

Pandas 與 PySpark 強強聯手,功能與速度齊飛!

使用Python做資料處理的資料科學家或資料從業者,對資料科學包pandas並不陌生,也不乏像雲朵君一樣的pandas重度使用者,專案開始寫的第一行程式碼,大多是 import pandas as pd。 pandas做資料處理可以說是yyds!而他的缺點也是非常明顯,pandas 只能單機處理,它不能跟著資料量線性伸縮。例如,如果 pandas 試圖讀取的資料集大於一台機器的可用內存,則會因記憶體不足而失敗。
另外 pandas 在處理大型資料方面非常慢,雖然有像Dask 或 Vaex 等其他函式庫來優化提升資料處理速度,但在大資料處理神之框架Spark面前,也是小菜一碟。
幸運的是,在新的Spark 3.2 版本中,出現了一個新的Pandas API,將pandas大部分功能都整合到PySpark中,使用pandas的接口,就能使用Spark,因為Spark 上的Pandas API 在後台使用Spark,這樣就能達到強強聯手的效果,可以說是非常強大,非常方便。
這一切都始於 2019 年 Spark AI 高峰會。 Koalas 是一個開源項目,可以在 Spark 之上使用 Pandas。一開始,它只涵蓋了 Pandas 的一小部分功能,但後來逐漸壯大起來。現在,在新的 Spark 3.2 版本中,Koalas 已合併到 PySpark。
Spark 現在整合了 Pandas API,因此可以在 Spark 上執行 Pandas。只需要更改一行程式碼:
import pyspark.pandas as ps
由此我們可以獲得諸多的優勢:
- 如果我們熟悉使用Python 和Pandas,但不熟悉Spark,可以省略了需複雜的學習過程而立即使用PySpark。
- 可以為所有內容使用一個程式碼庫:無論是小數據和大數據,還是單機和分散式機器。
- 可以在Spark分散式框架上,更快地運行 Pandas 程式碼。
最後一點尤其值得注意。
一方面,可以將分散式計算套用到在 Pandas 中的程式碼。且借助 Spark 引擎,程式碼即使在單一機器上也會更快!下圖展示了在一台機器(具有 96 個 vCPU 和 384 GiBs 記憶體)上運行 Spark 和單獨呼叫 pandas 分析 130GB 的 CSV 資料集的效能比較。
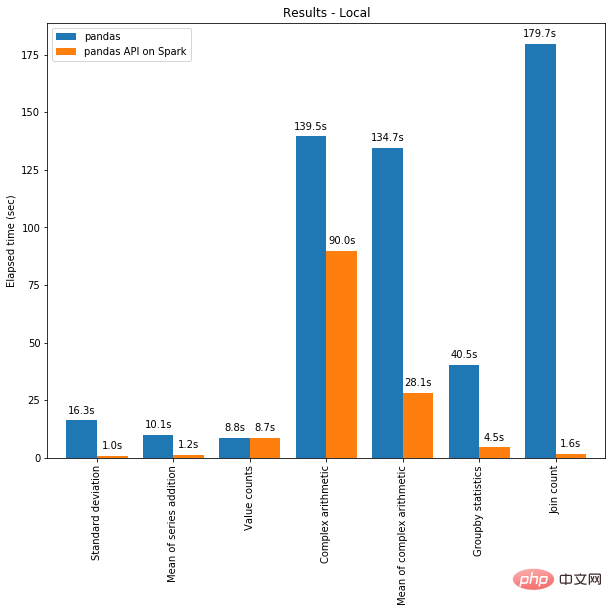
多執行緒和 Spark SQL Catalyst Optimizer 都有助於最佳化效能。例如,Join count 操作在整個階段程式碼產生時快 4 倍:沒有程式碼產生時為 5.9 秒,程式碼產生時為 1.6 秒。
Spark 在鍊式運算(chaining operations)中具有特別顯著的優勢。 Catalyst 查詢最佳化器可以識別過濾器以明智地過濾資料並可以應用基於磁碟的連接(disk-based joins),而 Pandas 傾向於每一步將所有資料載入到記憶體中。
現在是不是迫不及待的想嘗試如何在 Spark 上使用 Pandas API 編寫一些程式碼?我們現在就開始吧!
