

研究顯示:基於相似性加權交錯學習可有效應對深度學習中的「失憶症」問題

與人類不同,人工神經網路在學習新事物時會迅速遺忘先前學到的信息,必須透過新舊資訊的交錯來重新訓練;但是,交錯全部舊資訊非常耗時,並且可能沒有必要。只交錯與新資訊有實質相似性的舊資訊可能就足夠了。
近日,美國科學院院報(PNAS)刊登了一篇論文,“Learning in deep neural networks and brains with similarity-weighted interleaved learning”,由加拿大皇家學會會士、由知名神經科學家Bruce McNaughton 的團隊發表。他們的工作發現,透過將舊資訊與新資訊進行相似性加權交錯訓練,深度網路可以快速學習新事物,不僅降低了遺忘率,而且使用的資料量大幅減少。
論文作者也做出一個假設:透過追蹤最近活躍的神經元和神經動力學吸引子(attractor dynamics)的持續興奮性軌跡,可以在大腦中實現相似性加權交錯。這些發現可能會促進神經科學和機器學習的進一步發展。
研究背景
了解大腦如何終身學習仍然是一項長期挑戰。
在人工神經網路(ANN)中,過快地整合新資訊會產生災難性幹擾,即先前獲得的知識突然失去。互補學習系統理論 (Complementary Learning Systems Theory,CLST) 表明,透過將新記憶與現有知識交錯,新記憶可以逐漸融入新皮質。
CLST指出,大腦依賴互補的學習系統:海馬體(HC) 用於快速獲取新記憶,新皮質(NC) 用於將新數據逐漸整合到與上下文無關的結構化知識中。在“離線期間”,例如睡眠和安靜的清醒休息期間,HC觸發回放最近在NC中的經歷,而NC自發地檢索和交錯現有類別的表徵。交錯回放允許以梯度下降的方式逐步調整NC突觸權重,以創建與上下文無關的類別表徵,從而優雅地整合新記憶並克服災難性幹擾。許多研究已經成功地使用交錯回放實現了神經網路的終身學習。
然而,在實務上應用CLST時,有兩個重要問題亟待解決。首先,當大腦無法存取所有舊數據時,如何進行全面的資訊交錯呢?一個可能的解決方案是“偽排練”,其中隨機輸入可以引發內部表徵的生成式回放,而無需明確訪問先前學習的範例。類吸引子動力學可能使大腦完成“偽排練”,但“偽排練”的內容尚未明確。因此,第二個問題是,每進行新的學習活動之後,大腦是否有足夠的時間交織所有先前學習的資訊。
相似性加權交錯學習(Similarity-Weighted Interleaved Learning,SWIL)演算法被認為是第二個問題的解決方案,這表明僅交錯與新資訊具有實質表徵相似性的舊資訊可能就足夠了。實證行為研究表明,高度一致的新資訊可以快速整合到NC結構化知識中,幾乎沒有乾擾。這表明整合新資訊的速度取決於其與先驗知識的一致性。受此行為結果的啟發,並透過重新檢查先前獲得的類別之間的災難性幹擾分佈,McClelland等人證明SWIL可以在具有兩個上義詞類別(例如,「水果」是「蘋果」和「香蕉」的上義詞)的簡單數據集中,每個epoch使用少於2.5倍的數據量學習新信息,實現了與在全部數據上訓練網絡相同的性能。然而,研究人員在使用更複雜的數據集時並沒有發現類似的效果,這引發了對該演算法可擴展性的擔憂。
實驗表明,深度非線性人工神經網路可以透過僅交錯與新資訊共享大量表徵相似性的舊資訊子集來學習新資訊。透過使用SWIL演算法,ANN能夠以相似的精度水平和最小的干擾快速學習新訊息,同時使用的每個時期呈現的舊信息量少之又少,這意味著數據利用率高且可以快速學習。
同時,SWIL也可應用於序列學習架構。此外,學習一個新類別可以大大提高資料利用率 。如果舊資訊與先前學習過的類別有著非常少的相似性,那麼呈現的舊資訊數量就會少得多,這很可能是人類學習的實際情況。
最後,作者提出了一個關於SWIL如何在大腦中實現的理論模型,其興奮性偏差與新資訊的重疊成正比。
應用於影像分類資料集的DNN動力學模型
