
圖靈獎得主、深度學習先驅Hinton曾預言到,「人們現在應該停止訓練放射科醫生。很明顯,在五年內,深度學習會比放射科醫生做得更好。這可能需要10年的時間,但我們已經有了足夠多的放射科醫生。」
我認為,如果你是放射科醫生,你就像一隻已經走到懸崖邊緣、但還沒往下看的野狼。

近七年過去了,人工智慧技術僅參與並取代了部分放射員的技術工作,並且存在功能單一、訓練資料不足等問題,讓放射科醫師的飯碗依然握得很牢。
但ChatGPT類別的基礎模型發布後,人工智慧模型的能力得到了前所未有的提升,可以處理多模態資料、無需微調即可適應新任務的in-context學習能力,高度靈活、可重複使用的人工智慧模式的迅速發展或許會在醫學領域引入新的能力。
最近,來自多所美國哈佛大學、史丹佛大學、耶魯醫學院、加拿大多倫多大學等多所頂尖高校、醫療機構的研究人員在Nature上聯合提出了一種全新的醫學人工智慧範式,即「全科醫學人工智慧」(generalist medical artificial intelligence, GMAI)。

論文連結:https://www.nature.com/articles/s41586-023-05881-4
GMAI 模型將能夠使用很少或不使用任務特定的標記資料執行各種各樣的任務。透過對大型、多樣化資料集的自我監督訓練,GMAI可以靈活地解釋醫學模式的不同組合,包括來自影像、電子健康記錄、實驗室結果、基因組學、圖表或醫學文本的資料。
反過來,模型還可以產生具有表達能力的輸出,如自由文字解釋、口頭推薦或圖像註釋,展現先進的醫學推理能力。
研究人員在文中為 GMAI 確定了一組具有高影響力的潛在應用場景,並列出了具體的技術能力和訓練資料集。
作者團隊預計,GMAI 應用程式將會挑戰目前的驗證醫學AI設備,並改變與大型醫學資料集收集相關的做法。
GMAI模型有望比目前的醫學人工智慧模型解決更多樣化和更具挑戰性的任務,甚至對具體的任務幾乎沒有標籤要求。
在GMAI的三個定義能力中,「能執行動態指定的任務」和「能支援資料模式的靈活組合」可以讓GMAI模型和使用者之間進行靈活的互動;第三種能力要求GMAI模型形式化表示醫學領域的知識,並且能夠進行高階醫學推理。
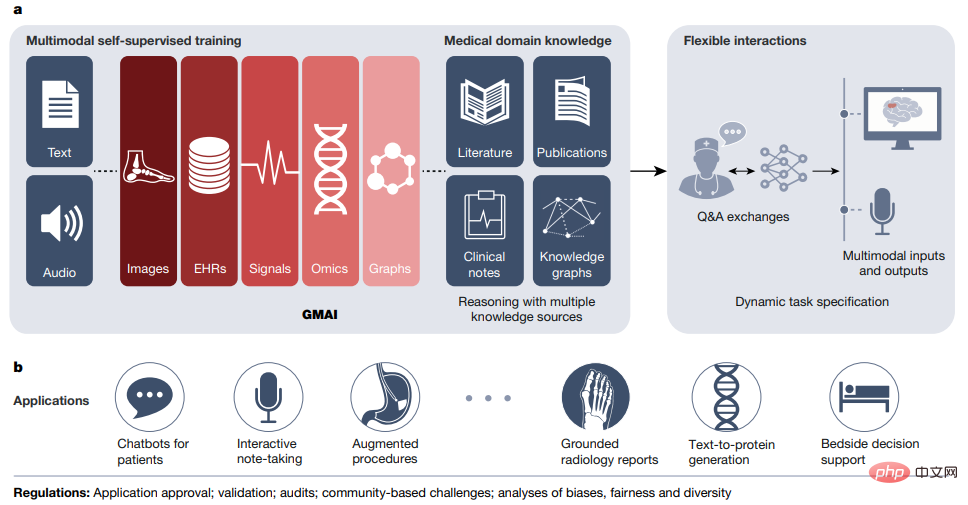
最近發布的一些基礎模型已經表現出了部分GMAI的能力,透過靈活地結合多模態,可以在測試階段動態地指定一個新的任務,但要建立一個具有上述三種能力的GMAI模型仍需要進一步的發展,例如現有的醫學推理模型(如GPT-3或PaLM)並不是多模態的,也無法產生可靠的事實性陳述。
靈活的互動Flexible interactions
#GMAI為使用者提供了透過自訂查詢與模型互動的能力,使不同的受眾更容易理解人工智慧的見解,並為不同的任務和設定提供更大的靈活性。
