

只要模型夠大、樣本夠多,AI就可以變得更聰明!

AI模型與人腦在數學機制上並沒有什麼不同。
只要模型夠大、樣本夠多,AI就可以變得更聰明!
chatGPT的出現,其實已經證明了這一點。
1,AI和人腦的底層細節都是基於if else語句
邏輯運算,是產生智慧的基礎運算。
程式語言的基本邏輯是if else,它會根據條件運算式把程式碼分成兩個分支。
在這個基礎上,程式設計師可以寫出非常複雜的程式碼,實現各種各樣的業務邏輯。
人腦的基本邏輯也是if else,if else這兩個字就來自英語,對應的中文詞彙是如果...否則...
人腦在思考問題時也是這麼一個邏輯思路,這點上跟電腦沒有差別。
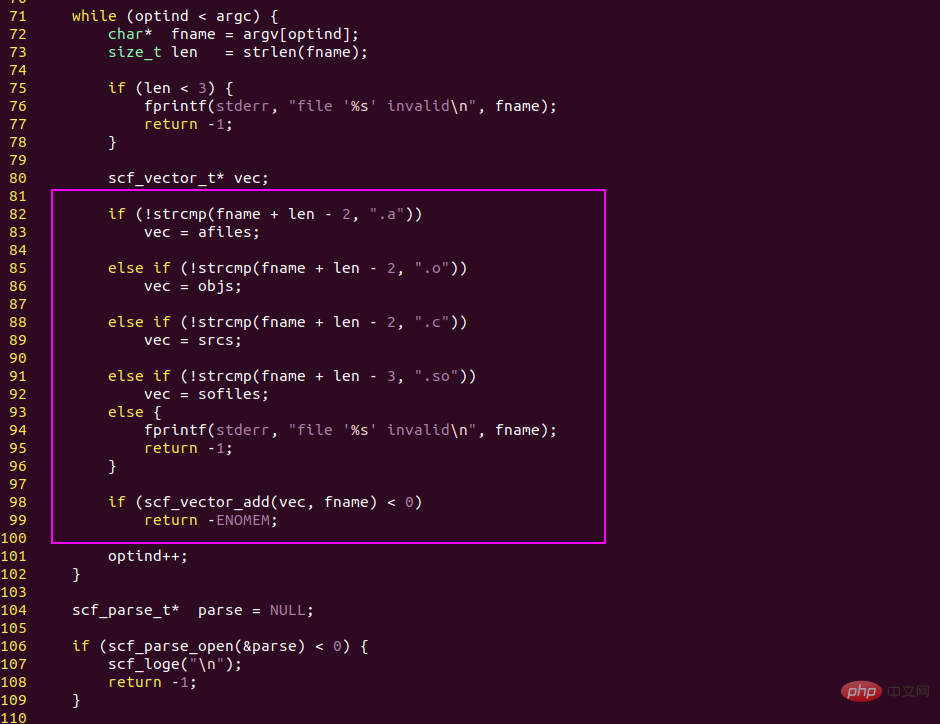
if else語句,邏輯的核心
#AI模型的「if else語句」就是啟動函數!
AI模型的一個運算節點,我們也可以叫它「神經元」。
它有一個輸入向量X,一個權值矩陣W,一個偏移向量b,還有一個激活函數。
激活函數的作用實際上就是if else語句,而WX b這個線性運算就是條件式。
在啟動之後,AI模型的程式碼相當於在 if分支,而不啟動時相當於執行在else分支。
多層神經網路的不同活化狀態,其實也是對樣本資訊的二元編碼。
深度學習也是對樣本資訊的二進位編碼
AI模型對樣本資訊的編碼是動態的、平行的,而不是和CPU程式碼一樣是靜態的、串列的,但它們的底層基礎都是if else。
在電路層面要實現if else並不難,一個三極管就可以實現。
2,人腦比電腦聰明,是因為人類獲得的資訊更多
人腦每時每刻都在獲取外界的信息,每時每刻都在更新自己的“樣本資料庫”,但程式碼無法自我更新,這是很多人能做到的事而電腦做不到的原因。
人腦的程式碼是活的,電腦的程式碼是死的。
「死程式碼」當然不可能比「活碼」更聰明,因為「活碼」可以主動找「死碼」的BUG。
而根據實數的連續性,只要「死代碼」編碼的資訊是可數的,那麼它就總存在編碼不到的BUG點。
這在數學上可以用康托三分集來佐證。
不管我們用多少位的三進位小數去編碼[0, 1]區間上的實數,總有至少1個點是沒法編碼進去的。
所以當兩個人抬槓的時候,總是能找到可抬槓的點
但是電腦的程式碼一旦寫好就沒辦法主動更新了,所以程式設計師可以想出各種辦法欺騙CPU。
例如,intel的CPU本來要求在進程切換時要切換任務門的,但Linux就想出了一個辦法只切換頁目錄和RSP寄存器
在intel CPU看來,Linux系統一直在運行同一個進程,但實際上不是。這就是所謂的進程軟切換。
所以,只要CPU的電路固定了,那麼CPU編碼的資訊也就固定了。
CPU編碼的資訊固定了,那麼它編碼不到的資訊就是無限的,就是可以被程式設計師利用的。
而程式設計師之所以可以利用這種訊息,是因為程式設計師的大腦是活的,可以動態的更新樣本。
3,神經網路的出現改變了這種情況
神經網路真是一個偉大的發明,它在固定的電路上實現了動態的資訊更新。
所有寫好的程式能處理的資訊都是固定的,包括CPU電路,也包含各種系統的程式碼。
但神經網路不是這樣,它的程式碼雖然是寫好的,但它只需要更新權值數據,就可以改變模型的邏輯脈絡。
實際上只要不斷地輸入新樣本,AI模型就可以不斷地用BP演算法(梯度下降演算法)更新權值數據,從而適應新的業務場景。
AI模型的更新不需要修改程式碼,而只需要修改數據,所以同樣的CNN模型用不同的樣本訓練,它就可以辨識不同的物體。
在這個過程中,不管是tensorflow框架的程式碼,或是AI模型的網路結構都是不變的,變的是每個節點的權值資料。
理論上來說,只要AI模型可以透過網路抓取數據,它就可以變得更聰明。
這跟人們透過瀏覽器看東西(從而變得更聰明),有本質的區別嗎?好像也沒有。
4,只要模型夠大、樣本夠多,或許ChatGPT真可以挑戰人腦
人腦有150億個神經元,而且人的眼睛和耳朵每時每刻都在給它新的數據,AI模型當然也可以做到這一點。
或許比起AI來,人類的優勢在於「產業鏈」更短
一個嬰兒的出生只需要Ta父母,但一個AI模型的誕生顯然不是一兩個程序員可以做到的。
