
#堆,又稱為優先隊列,是完全二元樹,它的每個父節點的值只會小於或等於所有孩子節點(的值)。它使用了數組來實現:從零開始計數,對於所有的k ,都有 heap[k] 。為了便於比較,不存在的元素被認為是無限大。堆最有趣的特性在於最小的元素總是根結點:heap[0]。
python的堆一般都是最小堆,與許多教材上的內容有所不同,教材上大多以最大堆,由於堆的表示方法,從上到下,從左到右存儲,與列表十分相似,因此創建一個堆,可以使用list來初始化為[] ,或者你可以透過一個函數heapify() ,來把一個list轉換成堆。如下是python中關於堆的相關操作,從這可以看出,python確實是將堆看作是列表去處理的。
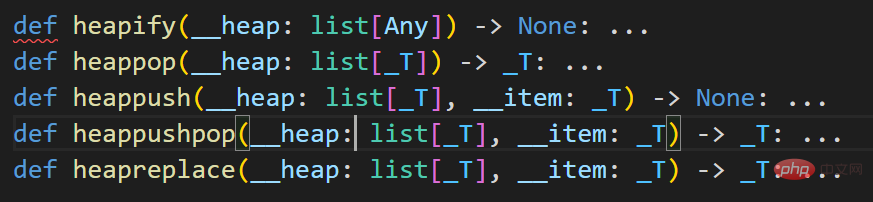
將item 的值加入heap 中,保持堆的不變性。會自動依據python中的最小堆特性,交換相關元素使得堆的根節點元素始終不大於子節點元素。
原有資料是堆
import heapq h = [1, 2, 3, 5, 7] heapq.heappush(h, 2) print(h) #输出 [1, 2, 2, 5, 7, 3]
操作流程如下:
1.如下是初始狀態
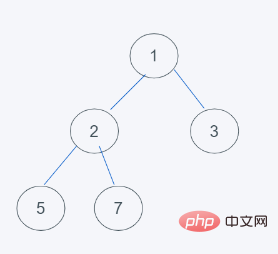
2.加入了2元素之後
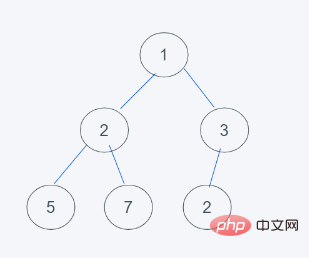
#3.由於不符合最小堆的特性,因此與3交換
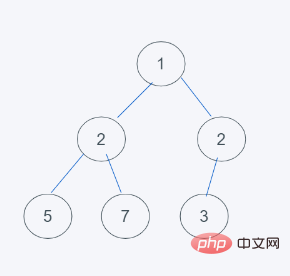
4.符合最小堆的特性,交換結束,因此結果是[1, 2, 3, 5, 7, 3]
原有資料不是堆
import heapq h = [5, 2, 1, 4, 7] heapq.heappush(h, 2) print(h) #输出 [5, 2, 1, 4, 7, 2]
由此可見,當進行push操作時,元素不是堆的情況下,預設會依照列表的append方法進行新增元素
彈出並傳回heap 的最小的元素,保持堆的不變性。如果堆為空,拋出 IndexError 。使用 heap[0] ,可以只存取最小的元素而不彈出它。
原有資料是堆疊
import heapq h = [1, 2, 3, 5, 7] heapq.heappop(h) print(h) #输出 [2, 5, 3, 7]
操作流程如下:
1.初始狀態
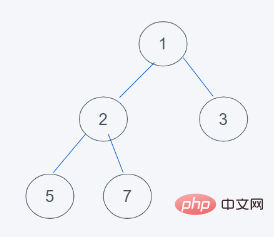
2.刪除了堆頂元素,末尾元素移入堆頂
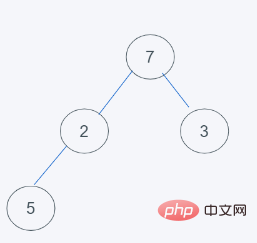
#3.依據python最小堆的特性進行交換元素,由於7>2,交換7和2
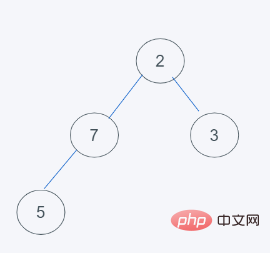
4.依據python最小堆的特性進行交換元素,由於7>5,交換7和5
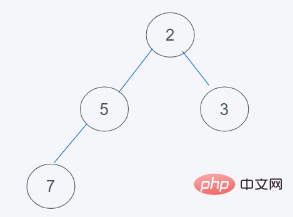
#5.符合堆的要求,即結果為[2, 5, 3, 7]
原有資料不是堆
import heapq h = [5, 2, 1, 4, 7] heapq.heappop(h) print(h) [1, 2, 7, 4]
操作流程如下:
1.初始狀態,很明顯不符合堆的性質
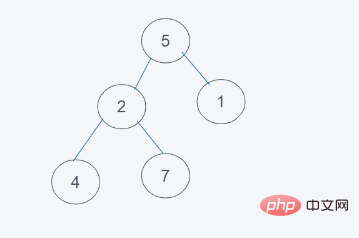
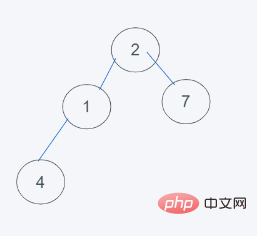
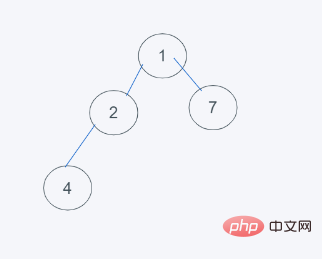