目前人工智慧模型只能處理非常局限的一組任務,並產生一套僵化的、預先決定好的輸出,比如說模型可以偵測一種特定的疾病,接受某種影像,輸出結果為患這種疾病的可能性。
相較之下,自訂查詢可以輸入使用者拍腦袋想出來問題,例如「解釋一下這個頭部MRI掃描中出現的腫塊,它更可能是腫瘤還是膿腫?」。
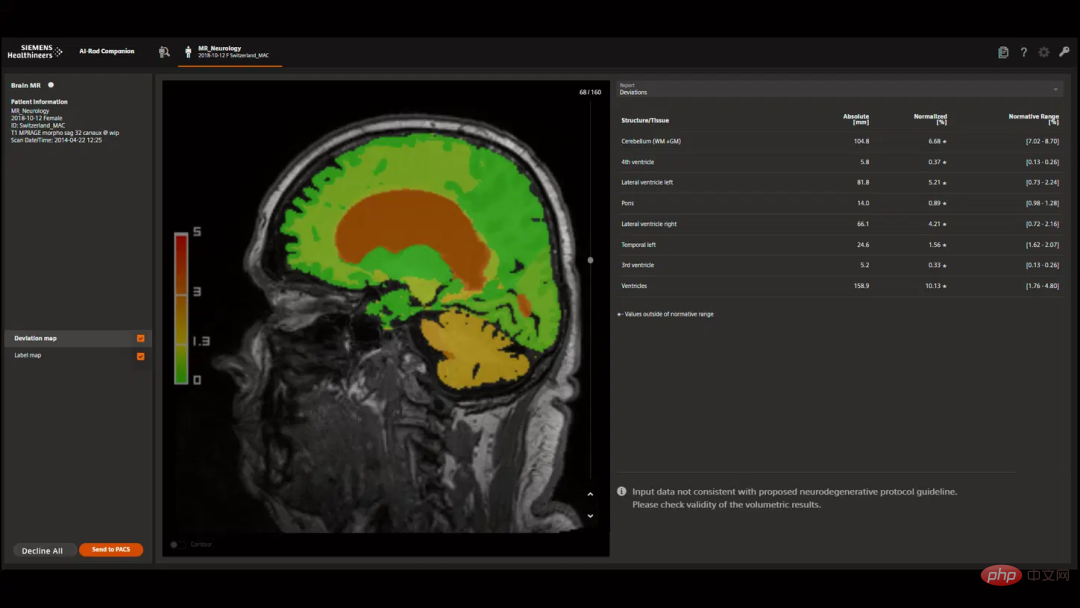
此外,查詢可以讓使用者自訂其輸出的格式,例如「這是一個膠質母細胞瘤患者的後續MRI掃描,用紅色標示可能是腫瘤的部分。」
自訂查詢可以實現兩個關鍵能力,即「動態任務」和「多模態輸入輸出」。
自訂查詢可以教導人工智慧模型在運行中解決新的問題,動態地指定新的任務,而無需對模型重新訓練。
例如,GMAI可以回答高度具體的、以前未見過的問題,例如「根據這個超音波結果,膽囊壁的厚度是多少毫米?」。
GMAI模型可能難以完成涉及未知概念或病理的新任務,而上下文學習(in-context learning)可以讓使用者用很少的幾個例子來教GMAI學習新概念,例如「這裡有10個以前患有一種新出現的疾病的病人的病史,即感染了Langya henipavirus,現在的這個病人也感染Langya henipavirus的可能性有多大?」。
自訂查詢還可以接受包含多模態的複雜醫療信息,例如臨床醫生在詢問診斷時,可能會在查詢中輸入報告、波形訊號、實驗室結果、基因組圖譜和影像研究等;GMAI模型還可以靈活地將不同的模式納入回答中,例如使用者可能要求提供文字答案和附帶的視覺化資訊。
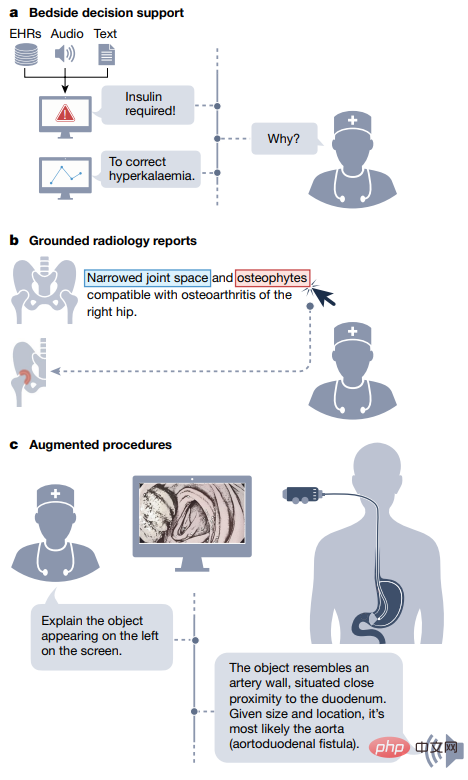
醫學領域知識
##與臨床醫生形成鮮明對比的是,傳統的醫學人工智慧模型在為其特定任務進行訓練之前,通常缺乏對醫學領域背景的了解(如病理生理過程等),只能完全依賴輸入資料的特徵和預測目標之間的統計關聯。
缺乏背景資訊會導致很難訓練一個特定醫療任務的模型,特別是當任務資料稀缺時。
GMAI模型可以透過形式化表示醫學知識來解決這些缺陷,例如知識圖譜等結構可以讓模型對醫學概念和它們之間的關係進行推理;此外,在基於檢索的方法的基礎上,GMAI可以從現有的資料庫中檢索相關的背景,其形式包括文章、圖像或先前的案例。
由此得到的模型可以提出一些警告,例如「這個病人可能會發展成急性呼吸窘迫綜合徵,因為這個病人最近因嚴重的胸腔創傷入院,而且儘管吸入的氧氣量增加了,但病人動脈血中的氧分壓卻持續下降。」
#由於GMAI模型甚至可能被要求提供治療建議,儘管大部分是在觀察數據的基礎上進行訓練,該模型推斷和利用醫學概念和臨床發現之間的因果關係的能力將對臨床適用性起到關鍵作用。
最後,透過獲得豐富的分子和臨床知識,GMAI模型可以透過借鏡相關問題的知識來解決資料有限的任務。
GMAI有潛力透過改善照護和減少臨床醫生的工作量來影響實際的醫療過程。
可控性(Controllability)