#McClelland等人的實驗表明,在具有一個隱藏層的深度線性在網路中,SWIL可以學習一個新類別,類似於完全交錯學習(Fully Interleaved Learning,FIL),即將整個舊類別與新類別交錯,但使用的資料量減少了40%。
然而,網路是在一個非常簡單的資料集上訓練的,只有兩個上義詞類別,這就對演算法的可擴展性提出了疑問。
#首先針對更複雜的資料集(如Fashion-MNIST),探索不同類別的學習在具有一個隱藏層的深度線性神經網路中如何演變。移出了「boot」(「靴子」)和「bag」(「紙袋」)類別後,模型在剩餘的8個類別上的測試準確率達到了87%。然後作者團隊重新訓練模型,在兩種不同的條件下學習(新的)「boot」類,每個條件重複10次:
- 集中學習(Focused Learning ,FoL),即僅呈現新的「boot」類別;
- 完全交錯學習(FIL),即所有類別(新類別先前學過的類別)以相等的機率呈現。在這兩種情況下,每個epoch總共呈現180張影像,每個epoch中的影像相同。
該網路在總共9000張從未見過的圖像上進行了測試,其中測試資料集由每個類別1000張圖像組成,不包括「bag」類別。當網路的效能達到漸近線時,訓練停止。
不出所料,FoL對舊類別造成了乾擾,而FIL克服了這一點(圖1第2列)。如上所述,FoL對舊資料的干擾因類別而異,這是SWIL最初靈感的一部分,並表明新「boot」類別和舊類別之間存在分級相似關係。例如,「sneaker」(「運動鞋」)和「sandals」(「涼鞋」)的回想率比「trouser」(「褲子」)下降得更快(圖1第2列),可能是因為整合新的「boot」類會選擇性地改變代表「sneaker」和「sandals」類的突觸權重,從而造成更多的干擾。
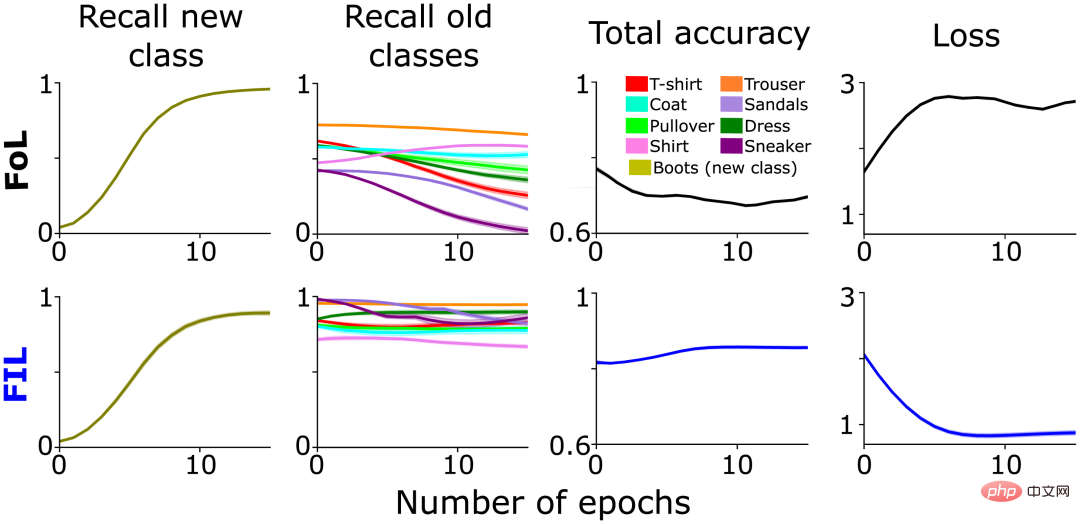
圖1:預訓練網路在兩種情況下學習新「boot」類別的效能比較分析:FoL (上)和FIL(下)。從左到右依序為預測新「boot」類別的回想率(橄欖色)、現有類別的回想率(以不同顏色繪製)、總準確度(高分數意味著低誤差)和交叉熵損失(總誤差的量測)曲線,是保留的測試資料集上與epoch數有關的函數。
計算不同類別之間的相似度
FoL在學習新類別的時候,在相似的舊類別上的分類表現會大幅下降。
先前已經探討了多類別屬性相似度和學習之間的關係,並且顯示深度線性網路可以快速取得已知的一致屬性。相較之下,在現有類別層次結構中加入新分支的不一致屬性,需要緩慢、漸進、交錯的學習。
在目前的工作中,作者團隊使用已提出的方法在特徵層級計算相似度。簡言之,計算目標隱藏層(通常是倒數第二層)現有類別和新類別的平均每類活化向量之間的餘弦相似度。圖2A顯示了基於Fashion MNIST資料集的新「boot」類別和舊類別,作者團隊根據預訓練網路的倒數第二層激活函數計算的相似度矩陣。
類別之間的相似性與我們對物體的視覺感知一致。例如,在層次聚類圖(圖2B)中,我們可以觀察到「boot」類別與「sneaker」和「sandal」類別之間、以及「shirt」(「襯衫」)和「t-shirt」(“ T卹”)類之間具有較高的相似性。相似度矩陣(圖2A)與混淆矩陣(圖2C)完全對應。相似度越高,越容易混淆,例如,「襯衫」類與「T卹」、「套頭衫」和「外套」類圖像容易混淆,這表明相似性度量預測了神經網路的學習動態。
在上一節的FoL結果圖(圖1)中,舊類別的召回率曲線中存在相近的類別相似度曲線。與不同的舊類別(“trouser”等)相比,FoL學習新“boot”類別的時候會快速遺忘相似的舊類別(“sneaker” 和 “sandal”)。
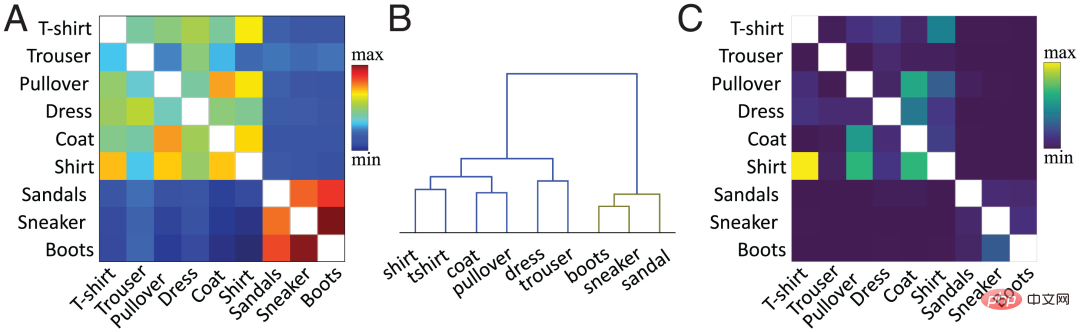
圖2:( A ) 作者團隊根據預訓練網路的倒數第二層啟動函數,計算出來的現有類別和新“boot”類的相似度矩陣,其中對角線值(同一類別的相似性繪製為白色)被刪除。 ( B ) 對A中的相似矩陣進行層次聚類。 ( C ) FIL演算法在訓練學習「boot」類別後所產生的混淆矩陣。為了縮放清晰,刪除了對角線值。
深度線性神經網路實現快速和高效學習新事物