import heapq h = [1, 2, 3, 5, 7] min_data = heapq.heappushpop(h, 2) print(min_data) print(h) #输出 1 [2, 2, 3, 5, 7]
操作流程如下
#1.初始狀態
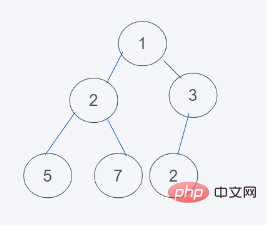
3.删除最小元素,刚好是堆顶元素1,并使用末尾元素2代替
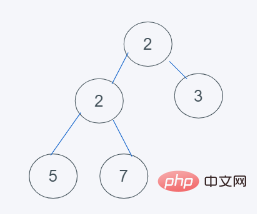
4.符合要求,即结果为[2, 2, 3, 5, 7]
原有数据不是堆
h = [5, 2, 1, 4, 7] min_data = heapq.heappushpop(h, 2) print(min_data) print(h) min_data = heapq.heappushpop(h, 6) print(min_data) print(h) #输出 2 [5, 2, 1, 4, 7] 5 [1, 2, 6, 4, 7]
对于插入元素6的操作过程如下
1.初始状态
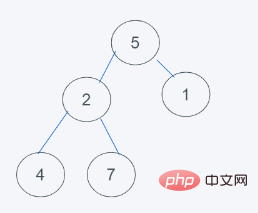
2.插入元素6之后
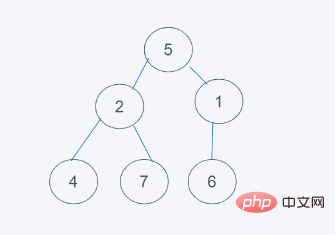
3.发现元素6大于堆顶元素5,弹出堆顶元素5,由堆尾元素6替换
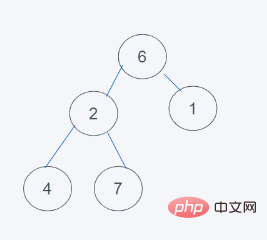
4.依据python的最小堆特性,元素6>元素1且元素6>元素2,但元素2>元素1, 交换6与1
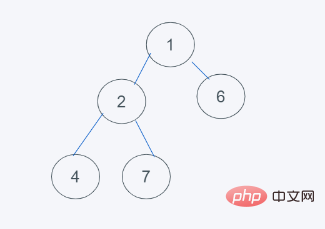
5.符合要求,则结果为[1, 2, 6, 4, 7]
由结果可以看出,当插入元素小于堆顶元素时,则堆不会发生改变,当插入元素大于堆顶元素时,则堆依据python堆的最小堆特性处理。
将列表转换为堆。
h = [1, 2, 3, 5, 7] heapq.heapify(h) print(h) h = [5, 2, 1, 4, 7] heapq.heapify(h) print(h) #输出 [1, 2, 3, 5, 7] [1, 2, 5, 4, 7]
会自动将列表依据python最小堆特性进行重新排列。
弹出并返回最小的元素,并且添加一个新元素item,这个单步骤操作比heappop()加heappush() 更高效。适用于堆元素数量固定的情况。
返回的值可能会比添加的 item 更大。 如果不希望如此,可考虑改用heappushpop()。 它的 push/pop 组合会返回两个值中较小的一个,将较大的值留在堆中。
import heapq h = [1, 2, 3, 5, 7] heapq.heapreplace(h, 6) print(h) h = [5, 2, 1, 4, 7] heapq.heapreplace(h, 6) print(h) #输出 [2, 5, 3, 6, 7] [1, 2, 6, 4, 7]
原有数据是堆
对于插入元素6的操作过程如下:
1.初始状态
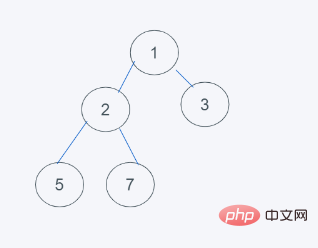
2.弹出最小元素,只能弹出堆顶或者堆尾的元素,很明显,最小元素是1,弹出1,插入元素是6,代替堆顶元素
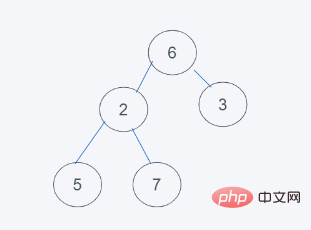
3.依据python堆的最小堆特性,6>2,交换6与2
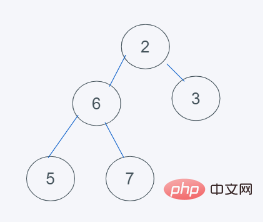
