

如果你需要存取多個服務來完成一個請求的處理,例如實現文件上傳功能時,首先訪問Redis 緩存,驗證用戶是否登錄,再接收HTTP 訊息中的body並保存在磁碟上,最後把檔案路徑等資訊寫入MySQL 資料庫中,你會怎麼做?
首先可以使用阻塞 API 編寫同步程式碼,直接一步步串列即可,但很明顯這時一個執行緒只能同時處理一個請求。而我們知道線程數是有限制的,有限的線程數導致無法實現上萬級別的並發連接,過多的線程切換也搶走了 CPU 的時間,從而降低了每秒能夠處理的請求數量。
於是為了達到高並發,你可能會選擇一個非同步框架,用非阻塞 API 把業務邏輯打亂到多個回呼函數中,透過多路復用實現高並發。但此時就要求業務程式碼過度關注並發細節,需要維護許多中間狀態,一旦程式碼邏輯出現錯誤就會陷入回調地獄。
因此這麼做不但 Bug 率會很高,專案的開發速度也上不去,產品及時上線有風險。如果想兼顧開發效率,又能確保高並發,協程就是最好的選擇。它可以在保持非同步化運作機制的同時,還能用同步的方式寫程式碼,這既實現了高並發,又縮短了開發週期,是高效能服務未來的發展方向。
這裡我們必須要指出,在並發量方面,使用「協程」的方式並不優於「非阻塞回呼」的方式,而我們之所以選擇協程是因為它的程式模型更簡單,類似同步,也就是可以讓我們用同步的方式來寫非同步的程式碼。 「非阻塞 回調」這種方式非常考驗程式設計技巧,一旦出現錯誤,不好定位問題,容易陷入回調地獄、棧撕裂等困境。
所以你會發現,解決高並發問題的技術一直在變化,從多進程、多線程,到異步化、協程,面對不同的場景,它們都在用各自不同的方式解決問題。下面我們就來看看,高並發的解決方案是怎麼演進的,協程到底解決了什麼問題,它又該如何應用。
我們知道一台主機的資源有限,一顆 CPU、一塊磁碟、一張網卡,如何同時服務上百個請求呢?多進程模式是最初的解決方案。核心把CPU 的執行時間切分成許多時間片(timeslice),例如1 秒鐘可以切割成100 個10 毫秒的時間片,每個時間片再分發給不同的進程,通常,每個進程需要多個時間片才能完成一個請求。
這樣雖然微觀上,比如說就這10 毫秒時間CPU 只能執行一個進程,但宏觀上1 秒鐘執行了100 個時間片,於是每個時間片所屬進程中的請求也得到了執行,這就實現了請求的並發執行。
不過,每個進程的記憶體空間都是獨立的,因此使用多進程實現並發就有兩個缺點:一是內核的管理成本高,二是無法簡單地透過記憶體同步數據,很不方便。於是,多執行緒模式就出現了,多執行緒模式透過共享記憶體位址空間,解決了這兩個問題。
然而,共享位址空間雖然可以方便地共享對象,但這也導致一個問題,那就是任何一個執行緒出錯時,進程中的所有執行緒會跟著一起崩潰。這也是如 Nginx 等強調穩定性的服務堅持使用多進程模式的原因。