#接下來在前兩個條件基礎上增加了3種新條件,研究了新的分類學習動態,其中每個條件重複10次:
- FoL(共n=6000張圖片/epoch);
- FIL(共n=54000張圖片/epoch,6000張圖片/類別);
- 部分交錯學習(Partial Interleaved Learning,PIL)使用了很小的圖像子集(共計n=350張圖像/epoch,大約39張圖像/類別),每個類別(新類別現有類別)的圖像以相等的機率呈現;
- SWIL,每個epoch使用與PIL 相同的圖像總數進行重新訓練,但根據與(新)「boot」類別的相似性對現有類別圖像進行加權;
- 等權交錯學習(Equally Weighted Interleaved Learning,EqWIL),使用與SWIL相同數量的「boot」類別影像重新訓練,但現有類別影像的權重相同(圖3A)。
作者團隊使用了上述相同的測試資料集(共有n=9000張圖片)。當在每種條件下神經網路的效能都達到漸近線時,停止訓練。儘管每個epoch使用的訓練資料較少,預測新「boot」類別的準確率需要更長的時間達到漸近線,與FIL(H=7.27,P
對於SWIL,相似度計算用於確定要交錯的現有舊類別影像的比例。在此基礎上,作者團隊從每個舊類別中隨機抽取具有加權機率的輸入影像。與其他類別相比,「sneaker」和「sandal」類別最相似,導致被交錯的比例更高(圖3A)。
根據樹狀圖(圖2B),作者團隊將「sneaker」和「sandal」類別稱為相似的舊類,其餘則稱為不同的舊類。與PIL(H=5.44,P0.05)的新類別召回率(圖3B第1列和表1「New class」欄)、總準確率和損失與FIL相當。 EqWIL(H=10.99,P
作者團隊使用以下兩種方法比較SWIL和FIL:
- 內存比,即FIL和SWIL中存儲的圖像數量之比,表示存儲的資料量減少;
- 加速比,即在FIL和SWIL中呈現的內容總數的比率,以達到新類別回憶的飽和精度,表明學習新類別所需的時間減少。
SWIL可以在資料需求減少的情況下學習新內容,記憶體比=154.3x (54000/350),並且速度更快,加速比=77.1x ( 54000/(350×2))。即使和新內容相關的圖像數量較少,該模型也可以透過使用SWIL,利用模型先驗知識的層次結構來實現相同的性能。 SWIL在PIL和EqWIL之間提供了一個中間緩衝區,允許整合一個新類別,並將現有類別的干擾降到最低。
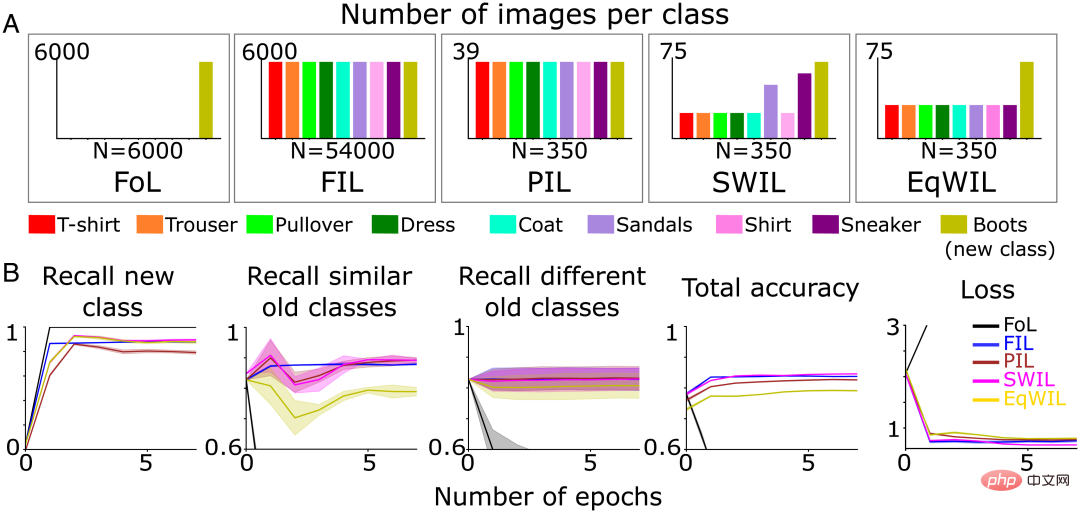
#圖3 ( A ) 作者團隊在五種不同的學習條件下預先訓練神經網路學習新的“ boot」類(橄欖綠),直到性能平穩:1)FoL(共n=6000張圖像/epoch);2)FIL(共n=54000張圖像/epoch);3) PIL(共n=350張圖像/ epoch);4) SWIL(共n=350張圖像/epoch)和5) EqWIL(共n=350張圖像/epoch)。 (B)FoL(黑色)、FIL(藍色)、PIL(棕色)、SWIL(洋紅色)和EqWIL(金色)預測新類別、相似舊類別(“sneaker”和“sandals”)和不同舊類別的召回率,預測所有類別的總準確率,以及在測試資料集上的交叉熵損失,其中橫座標都是epoch數。
基於CIFAR10使用SWIL在CNN中學習新類別
接下來,為了測試SWIL是否可以在更複雜的環境中工作,作者團隊訓練了一個具有全連接輸出層的6層非線性CNN(圖4A),以識別CIFAR10資料集中剩餘8個不同類別(「cat」和「car」除外)的圖像。他們也對模型進行了重新訓練,在先前定義的5種不同訓練條件(FoL、FIL、PIL、SWIL和EqWIL)下學習「cat」(「貓」)類。圖4C顯示了5種情況下每類影像的分佈。對於SWIL、PIL和EqWIL條件,每個epoch的總影像數為2400,而對於FIL和FoL,每個epoch的總影像數分別為45000和5000。作者團隊針對每種情況對網路分別進行訓練,直到效能趨於穩定。