在 Pandas / Pandas-on-Spark / Spark 之間切換
需要知道的第一件事是我們到底在使用什麼。使用 Pandas 時,使用類別pandas.core.frame.DataFrame。在 Spark 中使用 pandas API 時,使用pyspark.pandas.frame.DataFrame。雖然兩者相似,但不相同。主要區別在於前者在單機中,而後者是分散式的。
可以使用Pandas-on-Spark 建立一個Dataframe 並將其轉換為Pandas,反之亦然:
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
注意,如果使用多台機器,則在將Pandas-on- Spark Dataframe 轉換為Pandas Dataframe 時,資料會從多台機器傳送到一台機器,反之亦然(可參閱PySpark 指南[1])。
也可以將 Pandas-on-Spark Dataframe 轉換為 Spark DataFrame,反之亦然:
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
資料類型如何改變?
在使用 Pandas-on-Spark 和 Pandas 時,資料型別基本上相同。將Pandas-on-Spark DataFrame 轉換為Spark DataFrame 時,資料類型會自動轉換為適當的類型(請參閱PySpark 指南[2])
#下面的範例顯示了在轉換時如何將數據類型從PySpark DataFrame 轉換為pandas-on-Spark DataFrame。
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
Pandas-on-Spark vs Spark 函數
在 Spark 中的 DataFrame 及其在 Pandas-on-Spark 中最常用的函數。請注意,Pandas-on-Spark 和 Pandas 在文法上的唯一區別是 import pyspark.pandas as ps 一行。
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
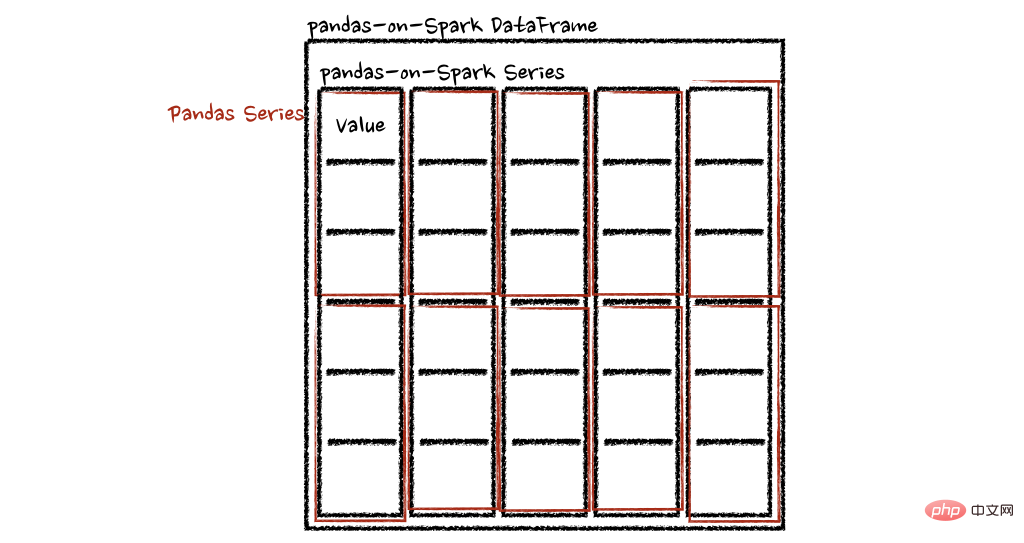
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
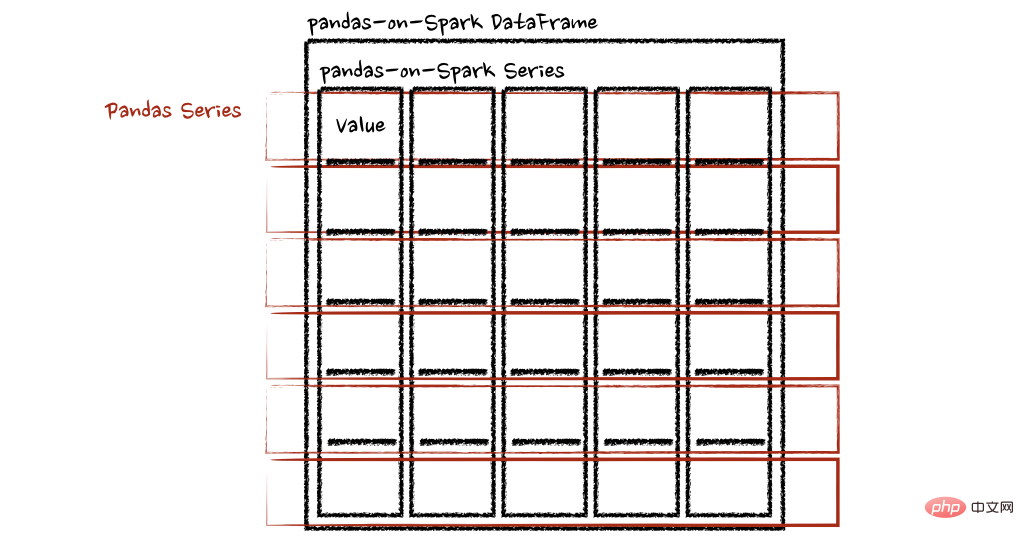
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
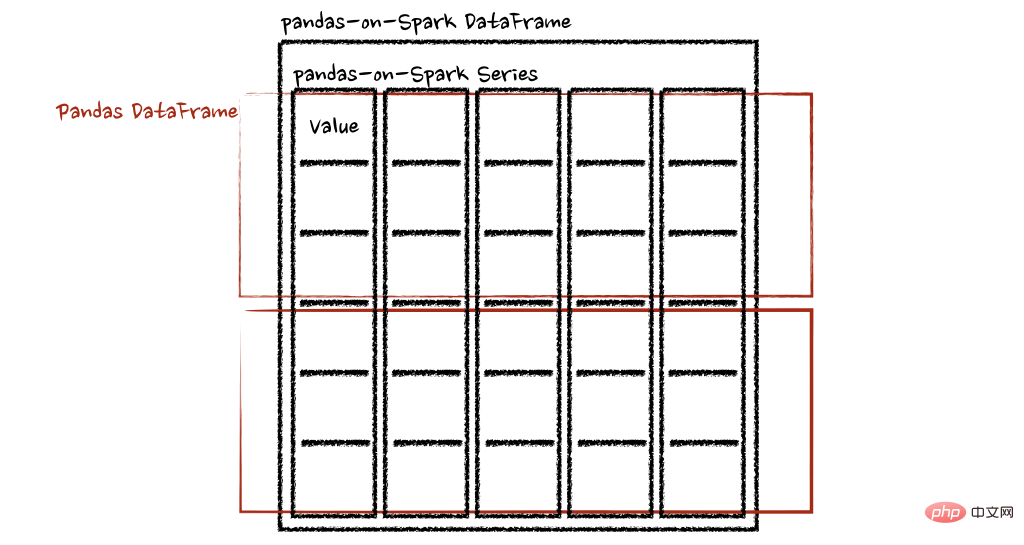