GMAI可以讓使用者精細地控制其輸出的格式,使複雜的醫療資訊更容易獲得和理解,所以需要某種GMAI模型根據受眾需求對模型輸出進行重新複述。

由GMAI提供的視覺化結果也需要精心定制,例如透過改變視角或用文字標註重要特徵等,模型還可以潛在地調整其輸出中特定領域的細節水平,或將其翻譯成多種語言,與不同的使用者進行有效溝通。
最後,GMAI的靈活性使其能夠適應特定的地區或醫院,遵循當地的習俗和政策,使用者可能需要關於如何查詢GMAI模型,以及有效利用其輸出的正式指導。
適應性(Adaptability)
現有的醫療人工智慧模型難以應對分佈的轉變,但由於技術、程序、環境或人口的不斷變化,數據的分佈可能會發生巨大變化。
GMAI可以透過上下文學習(in-context learning)跟上轉變的步伐,例如醫院可以教GMAI模型解釋來自全新掃描儀的X射線,只需輸入提示和幾個樣例即可。
也就是說,GMAI可以即時適應新的資料分佈,而傳統的醫療人工智慧模型則需要在全新的資料集上重新訓練;不過目前只有在大型語言模型中觀察到了上下文學習(in-context learning)的能力。
為了確保GMAI能夠適應情境的變化,GMAI模型需要在來自多個互補資料來源以及多樣化的資料上進行訓練。
例如為了適應2019年冠狀疾病的新變種,一個成功的模型可以檢索過去變種的特徵,並在面對查詢中的新上下文時更新這些特徵,一個臨床醫生可能直接輸入「檢查這些胸部X射線,看看是否有奧密克戎」。
模型可以對比德爾塔變體,考慮將支氣管和血管周圍的浸潤作為關鍵訊號。
儘管使用者可以透過提示詞手動調整模型行為,但新技術也可以發揮自動納入人類回饋的作用。
使用者可以對GMAI模型的每個輸出進行評估或評論,就像ChatGPT所使用的強化學習回饋技術,可以藉此改變GMAI模型的行為。
適用性(Applicability)
大規模的人工智慧模型已經成為眾多下游應用的基礎,例如GPT-3在發布後的幾個月內就已經為不同行業的300多個應用程式提供了技術支援。
醫學基礎模型中,CheXzero可用於檢測胸部X光片中的數十種疾病,並且不需要在這些疾病的明確標籤上進行訓練。
向GMAI的範式轉變將推動具有廣泛能力的大規模醫療AI模型的開發和發布,可以作為各種下游臨床應用的基礎:既可以直接使用GMAI的輸出,也可以將GMAI的結果作為中間表示,後續再接入一個小型的領域內模型。
要注意的是,這種靈活的適用性也是一把雙面刃,所有存在於基礎模型中的故障都會在下游應用中繼續傳播。
雖然GMAI模型有許多優勢,但相較於其他領域,醫學領域的安全風險特別高,所以還需要處理確保安全部署的難題。
有效性/確認(Validation)
#GMAI模型由於其前所未有的多功能性,所以想要進行能力驗證也十分困難。
目前的人工智慧模型都是針對特定任務而設計的,所以只需要在那些預先定義的用例中進行驗證即可,例如從大腦核磁共振成像中診斷出特定類型的癌症。
