

圖片+音訊秒變影片!西交大開源SadTalker:頭、唇運動超自然,中英雙語全能,還會唱歌

隨著數位人概念的火爆、生成技術的不斷發展,讓照片裡的人物跟著音訊的輸入動起來也不再是難題。
不過目前「透過人臉影像和一段語音音訊來產生會說話的人物頭像影片」仍存在諸多問題,例如頭部運動不自然、臉部表情扭曲、影片和圖片中的人物面部差異過大等問題。
最近來自西安交通大學等的研究人員提出了SadTalker模型,在三維運動場中進行學習從音頻中生成3DMM的3D運動係數(頭部姿勢、表情),並使用一個全新的3D臉部渲染器來產生頭部運動。

論文連結:https://arxiv.org/pdf/2211.12194.pdf
#專案首頁:https://sadtalker.github.io/
音訊可以是英文、中文、歌曲,影片裡的角色還可以控制眨眼頻率!
為了學習真實的運動係數,研究人員明確地對音訊和不同類型的運動係數之間的聯繫進行單獨建模:透過蒸餾係數和3D渲染的臉部,從音頻中學習準確的面部表情;透過條件VAE設計PoseVAE來合成不同風格的頭部運動。
最後使用產生的三維運動係數被映射到人臉渲染的無監督三維關鍵點空間,並合成最終視訊。
最後在實驗中證明了該方法在運動同步和視訊品質方面實現了最先進的性能。
目前stable-diffusion-webui的外掛也已經發佈!
照片音訊=視訊
數位人創作、視訊會議等多個領域都需要「用語音音訊讓靜態照片動起來」的技術,但目前來說這仍然是一項非常有挑戰性的任務。
先前的工作主要集中在生成「唇部運動」,因為嘴唇的動作與語音之間的關係最強,其他工作也在嘗試產生其他相關運動(如頭部姿勢)的人臉視頻,不過生成視頻的質量仍然非常不自然,並受到偏好姿勢、模糊、身份修改和麵部扭曲的限制。
另一種流行的方法是基於latent的人臉動畫,主要關注在對話式人臉動畫中特定類別的運動,同樣很難合成高質量的視頻,因為雖然三維臉部模型中包含高度解耦的表徵,可以用來單獨學習臉部不同位置的運動軌跡,但仍然會產生不準確的表情和不自然的運動序列。
基於上述觀察結果,研究人員提出了SadTalker(Stylized Audio-Driven Talking-head),透過隱式三維係數modulation的風格化音訊驅動的視訊生成系統。
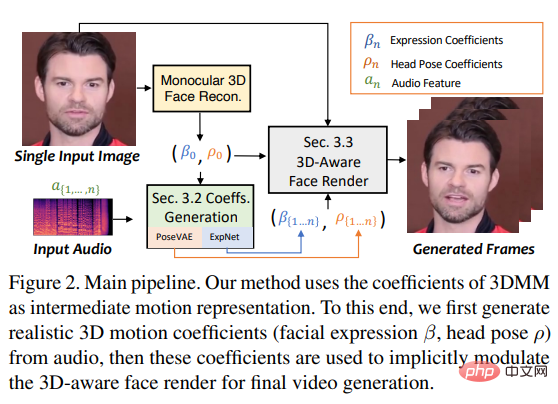
為了實現這一目標,研究者將3DMM的運動係數視為中間表徵,並將任務分為兩個主要部分(表情和姿勢),旨在從音訊中產生更真實的運動係數(如頭部姿勢、嘴唇運動和眼睛眨動),並單獨學習每個運動以減少不確定性。
最後透過一個受face-vid2vid啟發設計的3D感知的臉部渲染來驅動來源影像。
3D臉部
因為現實中的影片都是在三維環境中拍攝的,所以三維資訊對於提高生成影片的真實性至關重要;不過之前的工作很少考慮三維空間,因為只從一張平面影像很難獲得原始的三維稀疏,而且高品質的臉部渲染器也很難設計。