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
以上是Pandas 與 PySpark 強強聯手,功能與速度齊飛!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 解決常見的pandas安裝問題:安裝錯誤的解讀與解決方法
Feb 19, 2024 am 09:19 AM
解決常見的pandas安裝問題:安裝錯誤的解讀與解決方法
Feb 19, 2024 am 09:19 AM
pandas安裝教學:解析常見安裝錯誤及其解決方法,需要具體程式碼範例引言:Pandas是一個強大的資料分析工具,廣泛應用於資料清洗、資料處理和資料視覺化等方面,因此在資料科學領域備受推崇。然而,由於環境配置和依賴問題,安裝pandas可能會遇到一些困難和錯誤。本文將為大家提供一份pandas安裝教程,並解析一些常見的安裝錯誤及其解決方法。一、安裝pandas
 如何使用pandas正確讀取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正確讀取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正確讀取txt文件,需要具體程式碼範例Pandas是一個廣泛使用的Python資料分析函式庫,它可以用來處理各種各樣的資料類型,包括CSV檔案、Excel檔案、SQL資料庫等。同時,它也可以用於讀取文字文件,例如txt文件。但是,在讀取txt檔案時,我們有時會遇到一些問題,例如編碼問題、分隔符號問題等。本文將介紹如何使用pandas正確讀取txt
 使用pandas讀取CSV檔案並進行資料分析
Jan 09, 2024 am 09:26 AM
使用pandas讀取CSV檔案並進行資料分析
Jan 09, 2024 am 09:26 AM
Pandas是一個強大的資料分析工具,可以輕鬆讀取和處理各種類型的資料檔案。其中,CSV檔案是最常見且常用的資料檔案格式之一。本文將介紹如何使用Pandas讀取CSV檔案並進行資料分析,同時提供具體的程式碼範例。一、導入必要的函式庫首先,我們需要導入Pandas函式庫和其他可能需要的相關函式庫,如下所示:importpandasaspd二、讀取CSV檔使用Pan
 Pandas輕鬆讀取SQL資料庫中的數據
Jan 09, 2024 pm 10:45 PM
Pandas輕鬆讀取SQL資料庫中的數據
Jan 09, 2024 pm 10:45 PM