但事實上無論基於多進程或多線程,都難以實現高並發,主要有以下兩個原因。
下圖以磁碟 IO 為例,描述了多執行緒中使用阻塞方法讀取磁碟,2 個執行緒間的切換方式。
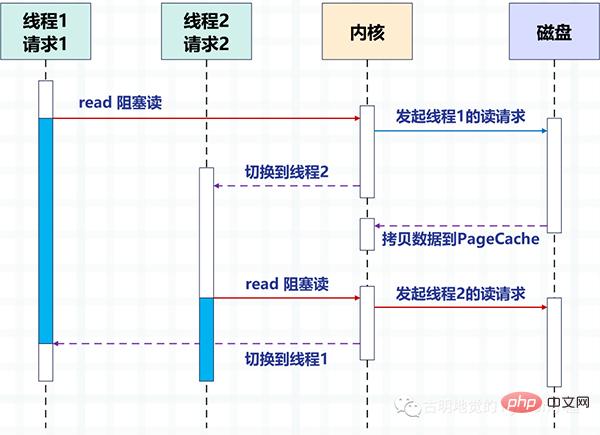
透過多執行緒的方式,一個執行緒處理一個請求,從而實現並發。但很明顯,作業系統能創建線程數是有限的,因為線程越多資源佔用就越多,而且線程之間的切換成本也比較大,因為涉及到內核狀態和用戶態之間的切換。
那麼問題來了,要怎麼實現高並發呢?答案是「把上圖由核心實現的請求切換工作,交由用戶態的程式碼來完成就可以了」。非同步化程式設計透過應用層程式碼實現了請求切換,降低了切換成本和記憶體佔用空間。
非同步化依賴 IO 多路復用機制,例如 Linux 的 epoll,同時,必須把阻塞方法改為非阻塞方法,才能避免核心切換帶來的巨大消耗。 Nginx、Redis 等高效能服務都依賴非同步化實現了百萬量級的並發。
下圖描述了非同步 IO 的非阻塞讀和非同步框架結合後,是如何切換請求的。
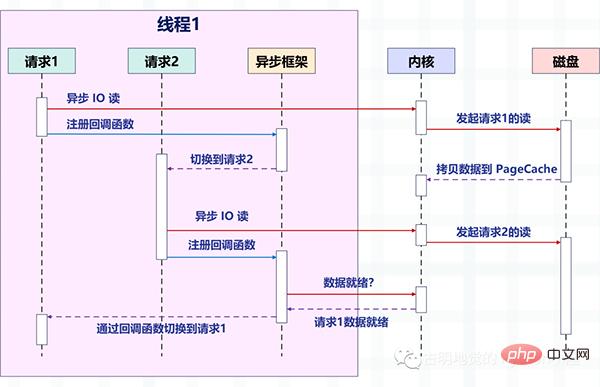
注意圖中的變化,之前是一個執行緒處理一個請求,現在是一個執行緒處理多個請求,這就是我們之前說的「非阻塞回呼」的方式。它依賴作業系統提供的 IO 多路復用,例如 Linux 的 epoll,BSD 的 kqueue。
此時的讀寫操作都相當於一個事件,並為每一個事件都註冊對應的回呼函數,然後執行緒不會阻塞(因為讀寫操作此時是非阻塞的),而是可以做其它事情,然後由epoll 來對這些事件進行統一管理。
一旦事件發生(滿足可讀、可寫入時),那麼 epoll 就會告知線程,然後執行緒執行為該事件註冊的回呼函數。
為了更好地理解,我們再以 Redis 為例,介紹一下非阻塞 IO 和 IO 多路復用。
127.0.0.1:6379> get name "satori"
首先我們可以使用 get 指令,取得一個 key 對應的 value,那麼問題來了,以上對於 Redis 服務端而言,都發生了哪些事情呢?
服務端必須先監聽客戶端請求(bind/listen),然後當客戶端到來時與其建立連線(accept),從socket 讀取客戶端的請求(recv),對請求進行解析(parse),這裡解析出的請求類型是get、key 是"name",再根據key 取得對應的value,最後返回給客戶端,也就是向socket 寫入資料(send)。
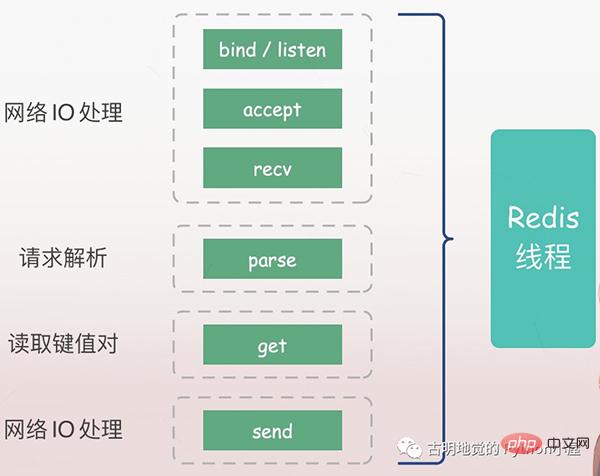
以上所有操作都是由 Redis 主執行緒依序執行的,但裡面會有潛在的阻塞點,分別是 accept 和 recv。
