
ChatGPT發布後不久,微軟成功上車發布「新必應」,不僅股價大漲,甚至還大有取代谷歌,開啟搜尋引擎新時代的架勢。
不過新必應真是大型語言模型的正確玩法嗎?產生的答案真的對使用者有用嗎?句子裡標的引文可信度有多少?
最近,史丹佛的研究人員從不同的來源收集了大量的用戶查詢,對當下四個大火的生成性搜尋引擎,新必應(Bing Chat),NeevaAI, perplexity.ai和YouChat進行了人工評估。

論文連結:https://arxiv.org/pdf/2304.09848.pdf
實驗結果發現,來自現有生成搜尋引擎的回應流暢且資訊量大,但經常包含沒有證據的陳述和不準確的引用。
平均來說,只有51.5%的引用可以完全支撐生成的句子,只有74.5% 的引用可以作為相關句子的證據支持。
研究人員認為,對於那些可能成為資訊搜尋使用者主要工具的系統來說,這個結果實在是過低了,特別是考慮到有些句子只是貌似可信的話,生成式搜尋引擎仍需要進一步優化。

個人主頁:https://cs.stanford.edu/~nfliu/
第一作者Nelson Liu是史丹佛大學自然語言處理組的四年級博士生,導師為Percy Liang,大學畢業於華盛頓大學,主要研究方向為構建實用的NLP系統,尤其是用於資訊查找的應用程式。
2023年3月,微軟報告說「大約三分之一的每日預覽用戶每天都在使用[Bing]聊天」,並且Bing聊天在其公開預覽的第一個月提供了4500萬次聊天,也就是說,把大型語言模型融合進搜索引擎是非常有市場的,極有可能改變互聯網的搜索入口。

但目前來看,現有的基於大型語言模型技術的生成式搜尋引擎仍然存在準確率不高的問題,但具體的準確率仍然沒有全面評估,進而無法了解到新型搜尋引擎的限制。