4.依据python堆的最小堆特性,6>5,交换6与5
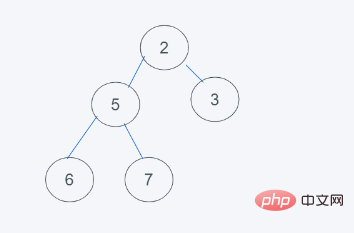
5.符合要求,则结果为[2, 5, 3, 6 ,7]
原有数据不是堆
对于插入元素6的操作过程如下:
1.初始状态
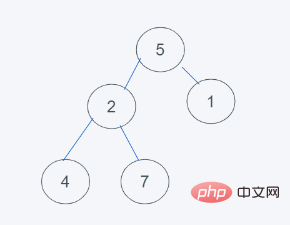
2.对于数据不为堆的情况下,默认移除第一个元素,这里就是元素5,然后插入元素6到堆顶
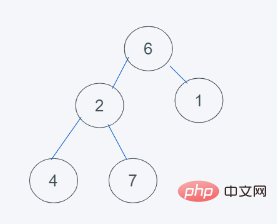
3.依据python的最小堆特性,元素6>1,交换元素6与1
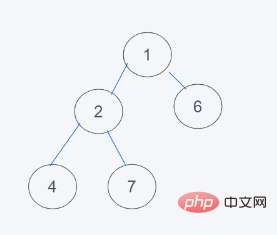
4.符合要求,即结果为[1, 2, 6, 4, 7
将多个已排序的输入合并为一个已排序的输出(例如,合并来自多个日志文件的带时间戳的条目)。 返回已排序值的 iterator。注意需要是已排序完成的可迭代对象(默认为从小到大排序),当reverse为True时,则为从大到小排序。
从 iterable 所定义的数据集中返回前 n 个最大元素组成的列表。 如果提供了 key 则其应指定一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。
等价于: sorted(iterable, key=key, reverse=True)[:n]。
import time
import heapq
h = [1, 2, 3, 5, 7]
size = 1000000
start = time.time()
print(heapq.nlargest(3, h))
for i in range(size):
heapq.nlargest(3, h)
print(time.time() - start)
start = time.time()
print(sorted(h, reverse=True)[:3:])
for i in range(size):
sorted(h, reverse=True)[:3:]
print(time.time() - start)
#输出
[7, 5, 3]
1.6576552391052246
[7, 5, 3]
0.2772986888885498
[7, 5, 4]由上述结构可见,heapq.nlargest与sorted(iterable, key=key, reverse=False)[:n]功能是类似的,但是性能方面还是sorted较为快速。
从 iterable 所定义的数据集中返回前 n 个最小元素组成的列表。 如果提供了 key 则其应指定一个单参数的函数,用于从 iterable 的每个元素中提取比较键 (例如 key=str.lower)。 等价于: sorted(iterable, key=key)[:n]。
import time
import heapq
h = [1, 2, 3, 5, 7]
size = 1000000
start = time.time()
print(heapq.nsmallest(3, h))
for i in range(size):
heapq.nsmallest(2, h)
print(time.time() - start)
start = time.time()
print(sorted(h, reverse=False)[:3:])
for i in range(size):
sorted(h, reverse=False)[:2:]