光是GPU的製造業就不只幾萬人。
GPU上的CUDA程式並不難寫,但GPU製造的產業鏈太長了,遠不如人類的出生和成長。
這或許是AI相對於人的真正劣勢。
以上是只要模型夠大、樣本夠多,AI就可以變得更聰明!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 速度秒掉GPT-4o、22B擊敗Llama 3 70B,Mistral AI開放首個代碼模型
Jun 01, 2024 pm 06:32 PM
速度秒掉GPT-4o、22B擊敗Llama 3 70B,Mistral AI開放首個代碼模型
Jun 01, 2024 pm 06:32 PM
對標OpenAI的法國AI獨角獸MistralAI有了新動作:首個代碼大模型Codestral誕生了。作為一個專為程式碼產生任務設計的開放式產生AI模型,Codestral透過共享指令和補全API端點幫助開發人員編寫並與程式碼互動。 Codestral精通程式碼和英語,因而可為軟體開發人員設計高階AI應用。 Codestral的參數規模為22B,遵循新的MistralAINon-ProductionLicense,可用於研究和測試目的,但禁止商用。目前,該模型可以在HuggingFace上下載。下載地址
 清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
清華接手,YOLOv10問世:效能大幅提升,登上GitHub熱門榜
Jun 06, 2024 pm 12:20 PM
目標偵測系統的標竿YOLO系列,再次獲得了重磅升級。自今年2月YOLOv9發布之後,YOLO(YouOnlyLookOnce)系列的接力棒傳到了清華大學研究人員的手上。上週末,YOLOv10推出的消息引發了AI界的關注。它被認為是電腦視覺領域的突破性框架,以其即時的端到端目標檢測能力而聞名,透過提供結合效率和準確性的強大解決方案,延續了YOLO系列的傳統。論文網址:https://arxiv.org/pdf/2405.14458專案網址:https://github.com/THU-MIG/yo
 GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
GoogleGemini 1.5技術報告:輕鬆證明奧數題,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
今年2月,Google上線了多模態大模型Gemini1.5,透過工程和基礎設施最佳化、MoE架構等策略大幅提升了效能和速度。擁有更長的上下文,更強推理能力,可以更好地處理跨模態內容。本週五,GoogleDeepMind正式發布了Gemini1.5的技術報告,內容涵蓋Flash版等最近升級,該文件長達153頁。技術報告連結:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf在本報告中,Google介紹了Gemini1
 Mistral 開源程式碼模型奪得王座! Codestral瘋狂訓練超80種語言,國內通義開發者請求出戰!
Jun 08, 2024 pm 09:55 PM
Mistral 開源程式碼模型奪得王座! Codestral瘋狂訓練超80種語言,國內通義開發者請求出戰!
Jun 08, 2024 pm 09:55 PM
出品|51CTO技術棧(微訊號:blog51cto)Mistral發布了首個程式碼模型Codestral-22B!該模型的瘋狂之處不僅在於訓練了80多種程式語言,包括許多程式碼模型忽略的Swift等。他們的速度沒有完全一致。要求使用Go語言編寫一個「發布/訂閱」系統。這裡的GPT-4o正在輸出,Codestral已經快到看不清楚的速度交捲了!由於該模型剛剛推出,尚未公開測試。但根據Mistral的負責人說法,Codestral是目前表現最佳的開源程式碼模型。圖片有興趣的朋友可以移步:-抱抱臉:https