受最近的單影像深度三維重建方法的啟發,研究人員將預測的三維形變模型(3DMMs)的空間作為中間表徵。
在3DMM中,三維臉部形狀S可以被解耦為:
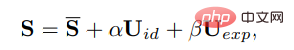
##其中S是三維人臉的平均形狀,Uid和Uexp是LSFM morphable模型的身份和表情的正則,係數α(80維)和β(64維)分別描述人物身份和表情;為了保持姿勢的差異性,係數r和t分別表示頭部旋轉和平移;為了實現身份無關的係數生成,只將運動的參數建模為{β, r, t}。
即,從驅動的音訊中單獨學習頭部姿勢ρ=[r, t]和表情係數β,然後使用這些運動係數被隱式地調製臉部渲染用於最終的視頻合成。
透過音訊產生運動稀疏
#三維運動係數包含頭部姿勢和表情,其中頭部姿勢是全局運動,而表情是相對局部的,所以完全學習所有的係數會給網絡帶來巨大的不確定性,因為頭部姿勢與音頻的關係相對較弱,而嘴唇的運動則是與音頻高度關聯的。
所以SadTalker使用下面PoseVAE和ExpNet分別產生頭部姿勢和表情的運動。
ExpNet
#學習到一個可以「從音訊產生準確的表情係數」的通用模型是非常困難的,原因有二:
1)音頻到表情符號(audio-to-expression)不是對不同人物的一對一的映射任務;
2)表情係數中存在一些與音訊相關的動作,會影響到預測的準確性。
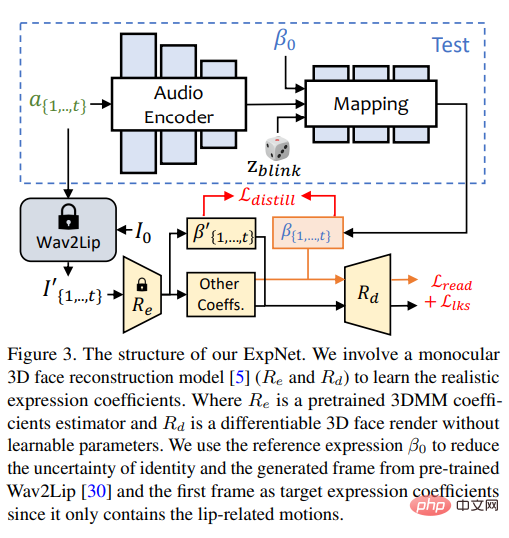
ExpNet的設計目標就是為了減少這些不確定性;至於人物身分問題,研究人員透過第一幀的表情係數將表情運動與特定的人物聯繫起來。
為了減少自然對話中其他臉部成分的運動權重,透過Wav2Lip和深度三維重建的預訓練網絡,只使用嘴唇運動係數(lip motion only)作為係數目標。
至於其他細微的臉部運動(如眼睛眨動)等,可以在渲染影像上的額外landmark損失中引入。
PoseVAE
#研究人員設計了一個基於VAE的模型以學習談話影片中真實的、身分相關(identity-aware)的風格化頭部動作。
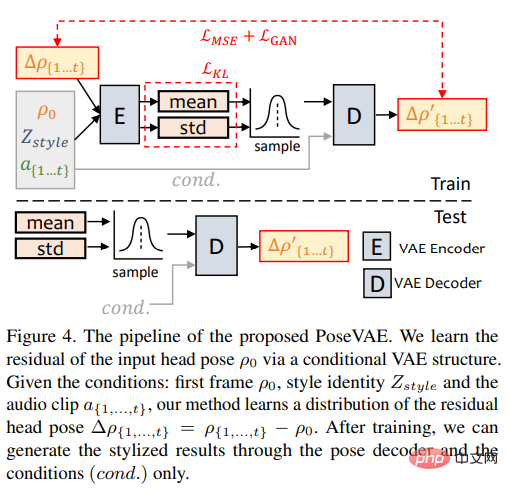
在訓練中,使用基於編碼器-解碼器的結構對固定的n個幀進行姿勢VAE訓練,其中編碼器和解碼器都是兩層MLP,輸入包含一個連續的t幀頭部姿勢,將其嵌入到高斯分佈;在解碼器中,網路從採樣分佈中學習產生t幀姿勢。
要注意的是,PoseVAE並沒有直接產生姿勢,而是學習第一幀的條件姿勢的殘差,這也使得該方法在測試中能在第一幀的條件下產生更長、更穩定、更連續的頭部運動。
根據CVAE,PoseVAE中也增加了相應的音訊特徵和風格標識作為rhythm awareness和身份風格的條件。
模型使用KL散度來測量生成運動的分佈;使用均方損失和對抗性損失來確保生成的品質。
3D-aware臉部渲染
#在產生真實的三維運動係數後,研究人員透過一個精心設計的三維圖像動畫器來渲染最終的影片。