如果是阻塞IO,當Redis 監聽到一個客戶端有連接請求、但卻一直未能成功建立連接,那麼主線程會一直阻塞在accept 函數這裡,導致其它客戶端無法和Redis 建立連接。類似的,當 Redis 透過 recv 從客戶端讀取資料時,如果資料一直沒有到達,那麼 Redis 主執行緒也會一直阻塞在 recv 這一步驟,因此這就導致了 Redis 的效率會變得低。
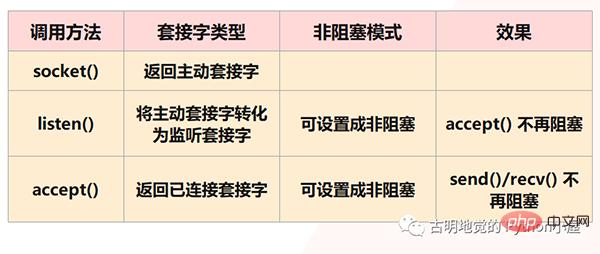
但很明顯,Redis 不會允許這種情況發生,因為以上都是阻塞IO 會面臨的情況,而Redis 採用的是非阻塞IO,也就是將socket 設定成了非阻塞模式。首先在socket 模型中,呼叫socket() 方法會傳回主動套接字;呼叫bind() 方法綁定IP 和端口,再呼叫listen() 方法將主動套接字轉換為監聽套接字;最後監聽套接字;最後監聽套接字呼叫accept() 方法等待客戶端連線的到來,當和客戶端建立連線時再傳回已連線套接字,而後續就透過已連線套接字來和客戶端進行資料的接收與傳送。
但是注意:我們說在listen() 這一步,會將主動套接字轉換為監聽套接字,而此時的監聽套接字的類型是阻塞的,阻塞類型的監聽套接字在呼叫accept() 方法時,如果沒有客戶端來連線的話,就會一直處於阻塞狀態,那麼此時主執行緒就沒辦法幹其它事情了。所以當listen() 的時候可以設定為非阻塞,而非阻塞的監聽套接字在呼叫accept() 時,如果沒有客戶端連線請求到達時,那麼主執行緒就不會傻傻地等待了,而是會直接返回,然後去做其它的事情。
類似的,我們在創建已連接套接字的時候也可以將其類型設為非阻塞,因為阻塞類型的已連接套接字在調用send() / recv() 的時候也會處於阻塞狀態,例如當客戶端一直不發資料的時候,已連接套接字就會一直阻塞在rev() 這一步驟。如果是非阻塞類型的已連接套接字,那麼當呼叫 recv() 但卻收不到資料時,也不用處於阻塞狀態,同樣可以直接返回去做其它事情。
但是有兩點需要注意:
1)雖然accept() 不阻塞了,在沒有客戶端連接時Redis 主執行緒可以去做其它事情,但如果後續有客戶端來連接,Redis 要如何得知?因此必須要有一個機制,能夠繼續在監聽套接字上等待後續連線請求,並在請求到來時通知 Redis。
2)send() / recv() 不阻塞了,相當於IO 的讀寫流程不再是阻塞的,讀寫方法都會瞬間完成並且返回,也就是它會採用能讀多少就讀多少、能寫多少就寫多少的策略來執行IO 操作,這顯然更符合我們對效能的追求。但這樣同樣會面臨一個問題,就是當我們執行讀取操作時,有可能只讀取了一部分數據,剩餘的數據客戶端還沒發過來,那麼這些數據何時可讀呢?同理寫數據也是這種情況,當緩衝區滿了,而我們的數據還沒寫完,那麼剩下的數據又何時可寫呢?因此同樣要有一種機制,能夠在 Redis 主執行緒做別的事情的時候繼續監聽已連接套接字,並且有資料可讀寫的時候通知 Redis。
