而且都支援C#語言),希望對大家有幫助。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI編碼助手,可幫助你更快、更省力地編寫程式碼,從而將更多精力集中在問題解決和協作上。 Git
 CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
寫在前面&筆者的個人理解目前,在整個自動駕駛系統當中,感知模組扮演了其中至關重要的角色,行駛在道路上的自動駕駛車輛只有通過感知模組獲得到準確的感知結果後,才能讓自動駕駛系統中的下游規控模組做出及時、正確的判斷和行為決策。目前,具備自動駕駛功能的汽車中通常會配備包括環視相機感測器、光達感測器以及毫米波雷達感測器在內的多種數據資訊感測器來收集不同模態的信息,用於實現準確的感知任務。基於純視覺的BEV感知演算法因其較低的硬體成本和易於部署的特點,以及其輸出結果能便捷地應用於各種下游任務,因此受到工業
 牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
寫在前面項目連結:https://nianticlabs.github.io/mickey/給定兩張圖片,可以透過建立圖片之間的對應關係來估計它們之間的相機姿態。通常,這些對應關係是二維到二維的,而我們估計的姿態在尺度上是不確定的。一些應用,例如隨時隨地實現即時增強現實,需要尺度度量的姿態估計,因此它們依賴外部的深度估計器來恢復尺度。本文提出了MicKey,這是一個關鍵點匹配流程,能夠夠預測三維相機空間中的度量對應關係。透過學習跨影像的三維座標匹配,我們能夠在沒有深度測試的情況下推斷度量相對
 AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
AI程式設計師哪家強?探索Devin、通靈靈碼和SWE-agent的潛力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距離世界首個AI程式設計師Devin誕生不足一個月,普林斯頓大學的NLP團隊開發了一個開源AI程式設計師SWE-agent。它利用GPT-4模型在GitHub儲存庫中自動解決問題。 SWE-agent在SWE-bench測試集上的表現與Devin相似,平均耗時93秒,解決了12.29%的問題。 SWE-agent透過與專用終端交互,可以開啟、搜尋文件內容,使用自動語法檢查、編輯特定行,以及編寫和執行測試。 (註:以上內容為原始內容微調,但保留了原文中的關鍵訊息,未超過指定字數限制。)SWE-A
 學習如何利用Go語言開發行動應用程式
Mar 28, 2024 pm 10:00 PM
學習如何利用Go語言開發行動應用程式
Mar 28, 2024 pm 10:00 PM
Go語言開發行動應用程式教學隨著行動應用程式市場的不斷蓬勃發展,越來越多的開發者開始探索如何利用Go語言開發行動應用程式。作為一種簡潔高效的程式語言,Go語言在行動應用開發中也展現了強大的潛力。本文將詳細介紹如何利用Go語言開發行動應用程序,並附上具體的程式碼範例,幫助讀者快速入門並開始開發自己的行動應用程式。一、準備工作在開始之前,我們需要準備好開發環境和工具。首
 LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
寫在前面&筆者的個人理解這篇論文致力於解決當前多模態大語言模型(MLLMs)在自動駕駛應用中存在的關鍵挑戰,即將MLLMs從2D理解擴展到3D空間的問題。由於自動駕駛車輛(AVs)需要針對3D環境做出準確的決策,這項擴展顯得格外重要。 3D空間理解對於AV來說至關重要,因為它直接影響車輛做出明智決策、預測未來狀態以及與環境安全互動的能力。目前的多模態大語言模型(如LLaVA-1.5)通常只能處理較低解析度的影像輸入(例如),這是由於視覺編碼器的分辨率限制,LLM序列長度的限制。然而,自動駕駛應用需
 3D視覺繞不開的點雲配準!一文搞懂所有主流方案與挑戰
Apr 02, 2024 am 11:31 AM
3D視覺繞不開的點雲配準!一文搞懂所有主流方案與挑戰
Apr 02, 2024 am 11:31 AM
作為點集合的點雲有望透過3D重建、工業檢測和機器人操作中,在獲取和生成物體的三維(3D)表面資訊方面帶來一場改變。最具挑戰性但必不可少的過程是點雲配準,即獲得一個空間變換,該變換將在兩個不同座標中獲得的兩個點雲對齊並匹配。這篇綜述介紹了點雲配準的概述和基本原理,對各種方法進行了系統的分類和比較,並解決了點雲配準中存在的技術問題,試圖為該領域以外的學術研究人員和工程師提供指導,並促進點雲配準統一願景的討論。點雲獲取的一般方式分為主動和被動方式,由感測器主動獲取的點雲為主動方式,後期透過重建的方式
 五大熱門Go語言庫總表:開發必備利器
Feb 22, 2024 pm 02:33 PM
五大熱門Go語言庫總表:開發必備利器
Feb 22, 2024 pm 02:33 PM
五大熱門Go語言庫總結:開發必備利器,需要具體程式碼範例Go語言自從誕生以來,受到了廣泛的關注和應用。作為一門新興的高效、簡潔的程式語言,Go的快速發展離不開豐富的開源程式庫的支援。本文將介紹五大熱門的Go語言庫,這些庫在Go開發中扮演了至關重要的角色,為開發者提供了強大的功能和便利的開發體驗。同時,為了更好地理解這些庫的用途和功能,我們會結合具體的程式碼範例進行講