他們在之前未見過的總共9000張圖像(1000張圖像/類,不包括「car」(「轎車」)類)上對該模型進行了測試。圖4B是作者團隊基於CIFAR10資料集計算的相似性矩陣。 「cat」類和「dog」(「狗」)類更類似,而其他動物類屬於同一分支(圖4B左)。
#根據樹狀圖(圖4B),將「truck」 (「貨車」)、「ship」(「輪船」) 和「plane」(「飛機」) 類別稱為不同的舊類別,除「cat 「類外其餘的動物類別稱為相似的舊類別。對於FoL,模型學習了新的「cat」類,但遺忘了舊類別。與Fashion-MNIST資料集結果類似,「dog」類別(與「cat」類相似性最大)和「truck」類別(與「cat」類相似性最小)均存在幹擾梯度,其中「dog」類的遺忘率最高,而「truck」類別遺忘率最低。
如圖4D所示,FIL演算法學習新的「cat」類別時克服了災難性的干擾。對於PIL演算法,模型在每個epoch使用18.75倍的資料量學習新的「cat」類,但「cat」類的召回率比FIL(H=5.72,P0.05;見表2和圖4D )。 SWIL對新「cat」類別的回想率高於PIL(H=7.89,P
FIL、PIL、SWIL和EqWIL這4種演算法預測不同舊類別的表現相當(H=0.6,P>0.05)。 SWI比PIL更好地融合了新的「cat」類,並有助於克服EqWIL中的觀測幹擾。與FIL相比,使用SWIL學習新類別速度更快,加速比=31.25x (45000×10/(2400×6)),同時使用更少的資料量 (記憶體比=18.75x)。這些結果證明,即使在非線性CNN和更真實的資料集上,SWIL也可以有效學習新類別事物。
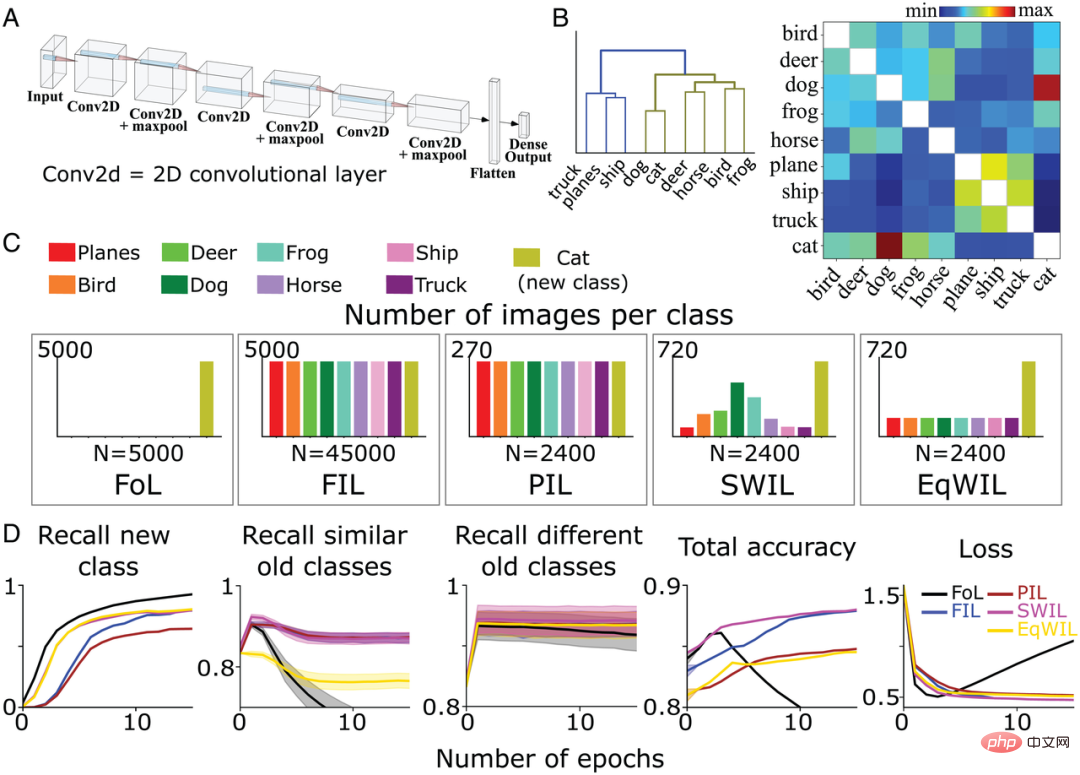
#圖4:( A ) 作者團隊使用具有全連接輸出層的6層非線性CNN學習CIFAR10數據集中的8類事物。 ( B ) 相似度矩陣 (右)是在呈現新的「cat」類別之後,作者團隊根據最後一個卷積層的激活函數計算獲得。對相似矩陣應用層次聚類(左),在樹狀圖中顯示動物(橄欖綠)和交通工具(藍色)兩個上義詞類別的分組情況。 ( C ) 作者團隊在5種不同的條件下預訓練CNN學習新的「cat」類(橄欖綠),直到性能平穩:1)FoL(共n=5000張圖像/epoch);2)FIL(共n =45000張影像/epoch);3) PIL(共n=2400張影像/epoch);4) SWIL(共n=2400張影像/epoch);5) EqWIL(共n=2400張影像/epoch)。每個條件重複10次。 (D)FoL(黑色)、FIL(藍色)、PIL(棕色)、SWIL(洋紅色)和EqWIL(金色)預測新類別、相似舊類別(CIFAR10資料集中的其他動物類)和不同舊類別( 「plane」 、「ship」 和「truck」)的召回率,預測所有類別的總準確率,以及在測試資料集上的交叉熵損失,其中橫座標都是epoch數。
新內容與舊類別的一致性對學習時間和所需資料的影響
如果一項新內容可以新增到先前學習過的類別中,而不需要對網路進行較大更改,則稱二者俱有一致性。基於此框架,與幹擾多個現有類別(低一致性)的新類別相比,學習幹擾較少現有類別(高一致性)的新類別可以更容易地整合到網路中。
為了測試上述推斷,作者團隊使用上一節中經過預訓練的CNN,在前面描述的所有5種學習條件下,學習了一個新的「car」類別。圖5A顯示了「car」類別的相似性矩陣,與其他現有類別相比,「car」和「truck」、「ship」和「plane」在同一層次節點下,說明它們更相似。為了進一步確認,作者團隊在用於相似性計算的活化層上進行了t-SNE降維可視化分析(圖5B)。研究發現「car」類與其他交通工具類(「truck」、「ship」和「plane」)有顯著重疊,而「cat」類與其他動物類(「dog」、 「frog」(「青蛙」) 、「horse」(「馬」)、「bird」(「鳥」)和「deer」(「鹿」))有重疊。