最近提出的圖像動畫方法face-vid2vid可以隱含地從單一圖像中學習3D信息,不過該方法需要一個真實的視頻作為動作驅動信號;而這篇論文中提出的臉部渲染可以透過3DMM係數來驅動。
研究者提出mappingNet來學習顯式3DMM運動係數(頭部姿勢和表情)和隱式無監督3D關鍵點之間的關係。
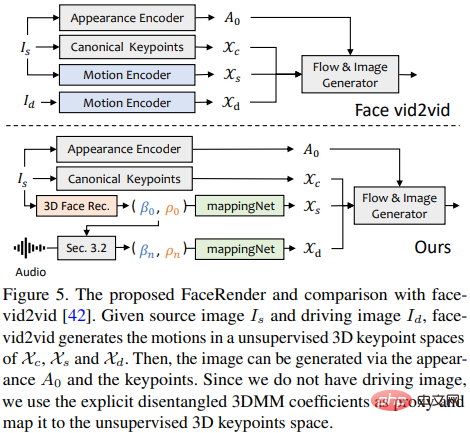
mappingNet透過幾個一維卷積層建立,類似PIRenderer一樣使用時間視窗的時間係數進行平滑處理;不同的是,研究人員發現PIRenderer中的人臉對齊運動係數將極大地影響音訊驅動的視訊產生的運動自然度,所以mappingNet只使用表情和頭部姿勢的係數。
訓練階段包含兩個步驟:首先遵循原始論文,以自我監督的方式訓練face-vid2vid;然後凍結外觀編碼器、canonical關鍵點估計器和圖像生成器的所有參數後,以重建的方式在ground truth視訊的3DMM係數上訓練mappingNet進行微調。
在無監督關鍵點的領域中使用L1損失進行監督訓練,並按照其原始實現方式給出最終生成的視頻。
實驗結果
為了證明方法的優越性,研究人員選取了Frechet Inception Distance(FID)和Cumulative Probability Blur Detection(CPBD)指標來評估影像的質量,其中FID主要評估生成幀的真實性,CPBD評估生成幀的清晰度。
為了評估身分保留程度,使用ArcFace來擷取影像的身份嵌入,然後計算來源影像和產生影格之間身分嵌入的餘弦相似度(CSIM)。
為了評估唇部同步和口型,研究人員評估了來自Wav2Lip的口型的感知差異,包括距離評分(LSE-D)和置信評分(LSE-C) 。
在頭部運動的評估中,使用Hopenet從生成的幀中提取的頭部運動特徵嵌入的標準偏差來計算生成頭部運動的多樣性;計算Beat Align Score來評估音訊和產生頭部移動的一致性。
在對比方法中,選取了幾種最先進的談話頭像產生方法,包括MakeItTalk、Audio2Head和音訊轉表情產生方法(Wav2Lip、PC-AVS),使用公開的checkpoint權重進行評估。
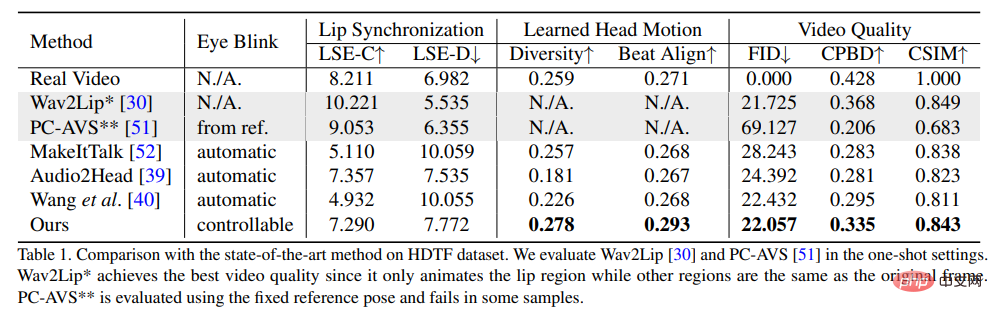
從實驗結果可以看出,文中提出的方法可以展現出更好的整體影片品質和頭部姿勢的多樣性,同時在唇部同步指標方面也顯示出與其他完全說話的頭部生成方法相當的性能。
研究人員認為,這些唇語同步指標對音訊太敏感了,以至於不自然的唇部運動可能會得到更好的分數,不過文中提出的方法取得了與真實影片相似的分數,也顯示了該方法的優勢。

不同方法產生的視覺結果中可以看到,該方法與原始目標影片的視覺品質非常相似,而且與預期的不同頭部姿勢也非常相似。