可驗證性(verifiability)是提升搜尋引擎可信度的關鍵,即為生成答案中的每一句話都提供引文的外部連結來作為證據支撐,可以使用戶更容易驗證答案的準確程度。
研究人員透過收集不同類型、來源的問題,在四個商業生成式搜尋引擎(Bing Chat, NeevaAI, perplexity.ai, YouChat)上進行手動評估。
#評估指標主要包括流暢性,即生成的文本是否連貫;有用性,即搜尋引擎的回應對於用戶來說是否有幫助,以及答案中的信息是否能夠解決問題;引用召回,即生成的關於外部網站的句子中包含引用支援的比例;引用精確度,即產生的引用支持其相關句子的比例。
流暢性(fluency)
#同時展示用戶查詢、產生的回復以及聲明「該回復是流暢且語義連貫的」,標註人員以五分制Likert量表對數據進行評分。
有用性(perceived utility)
與流暢度類似,標註人員需要評定他們對「該回覆是對用戶查詢來說是有用且有資訊量的」這一說法的同意程度。
引用召回(citation recall)
#引用召回率是指由其相關引文完全支持的、值得驗證的句子的比例,所以該指標的計算需要確定回復中值得驗證的句子,以及評估每個值得驗證的句子能夠被相關引文支持。
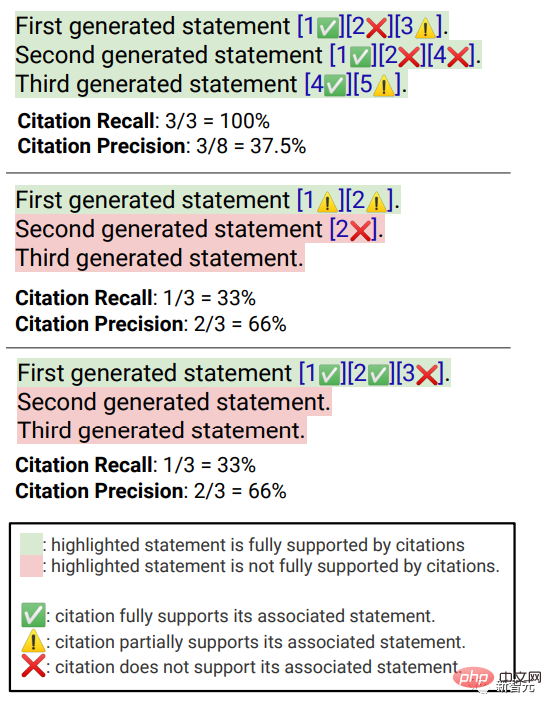
在「辨識值得驗證的句子」過程中,研究者認為關於外在世界的每一個產生的句子都是值得驗證的,即使是那些可能看起來很明顯、微不足道的常識,因為對於某些讀者來說似乎是明顯的「常識」,但其實可能並不正確。
搜尋引擎系統的目標應該是為所有生成的關於外部世界的句子提供參考來源,使讀者能夠輕鬆地驗證生成的回復中的任何敘述,不能為了簡單而犧牲可驗證性。
所以實際上標註人員對所有生成的句子都進行驗證,除了那些以系統為第一人稱的回复,如“作為一個語言模型,我沒有能力做... ”,或是對用戶的提問,如“你想了解更多嗎?”等。