和作者團隊預期相符,FoL學習「car」類別時會產生災難性幹擾,對相近的舊類別幹擾性更強,而使用FIL克服了這一點(圖5D)。對於PIL、SWIL和EqWIL,每個epoch總共有n=2000張影像(圖5C)。使用SWIL演算法,模型學習新的「car」類別可以達到和FIL(H=0.79,P>0.05)相近的精度,而對現有類別(包括相似和不同類別)的干擾最小。如圖5D第2列所示,使用EqWIL,模型學習新「car」類的方式與SWIL相同,但對其他相似類別(例如「truck」)的干擾程度較高(H=53.81,P
#與FIL相比,SWIL可以更快學習新內容,加速比=48.75x(45000×12/(2000×6)),記憶體需求減少,記憶體比=22.5x。與「cat」(48.75x vs.31.25x)相比,「car」可以透過交錯更少的類別(如「truck」、「ship」和「plane」)更快地學習,而「cat」與更多的類別(如“dog” 、“frog” 、“horse” 、“frog” 和“deer”)重疊。這些模擬實驗表明,交叉和加速學習新類別所需的舊類別資料量,取決於新資訊與先驗知識的一致性。
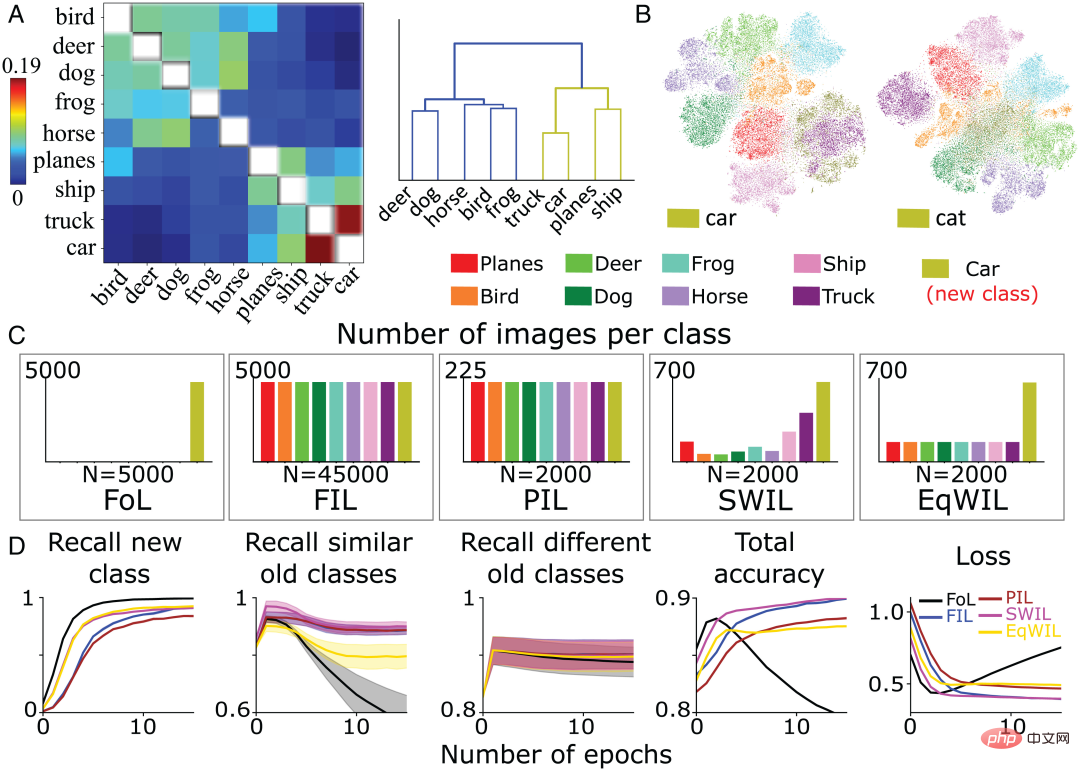
圖5:( A ) 作者團隊根據倒數第二層啟動函數計算獲得相似度矩陣(左) ,以及呈現新的「car」類別後對相似度矩陣進行層次聚類後的結果圖(右)。 ( B ) 模型分別學習新的「car」類別和「cat」類別,經過最後一個卷積層過激活函數後,作者團隊進行t-SNE降維可視化的結果圖。 ( C ) 作者團隊在5種不同的條件下預訓練CNN學習新的「car」類(橄欖綠),直到性能平穩:1)FoL(共n=5000張圖像/epoch);2)FIL(共n =45000張影像/epoch);3) PIL(共n=2000張影像/epoch);4) SWIL(共n=2000張影像/epoch);5) EqWIL(共n=2000張影像/epoch)。 (D)FoL(黑色)、FIL(藍色)、PIL(棕色)、SWIL(洋紅色)和EqWIL(金色)預測新類別、相似舊類別(“plane” 、“ship” 和“truck”)和不同舊類別(CIFAR10資料集中的其他動物類)的召回率,預測所有類別的總準確率,以及在測試資料集上的交叉熵損失,其中橫座標都是epoch數。每張圖顯示的是重複10次後的平均值,陰影區域為±1 SEM。
利用SWIL進行序列學習
接下來,作者團隊測試是否可以使用SWIL學習序列化形式呈現的新內容(序列學習框架)。為此他們採用了圖4中經過訓練的CNN模型,在FIL和SWIL條件下學習CIFAR10資料集中的「cat」類別(任務1),只在CIFAR10的剩餘9個類別上訓練,然後在每個條件下訓練模型學習新的「car」類別(任務2)。圖6第1列顯示了SWIL條件下學習「car」類別時,其他各項類別的影像數量分佈(共n=2500張影像/epoch)。需要注意的是,預測「cat」類別時也會交叉學習新的「car」類別。由於在FIL條件下模型性能最佳,SWIL僅與FIL進行了結果比較。
如圖6所示,SWIL預測新、舊類別的能力與FIL相當(H=14.3,P>0.05)。模型使用SWIL演算法可以更快地學習新的「car」類別,加速比為45x(50000×20/(2500×8)),每個epoch的記憶體佔用量比FIL少20倍。模型學習「cat」和「car」類別時,在SWIL條件下每個epoch使用的圖像數量(內存比和加速比分別為18.75x 和20x),少於在FIL條件下每個epoch使用的整個數據集(內存比和加速比分別為31.25x 和45x),並且仍然可以快速學習新類別。擴展這個思想,隨著學過的類別數目不斷增加,作者團隊預期模型的學習時間和資料儲存會倍增,從而更有效率地學習新類別,這或許反映了人類大腦實際學習時的情況。
實驗結果表明,SWIL可在序列學習框架中整合多個新類,使神經網路能夠在不受干擾的情況下持續學習。
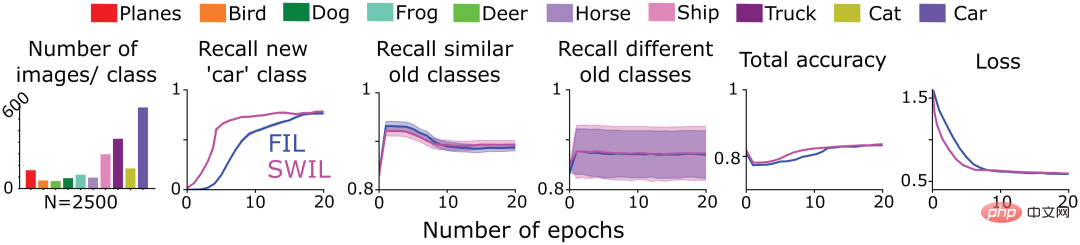