與其他方法相比,Wav2Lip產生了模糊的半臉;PC-AVS和Audio2Head很難保留來源影像的身份;Audio2Head只能產生正面說話的臉;MakeItTalk和Audio2Head由於二維扭曲而產生了扭曲的人臉視訊。
以上是圖片+音訊秒變影片!西交大開源SadTalker:頭、唇運動超自然,中英雙語全能,還會唱歌的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Win11如何調節音訊平衡? (Win11調整音量的左右聲道)
Feb 11, 2024 pm 05:57 PM
Win11如何調節音訊平衡? (Win11調整音量的左右聲道)
Feb 11, 2024 pm 05:57 PM
在Win11電腦上聽音樂或看電影,如果揚聲器或耳機聽起來不平衡,用戶可以根據自己的需求手動調整平衡等級。那我們要如何調整呢?針對這個問題,小編帶來了詳細的操作教學,希望可以幫助大家。如何在Windows11中平衡左右音訊通道?方法一:使用「設定」套用點擊鍵並點選設定。 Windows按一下系統,然後選擇聲音。選擇更多聲音設定。按一下您的揚聲器/耳機,然後選擇屬性。導航至“等級”選項卡,然後按一下“餘額”。確保“左”和
 Bose Soundbar Ultra首發體驗:開箱即用的家庭劇院?
Feb 06, 2024 pm 05:30 PM
Bose Soundbar Ultra首發體驗:開箱即用的家庭劇院?
Feb 06, 2024 pm 05:30 PM
從我記事開始,家裡就有一對落地式的大尺寸音響,讓我一直認為電視只有配上一套完整的音響系統才能稱得上是電視。但是剛開始工作的時候,我買不起專業的家庭音響。經過查詢、了解產品定位後,我發現回音壁這個品類非常適合我,不論是音質、體積或價格都符合我的需求。因此,我決定選擇回音壁。精挑細選後,我選了2024年初Bose推出了這款全景聲回音壁產品:Bose家庭娛樂揚聲器Ultra。 (圖片來源:雷科技攝製)一般來說,想要體驗到「原汁原味」的杜比全景聲效果,需要我們在家中佈置一套經過測量、校準的環繞聲+天花板
 小紅書發布自動儲存圖片怎麼解決?發布自動保存圖片在哪裡?
Mar 22, 2024 am 08:06 AM
小紅書發布自動儲存圖片怎麼解決?發布自動保存圖片在哪裡?
Mar 22, 2024 am 08:06 AM
隨著社群媒體的不斷發展,小紅書已經成為越來越多年輕人分享生活、發現美好事物的平台。許多用戶在發布圖片時遇到了自動儲存的問題,這讓他們感到十分困擾。那麼,如何解決這個問題呢?一、小紅書發布自動儲存圖片怎麼解決? 1.清除快取首先,我們可以嘗試清除小紅書的快取資料。步驟如下:(1)開啟小紅書,點選右下角的「我的」按鈕;(2)在個人中心頁面,找到「設定」並點選;(3)向下捲動,找到「清除快取」選項,點擊確認。清除快取後,重新進入小紅書,嘗試發布圖片看是否解決了自動儲存的問題。 2.更新小紅書版本確保你的小
 抖音評論裡怎麼發圖片?評論區圖片入口在哪裡?