評估「一個值得驗證的陳述是否得到其相關引文的充分支持」可以基於歸因已識別來源(AIS, attributable to identified sources)評估框架,標註人員進行二元標註,即如果一個普通的聽眾認可“基於引用的網頁,可以得出...”,那麼引文即可完全支持該回复。
引用精確率
#為了衡量引用的精確率,標註人員需要判斷每個引用是否對其相關的句子提供了全部、部分或無關支持。
完全支持(full support):句子中的所有資訊都得到了引文的支持。
部分支持(Partial support):句子中的一些資訊得到了引文的支持,但其他部分可能存在缺失或矛盾。
無關支援(No support):如引用的網頁完全不相關或相互矛盾。
對於有多個相關引文的句子,還會額外要求標註人員使用AIS評估框架判斷所有相關引文網頁作為一個整體是否為該句子提供了充分的支持(二元判斷)。
在流暢性和有用性評估中,可以看到各個搜尋引擎都能夠產生非常流暢且有用的回應。
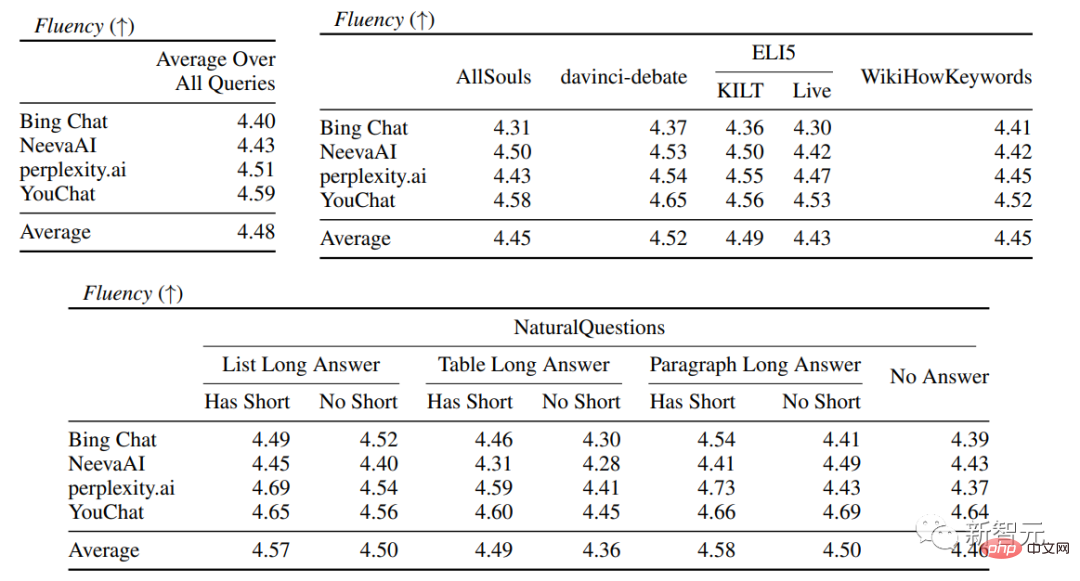
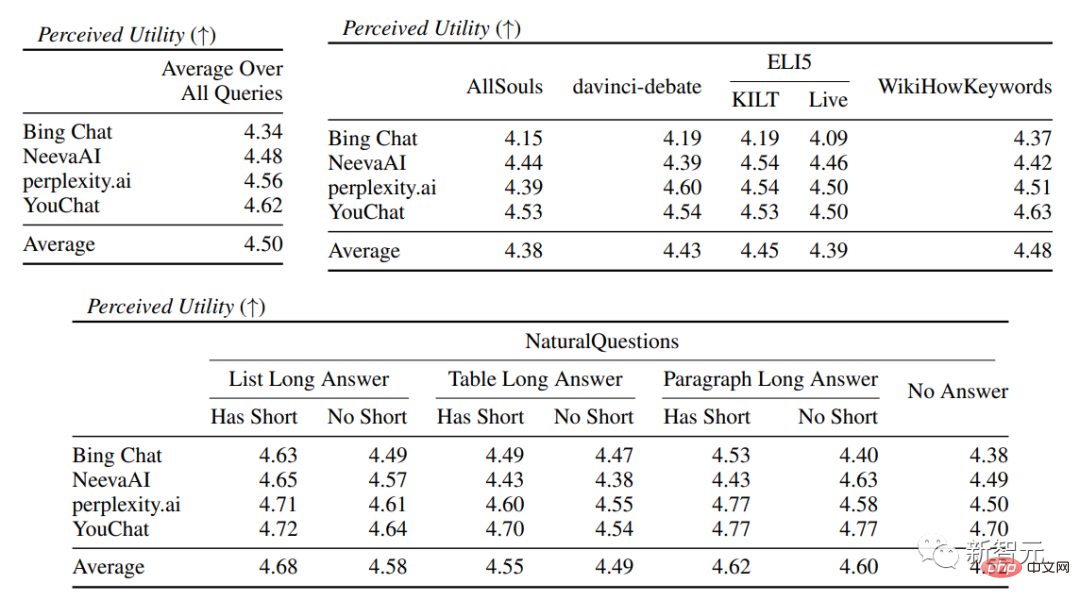
在具體的搜尋引擎評估中,可以看到看到Bing Chat的流暢性/有用性評分最低(4.40/4.34),其次是NeevaAI(4.43/4.48),perplexity.ai(4.51/4.56),以及YouChat(4.59/4.62)。
在不同類別的使用者查詢中,可以看到較短的提取性問題通常比長問題要更流暢,通常只回答事實性知識即可;一些有難度的問題通常需要對不同的表格或網頁進行匯總,合成過程會降低整體的流暢性。