圖6:作者團隊訓練6層CNN學習新的「cat」類別(任務1),然後學習「car」類(任務2),直到性能在以下兩種情況下趨於穩定:1)FIL:包含所有舊類別(以不同顏色繪製)和以相同機率呈現的新類別(「cat」/「car ”)圖像;2) SWIL:根據與新類別(“cat”/“car”)的相似性進行加權並按比例使用舊類別示例。同時將任務1中學習的「cat」類別納入,並根據任務2中學習「car」類別的相似性進行加權。第1張子圖表示每個epoch使用的影像數量分佈情況,其餘各子圖分別表示FIL(藍色)和SWIL(洋紅色)預測新類別、相似舊類別和不同舊類別的召回率,預測所有類別的總準確率,以及在測試資料集上的交叉熵損失,其中橫座標都是epoch數。
利用SWIL擴大類別間的距離,減少學習時間和資料量
作者團隊最後測試了SWIL演算法的泛化性,驗證其是否可以學習包含更多類別的資料集,以及是否適用於更複雜的網路架構。
#他们在CIFAR100数据集(训练集500张图像/类,测试集100张图像/类)上训练了一个复杂的CNN模型-VGG19(共有19层),学习了其中的90个类别。然后对网络进行再训练,学习新类别。图7A显示了基于CIFAR100数据集,作者团队根据倒数第二层的激活函数计算的相似性矩阵。如图7B所示,新“train”(“火车”)类与许多现有的交通工具类别(如“bus” (“公共汽车”)、“streetcar” (“有轨电车”)和“tractor”(“拖拉机”)等)很相似。
与FIL相比,SWIL可以更快地学习新事物(加速比=95.45x (45500×6/(1430×2)))并且使用的数据量 (内存比=31.8x) 显著减少,而性能基本相同(H=8.21, P>0.05) 。如图7C所示,在PIL(H=10.34,P
同时,为了探索不同类别表征之间的较大距离是否构成了加速模型学习的基本条件,作者团队另外训练了两种神经网络模型:
- 6层CNN(与基于CIFAR10的图4和图5相同);
- VGG11(11层)学习CIFAR100数据集中的90个类别,仅在FIL和SWIL两个条件下对新的“train”类进行训练。
如图7B所示,对于上述两种网络模型,新的“train”类和交通工具类别之间的重叠度更高,但与VGG19模型相比,各类别的分离度较低。与FIL相比,SWIL学习新事物的速度与层数的增加大致呈线性关系(斜率=0.84)。该结果表明,类别间表征距离的增加可以加速学习并减少内存负载。
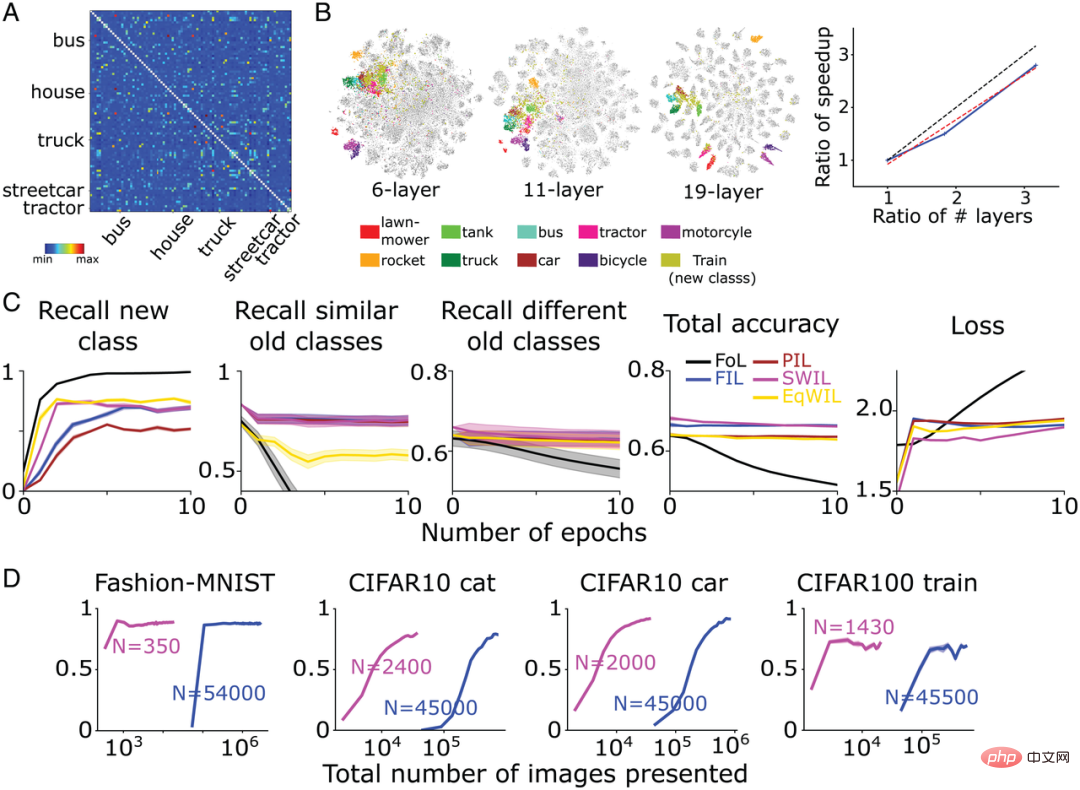
图7:( A ) VGG19学习新的“train”类后,作者团队根据倒数第二层激活函数计算的相似性矩阵。“truck” 、“streetcar” 、“bus” 、“house” 和 “tractor”5种类别与“train”的相似性最大。从相似度矩阵中排除对角元素(相似度 =1)。(B,左)作者团队针对6层CNN、VGG11和VGG19网络,经过倒数第二层激活函数后,进行t-SNE降维可视化的结果图。(B,右)纵轴表示加速比(FIL/SWIL),横轴表示3个不同网络的层数相对于6层CNN的比率。黑色虚线、红色虚线和蓝色实线分别代表斜率 =1的标准线、最佳拟合线和仿真结果。( C ) VGG19模型的学习情况:FoL(黑色)、FIL(蓝色)、PIL(棕色)、SWIL(洋红色)和 EqWIL(金色)预测新“train”类、相似旧类别(交通工具类别)和不同旧类别(除了交通工具类别)的召回率,预测所有类别的总准确率,以及在测试数据集上的交叉熵损失,其中横坐标都是epoch数。每张图显示的是重复10次后的平均值,阴影区域为±1 SEM。( D ) 从左到右依次表示模型预测Fashion-MNIST“boot”类(图3)、CIFAR10“cat”类(图4)、CIFAR10“car”类(图5)和CIFAR100“train”类的召回率,是SWIL(洋红色)和FIL(蓝色)使用的图像总数(对数比例)的函数。“N”表示每种学习条件下每个epoch使用的图像总数(包括新、旧类别)。