Mar 21, 2024 pm 09:12 PM
抖音評論裡怎麼發圖片?評論區圖片入口在哪裡?
Mar 21, 2024 pm 09:12 PM
隨著抖音短影片的火爆,用戶們在留言區互動變得更加豐富多彩。有些用戶希望在評論中分享圖片,以便更好地表達自己的觀點或情感。那麼,抖音評論裡怎麼發圖片呢?本文將為你詳細解答這個問題,並為你提供一些相關的技巧和注意事項。一、抖音評論裡怎麼發圖片? 1.開啟抖音:首先,你需要開啟抖音APP,並登入你的帳號。 2.找到評論區:瀏覽或發布短影片時,找到想要評論的地方,點擊「評論」按鈕。 3.輸入評論內容:在留言區輸入你的評論內容。 4.選擇傳送圖片:在輸入評論內容的介面,你會看到一個「圖片」按鈕或「+」號按鈕,點
 7種方法來在Windows 11上重新設定聲音設置
Nov 08, 2023 pm 05:17 PM
7種方法來在Windows 11上重新設定聲音設置
Nov 08, 2023 pm 05:17 PM
雖然Windows能夠管理電腦上的聲音,但您可能仍希望幹預和重置聲音設置,以防您遇到音訊問題或故障。然而,隨著Microsoft在Windows11中所做的美學變化,將這些設定歸零變得更加困難。因此,讓我們深入了解如何在Windows11上找到和管理這些設定或重設它們以防出現任何問題。如何以7種簡單的方式重設Windows11中的聲音設定以下是在Windows11中重設聲音設定的七種方法,具體取決於您面臨的問題。讓我們開始吧。方法1:重設應用程式的聲音和音量設定按鍵盤上的按鈕開啟「設定」應用程式。現在點
 ppt怎麼讓圖片一張一張出來
Mar 25, 2024 pm 04:00 PM
ppt怎麼讓圖片一張一張出來
Mar 25, 2024 pm 04:00 PM
在PowerPoint中,讓圖片逐一顯示是常用的技巧,可以透過設定動畫效果來實現。本指南詳細介紹了實現此技巧的步驟,包括基本設定、圖片插入、新增動畫、調整動畫順序和時間。此外,還提供了進階設定和調整,例如使用觸發器、調整動畫速度和順序,以及預覽動畫效果。透過遵循這些步驟和技巧,使用者可以輕鬆地在PowerPoint中設定圖片逐一出現,從而提升簡報的視覺效果並吸引觀眾的注意力。
 如何使用HTML、CSS和jQuery實現圖片合併展示的進階功能
Oct 27, 2023 pm 04:36 PM
如何使用HTML、CSS和jQuery實現圖片合併展示的進階功能
Oct 27, 2023 pm 04:36 PM
如何使用HTML、CSS和jQuery實現圖片合併展示的高級功能概述:在網頁設計中,圖片展示是一個重要的環節,而圖片合併展示是提高頁面加載速度和提升用戶體驗的常用技巧之一。本文將介紹如何使用HTML、CSS和jQuery來實現圖片合併展示的進階功能,並提供具體的程式碼範例。一、HTML佈局:首先,我們需要在HTML中建立一個容器來展示合併後的圖片。可以使用di
 在 iPhone 上讓圖片更清晰的 6 種方法
Mar 04, 2024 pm 06:25 PM
在 iPhone 上讓圖片更清晰的 6 種方法
Mar 04, 2024 pm 06:25 PM
Apple最近的iPhone可以透過清晰的細節、飽和度和亮度來捕捉回憶。但有時,您可能會遇到一些問題,這些問題可能會導致影像看起來不那麼清晰。儘管iPhone相機上的自動對焦已經取得了長足的進步,可以讓您快速拍照,但相機在某些情況下可能會錯誤地對焦錯誤的拍攝對象,從而使照片在不需要的區域更加模糊。如果iPhone上的照片看起來失焦或整體缺乏清晰度,以下貼文應該可以幫助您使它們更清晰。如何在iPhone上讓圖片更清晰[6種方法]您可以嘗試使用本機的「照片」應用程式來清理照片。如果您需要更多功能和選項