這樣才能保證Redis 執行緒既不會像基本IO 模型中一直在阻塞點等待,也不會無法處理實際到達的客戶端連接請求和可讀寫的數據,而上面所提到的機製便是IO 多路復用。
I/O 多路復用機制是指一個執行緒處理多個 IO 流,也就是我們常聽到的 select/poll/epoll。關於這三者的差異我們就不說了,它們所做的事情都一樣,無非是性能和實現原理上有差異。 select 是所有系統都支持,而 epoll 只有 Linux 支援。
簡單來說,在 Redis 只運行單一執行緒的情況下,該機制允許核心中同時存在多個監聽套接字和已連接套接字。核心會一直監聽這些套接字上的連線請求或資料請求,一旦有請求到達就會交給 Redis 執行緒處理,這樣就實現了一個 Redis 執行緒處理多個 IO 流的效果。
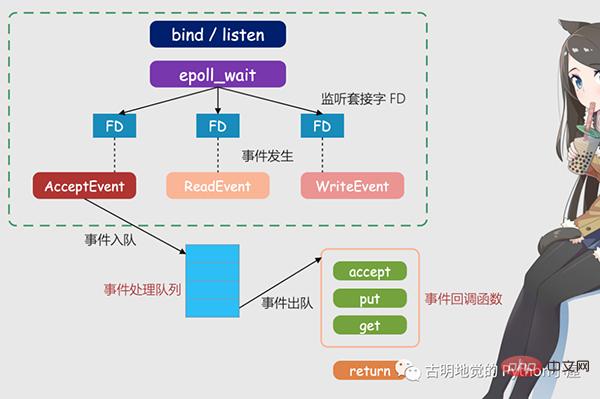
上圖就是基於多工的Redis IO 模型,圖中的FD 就是套接字,可以是監聽套接字,也可以是已連接套接字,Redis 會透過epoll 機制來讓核心幫忙監聽這些套接字。而此時 Redis 線程或說主線程,不會阻塞在某一個特定的套接字上,也就是說不會阻塞在某一個特定的客戶端請求處理上。因此 Redis 可以同時和多個客戶端連接並處理請求,從而提升並發性。
但為了在請求到達時能夠通知 Redis 線程,epoll 提供了基於事件的回調機制,即針對不同事件的發生,調用相應的處理函數。
那麼回呼機制是怎麼運作的呢?以上圖為例,首先 epoll 一旦監測到 FD 上有請求到達,就會觸發對應的事件。這些事件會被放進一個佇列中,Redis 主執行緒會對該事件佇列不斷處理,這樣一來 Redis 就不需要一直輪詢是否有請求發生,以避免資源的浪費。
同時,Redis 在對事件佇列中的事件進行處理時,會呼叫對應的處理函數,這就實作了基於事件的回呼。因為 Redis 一直在對事件佇列進行處理,所以能及時回應客戶端請求,提升 Redis 的回應效能。
我們以實際的連線請求和資料讀取請求為例,再解釋一下。連線請求和資料讀取請求分別對應Accept 事件和Read 事件,Redis 分別對這兩個事件註冊accept 和get 回呼函數,當Linux 核心監聽到有連線請求或資料讀取請求時,就會觸發Accept 事件或Read 事件,然後通知主線程,回呼註冊的accept 函數或get 函數。