如果在更多非重叠类上训练网络,并且各表征之间的距离更大,速度是否会进一步提升?
为此,作者团队采用了一个深度线性网络(用于图1-3中的Fashion-MNIST示例),并对其进行训练,以学习由8个Fashion-MNIST类别(不包括“bags”和“boot”类)和10个Digit-MNIST类别形成的组合数据集,然后训练网络学习新的“boot”类别。
和作者团队的预期相符,“boot”与旧类别“sandals”和“sneaker”相似度更高,其次是其余的Fashion-MNIST类(主要包括服饰类图像),最后Digit-MNIST类(主要包括数字类图像)。
基于此,作者团队首先交织了更多相似的旧类别样本,再交织Fashion-MNIST和Digit-MNIST类样本(共计n=350张图像/epoch)。实验结果表明,与FIL类似,SWIL可以快速学习新类别内容而不受干扰,但使用的数据子集要小得多,内存比为325.7x (114000/350) ,加速比为162.85x (228000/1400)。作者团队在当前结果中观察到的加速比为2.1x (162.85/77.1),与Fashion-MNIST数据集相比,类别数目增加了 2.25倍 (18/8)。
本節的實驗結果有助於確定SWIL可以適用於更複雜的資料集 (CIFAR100) 和神經網路模型(VGG19),證明了此演算法的泛化性。同時證明了擴大類別之間的內部距離或增加非重疊類別的數量,可能會進一步提高學習速度並降低記憶體負載。
總結
人工神經網路在持續學習方面面臨重大挑戰,通常表現出災難性幹擾。為了克服這個問題,許多研究都使用了完全交錯學習(FIL),即新舊內容交叉學習,共同訓練網路。 FIL需要在每次學新資訊時交織所有現有訊息,使其成為一個生物學意義上不可信且耗時的過程。最近,有研究顯示FIL可能並非必需,僅交錯與新內容具有實質表徵相似性的舊內容,即採用相似性加權交錯學習(SWIL)的方法可以達到相同的學習效果。然而,有人對SWIL的可擴展性表示了擔憂。
本文擴展了SWIL演算法,並基於不同的資料集(Fashion-MNIST、CIFAR10 和 CIFAR100)和神經網路模型(深度線性網路和CNN)對其進行了測試。在所有條件下,與部分交錯學習(PIL)相比,相似性加權交錯學習(SWIL)和等權交錯學習(EqWIL)在學習新類別的表現較好。這和作者團隊的預期相符,因為與舊類別相比,SWIL和EqWIL增加了新類別的相對頻率。
本文同時也證明,與同等子抽樣現有類別(即EqWIL方法)相比,仔細選擇和交織相似內容減少了對相近舊類別的災難性幹擾。在預測新類別和現有類別方面,SWIL的表現與FIL類似,卻顯著加快了學習新內容的速度(圖7D),同時大幅減少了所需的訓練資料。 SWIL可以在序列學習框架中學習新類別,進一步證明了其泛化能力。
最後,與許多舊類別具有相似性的新類別相比,如果其與之前學過的類別重疊更少(距離更大),可以縮短集成時間,並且數據效率更高。總體來說,實驗結果提供了一種可能的見解,大腦事實上透過減少不切實際的訓練時間,克服了原始CLST模型的一個主要弱點。
以上是研究顯示:基於相似性加權交錯學習可有效應對深度學習中的「失憶症」問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度學習方法專注於設計最適合的目標函數,以使模型的預測結果與實際情況最接近。同時,必須設計一個合適的架構,以便為預測取得足夠的資訊。現有方法忽略了一個事實,當輸入資料經過逐層特徵提取和空間變換時,大量資訊將會遺失。本文將深入探討資料透過深度網路傳輸時的重要問題,即資訊瓶頸和可逆函數。基於此提出了可編程梯度資訊(PGI)的概念,以應對深度網路實現多目標所需的各種變化。 PGI可以為目標任務提供完整的輸入訊息,以計算目標函數,從而獲得可靠的梯度資訊以更新網路權重。此外設計了一種新的輕量級網路架
 一文通覽自動駕駛三大主流晶片架構
Apr 12, 2023 pm 12:07 PM
一文通覽自動駕駛三大主流晶片架構
Apr 12, 2023 pm 12:07 PM