在引文評估中,可以看到現有的生成式搜尋引擎往往無法全面或正確地引用網頁,平均只有51.5%的生成句子得到了引文的完全支持(召回率),只有74.5%的引文完全支持其相關句子(精確度)。
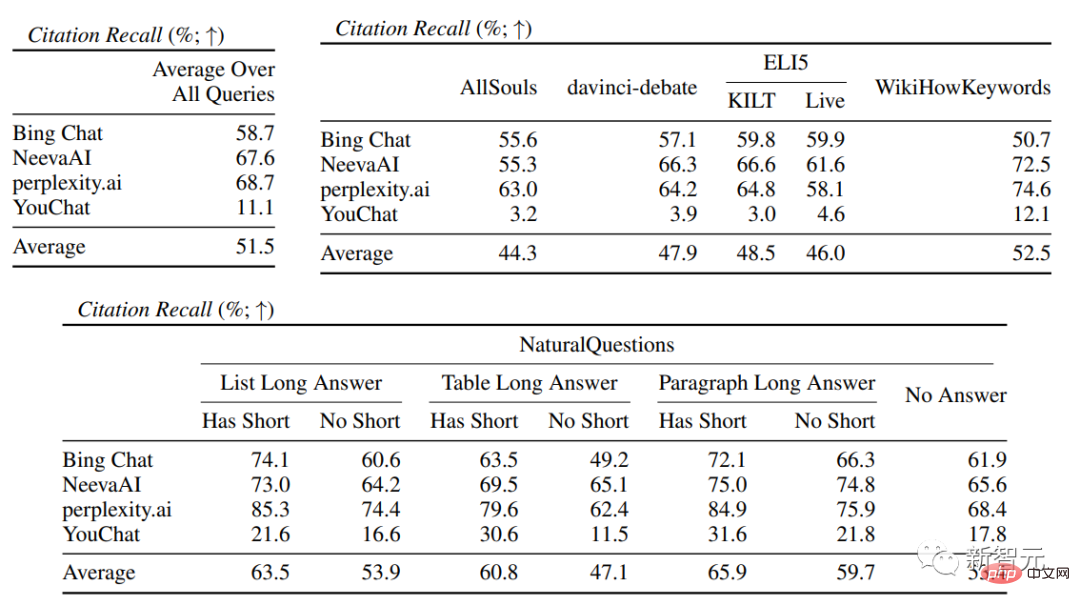
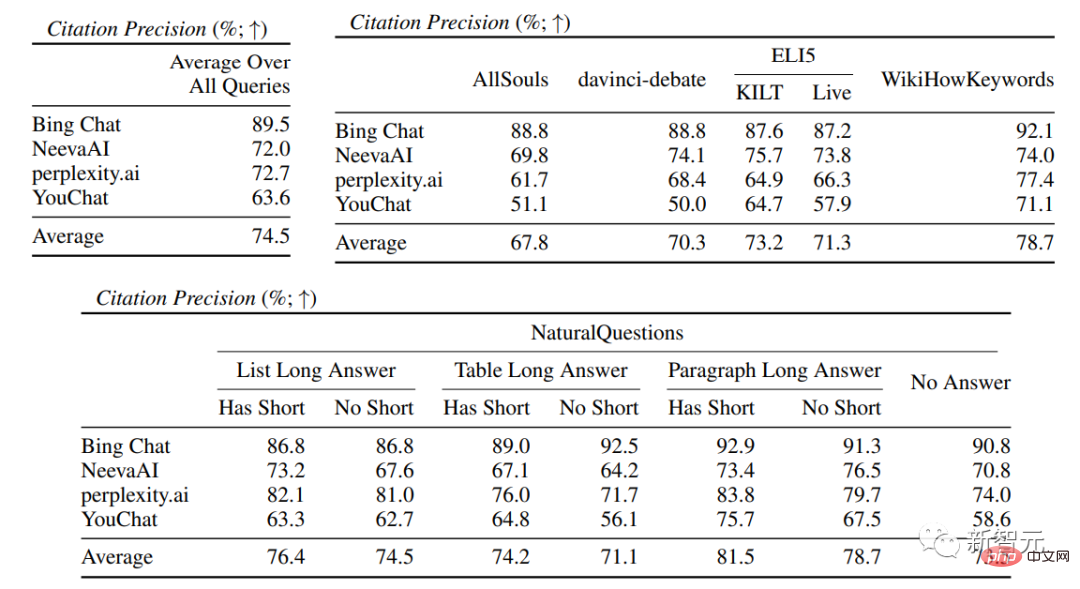
這個數值來說對於已經擁有數百萬用戶的搜尋引擎系統來說是不可接受的,特別是在產生回覆往往資訊量比較大的情況下。
並且不同的生成式搜尋引擎之間的引文召回率和精確度有很大差異,其中perplexity.ai實現了最高的召回率( 68.7),而NeevaAI(67.6)、Bing Chat(58.7)和YouChat(11.1)較低。
另一方面,Bing Chat實現了最高的精確度(89.5),其次是perplexity.ai(72.7)、NeevaAI(72.0)和YouChat( 63.6)
在不同的使用者查詢中,有長答案的NaturalQuestions查詢和非NaturalQuestions查詢之間的引用召回率差距接近11%(分別為58.5和47.8);
同樣,有短答案的NaturalQuestions查詢和無短答案的NaturalQuestions查詢之間的引用召回率差距接近10%(有短答案的查詢為63.4,只有長答案的查詢為53.6,而無長或短答案的查詢為53.4)。
在沒有網頁支援的問題中,引用率就會較低,例如對開放式的AllSouls論文問題進行評估時,生成式搜尋引擎在引文召回率方面只有44.3
#以上是四款「ChatGPT搜尋」全面比較!斯坦福華人博士純手工標註:新必應流暢度最低,近一半句子都沒引用的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