但GMAI模型還可以執行終端使用者首次提出的先前未見過的任務(例如在腦部MRI中診斷其他疾病),如何預測所有的故障模式是一個更難的問題。
開發者和監管機構需要負責解釋GMAI模型是如何被測試的,以及它們被批准用於哪些用例;GMAI介面本身的設計應該在進入未知領域時提出「標籤外使用」的警告,而不能自信地編造不準確的資訊。
更廣泛地說,GMAI獨特的廣泛能力要求監管部門有遠見,要求機構和政府政策適應新的範式,也將重塑保險安排和責任分配。
驗證(Verification)
#與傳統的人工智慧模型相比,GMAI模型可以處理異常複雜的輸入和輸出,使臨床醫生更難確定其正確性。
例如傳統模型在對病人的癌症進行分類時,可能只考慮一項影像研究結果,只需要一名放射科醫生或病理學家就可以驗證該模型的輸出是否正確。
而GMAI模型可能會考慮兩種輸入,並可能輸出初始分類、治療建議和涉及視覺化、統計分析和文獻參考的多模式論證。
在這種情況下,可能需要一個多學科小組(由放射科醫師、病理科醫師、腫瘤科醫師和其他專家組成)來判斷GMAI的輸出是否正確。
因此,無論是在驗證期間還是在模型部署之後,對GMAI輸出的事實核查都是一個嚴峻的挑戰。
創建者可以透過納入可解釋技術使GMAI輸出更容易驗證,例如,讓GMAI的輸出包括可點擊的文獻及具體的證據段落,使臨床醫生能夠更有效地驗證GMAI的預測。
最後,至關重要的是,GMAI模型應準確表達不確定性,並防止用過度自信的陳述來誤導使用者。
社會偏見(Social bias)
#醫學人工智慧模型可能會延續社會的偏見,並對邊緣化人群造成傷害。
在開發GMAI時,這些風險可能會更加明顯,海量資料的需求和複雜性會使模型難以確保沒有不良的偏見。
GMAI模型必須徹底驗證,以確保它們在特定群體(如少數群體)中的表現不會不佳。
即使在部署後,模型也需要進行持續的審計和監管,因為隨著模型遇到新的任務和環境,可能會出現新的問題,迅速識別和修復偏見必須是開發者、供應商和監管者的首要任務。
隱私(Privacy)
#GMAI模型的開發和使用對病患隱私構成了嚴重風險,可能會接觸到豐富的病人特徵,包括臨床測量和訊號、分子特徵和人口統計資訊以及行為和感官追蹤資料。
此外,GMAI模型可能會使用更大的架構,更容易記憶訓練資料並直接重複給用戶,可能會暴露訓練資料集中的敏感病人資料。
可以透過去身分化和限制個別病人的資訊收集量,減少暴露資料造成的損害。
隱私問題也不限於訓練數據,部署的GMAI模型也可能暴露當前病人的數據,例如提示性可以欺騙GPT-3等模型,使其忽略先前的指令;惡意使用者可以強迫模型忽略「不暴露資訊」的指令以提取敏感資料。
以上是Hinton的預言要實現了!美加頂尖大學Nature發文:全科醫學人工智慧GMAI不只取代「放射科醫師」的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