目前主流的AI晶片主要分為三類,GPU、FPGA、ASIC。 GPU、FPGA皆是前期較成熟的晶片架構,屬於通用型晶片。 ASIC屬於為AI特定場景定制的晶片。業界已經確認CPU不適用於AI計算,但在AI應用領域也是不可或缺。 GPU方案GPU與CPU的架構比較CPU遵循的是馮諾依曼架構,其核心是儲存程式/資料、序列順序執行。因此CPU的架構中需要大量的空間去放置儲存單元(Cache)和控制單元(Control),相較之下運算單元(ALU)只佔據了很小的一部分,所以CPU在進行大規模平行運算
 'B站UP主成功打造全球首個基於紅石的神經網絡在社交媒體引起轟動,得到Yann LeCun的點贊讚賞'
May 07, 2023 pm 10:58 PM
'B站UP主成功打造全球首個基於紅石的神經網絡在社交媒體引起轟動,得到Yann LeCun的點贊讚賞'
May 07, 2023 pm 10:58 PM
在我的世界(Minecraft)中,紅石是一種非常重要的物品。它是遊戲中獨特的材料,開關、紅石火把和紅石塊等能對導線或物體提供類似電流的能量。紅石電路可以為你建造用於控製或激活其他機械的結構,其本身既可以被設計為用於響應玩家的手動激活,也可以反複輸出信號或者響應非玩家引發的變化,如生物移動、物品掉落、植物生長、日夜更替等等。因此,在我的世界中,紅石能夠控制的機械類別極其多,小到簡單機械如自動門、光開關和頻閃電源,大到佔地巨大的電梯、自動農場、小遊戲平台甚至遊戲內建的計算機。近日,B站UP主@
 多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
多路徑多領域通吃! GoogleAI發布多領域學習通用模型MDL
May 28, 2023 pm 02:12 PM
面向視覺任務(如影像分類)的深度學習模型,通常使用單一視覺域(如自然影像或電腦生成的影像)的資料進行端到端的訓練。一般情況下,一個為多個領域完成視覺任務的應用程式需要為每個單獨的領域建立多個模型,分別獨立訓練,不同領域之間不共享數據,在推理時,每個模型將處理特定領域的輸入資料。即使是面向不同領域,這些模型之間的早期層的有些特徵都是相似的,所以,對這些模型進行聯合訓練的效率更高。這能減少延遲和功耗,降低儲存每個模型參數的記憶體成本,這種方法稱為多領域學習(MDL)。此外,MDL模型也可以優於單
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
你知道程式設計師再過幾年會沒落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》雜誌曾經寫過一篇文章,說“編程到1960年就會消失”,因為IBM開發了一種新語言FORTRAN,這種新語言可以讓工程師寫出他們所需的數學公式,然後提交給電腦運行,所以程式設計就會終結。圖片又過了幾年,我們聽到了一種新說法:任何業務人員都可以使用業務術語來描述自己的問題,告訴電腦要做什麼,使用這種叫做COBOL的程式語言,公司不再需要程式設計師了。後來,據說IBM開發了一門名為RPG的新程式語言,可以讓員工填寫表格並產生報告,因此大部分企業的程式設計需求都可以透過它來完成圖
 探索使用對比損失的孿生網路進行影像相似性比較
Apr 02, 2024 am 11:37 AM
探索使用對比損失的孿生網路進行影像相似性比較
Apr 02, 2024 am 11:37 AM
簡介在電腦視覺領域,準確地測量影像相似性是一項關鍵任務,具有廣泛的實際應用。從圖像搜尋引擎到人臉辨識系統和基於內容的推薦系統,有效比較和尋找相似圖像的能力非常重要。 Siamese網路與對比損失相結合,為數據驅動方式學習影像相似性提供了強大的框架。在這篇文章中,我們將深入了解Siamese網路的細節,探討對比損失的概念,並探討這兩個組件如何共同運作以創建一個有效的圖像相似性模型。首先,Siamese網路由兩個相同的子網路組成,這兩個子網路共享相同的權重和參數。每個子網路將輸入圖像編碼為特徵向量,這