資料處理利器:Pandas讀取SQL資料庫中的數據,需要具體程式碼範例隨著資料量的不斷增長和複雜性的提高,資料處理成為了現代社會中一個重要的環節。在資料處理過程中,Pandas成為了許多資料分析師和科學家的首選工具之一。本文將介紹如何使用Pandas函式庫來讀取SQL資料庫中的數據,並提供一些具體的程式碼範例。 Pandas是基於Python的一個強大的數據處理和分
 python如何安裝pandas
Dec 04, 2023 pm 02:48 PM
python如何安裝pandas
Dec 04, 2023 pm 02:48 PM
python安裝pandas的步驟:1、開啟終端機或指令提示字元;2、輸入「pip install pandas」指令安裝pandas函式庫;3、等待安裝完成,可以在Python腳本中匯入並使用pandas函式庫了;4、使用的是特定的虛擬環境,確保在安裝pandas之前啟動相應的虛擬環境;5、使用的是整合開發環境,可以添加“import pandas as pd”程式碼來導入pandas庫。
 python pandas安裝方法
Nov 22, 2023 pm 02:33 PM
python pandas安裝方法
Nov 22, 2023 pm 02:33 PM
python可以透過使用pip、使用conda、從原始碼、使用IDE整合的套件管理工具來安裝pandas。詳細介紹:1、使用pip,在終端機或命令提示字元中執行pip install pandas命令即可安裝pandas;2、使用conda,在終端機或命令提示字元中執行conda install pandas命令即可安裝pandas;3、從原始碼安裝等等。
 使用pandas讀取txt檔案的實用技巧
Jan 19, 2024 am 09:49 AM
使用pandas讀取txt檔案的實用技巧
Jan 19, 2024 am 09:49 AM
使用pandas讀取txt檔案的實用技巧,需要具體程式碼範例在資料分析和資料處理中,txt檔案是一種常見的資料格式。使用pandas讀取txt檔案可以快速、方便地進行資料處理。本文將介紹幾種實用的技巧,以幫助你更好的使用pandas讀取txt文件,並配以具體的程式碼範例。讀取帶有分隔符號的txt檔案使用pandas讀取帶有分隔符號的txt檔案時,可以使用read_c
 Pandas讀取網頁資料的實用方法
Jan 04, 2024 am 11:35 AM
Pandas讀取網頁資料的實用方法
Jan 04, 2024 am 11:35 AM
Pandas讀取網頁資料的實用方法,需要具體程式碼範例在資料分析和處理過程中,我們經常需要從網頁中取得資料。而Pandas作為一種強大的資料處理工具,提供了方便的方法來讀取和處理網頁資料。本文將介紹幾種常用的Pandas讀取網頁資料的實用方法,並附上特定的程式碼範例。方法一:使用read_html()函數Pandas的read_html()函數可以直接從網頁讀