print(time.time() - start)
#输出
[1, 2, 3]
1.1738648414611816
[1, 2, 3]
0.2871997356414795由上述结果可见,sorted的性能比后面两个函数都要好,但如果只是返回最大的或者最小的一个元素,则使用max和min最好。
由于在python中堆的特性是最小堆,堆顶的元素始终是最小的,可以将序列转换成堆之后,再使用pop弹出堆顶元素来实现从小到大排序。具体实现如下:
from heapq import heappush, heappop, heapify
def heapsort(iterable):
h = []
for value in iterable:
heappush(h, value)
return [heappop(h) for i in range(len(h))]
def heapsort2(iterable):
heapify(iterable)
return [heappop(iterable) for i in range(len(iterable))]
data = [1, 3, 5, 7, 9, 2, 4, 6, 8, 0]
print(heapsort(data))
print(heapsort2(data))
#输出
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]from heapq import heappush, heappop h = [] heappush(h, (5, 'write code')) heappush(h, (7, 'release product')) heappush(h, (1, 'write spec')) heappush(h, (3, 'create tests')) print(h) print(heappop(h)) [(1, 'write spec'), (3, 'create tests'), (5, 'write code'), (7, 'release product')] (1, 'write spec')
上述操作流程如下:
1.当进行第一次push(5, ‘write code’)时

2.当进行第二次push(7, ‘release product’)时,符合堆的要求
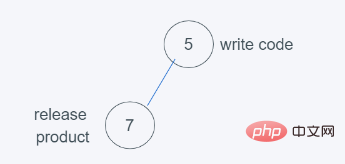
3.当进行第三次push(1, ‘write spec’)时,
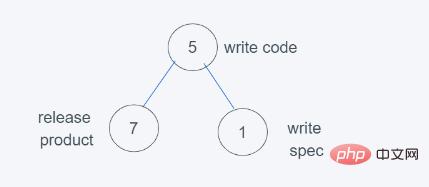
4.依据python的堆的最小堆特性,5>1 ,交换5和1
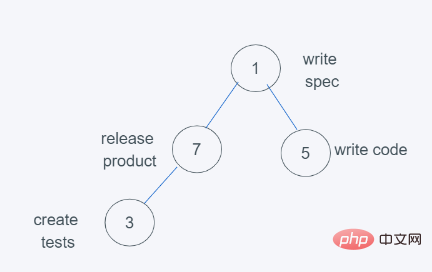
5.当进行最后依次push(3, ‘create tests’)时
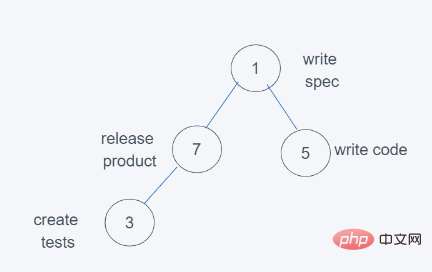
6.依据python堆的最小堆特性,7>3,交换7与3
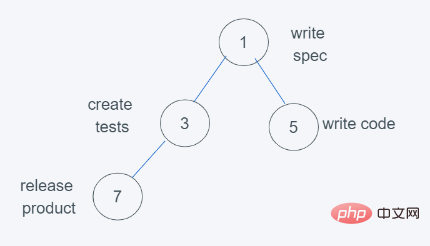
7.符合要求,因此结果为[(1, ‘write spec’), (3, ‘create tests’), (5, ‘write code’), (7, ‘release product’)],弹出元素则是堆顶元素,数字越小,优先级越大。
以上是python內建堆如何實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