就像病人去醫院看病,在醫生實際診斷之前每個病人(類似請求)都需要先分診、測體溫、登記等等。如果這些工作都是由醫生完成,那麼醫生的工作效率就會很低。所以醫院設置了分診台,分診台會一直處理這些診斷前的工作(類似於Linux 內核監聽請求),然後再轉交給醫生做實際診斷,這樣即使一個醫生(相當於Redis 的主線程)也能有很高的效率。
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
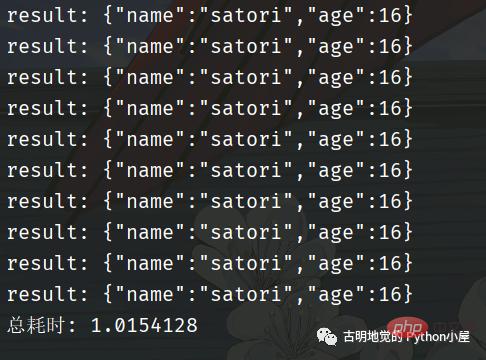
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
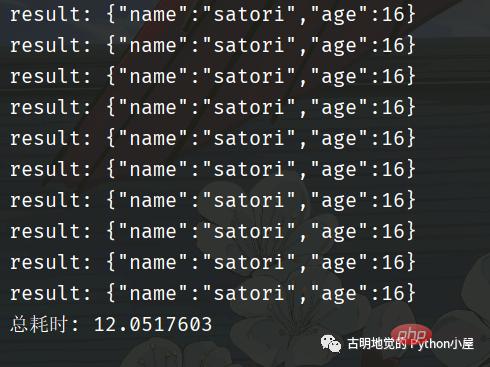
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
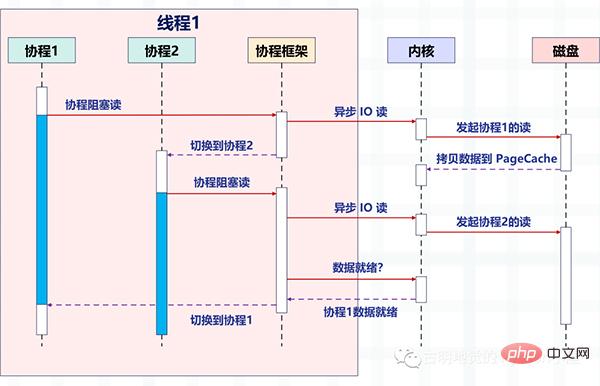
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
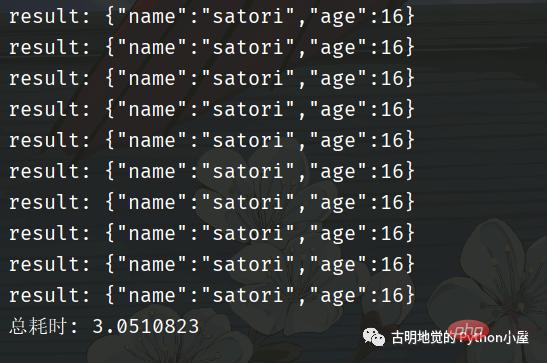
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
那么问题来了,协程的切换是如何完成的呢?
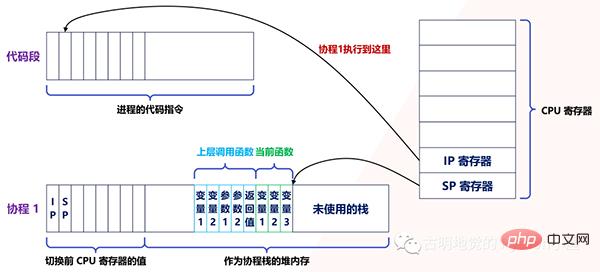
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
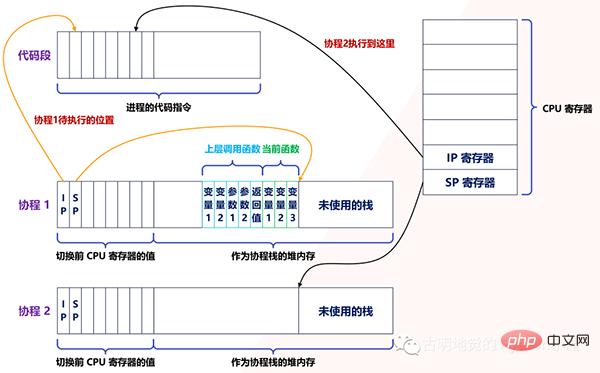
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
例如普通的sleep 函數會讓當前線程休眠,由核心來喚醒線程,而協程化改造後,sleep 只會讓當前協程休眠,由協程框架在指定時間後喚醒協程,所以在Python 的協程裡面我們不能寫time.sleep,而是應該寫asyncio.sleep。再例如,線程間的互斥鎖是使用信號量實現的,而信號量也會導致線程休眠,協程化改造互斥鎖後,同樣由框架來協調、同步各協程的執行。
所以協程的高效能,建立在切換必須由使用者態碼完成之上,這要求協程生態是完整的,要盡量覆蓋常見的元件。
還是以 Python 為例,我常常看見有人在 async def 裡面寫 requests.get 發請求,這是不對的。 requests.get 底層呼叫的是同步阻塞的 socket,這會使得執行緒阻塞,而執行緒一旦阻塞,就會導致所有的協程阻塞,此時就等價於串列。所以把它放在 async def 裡面沒有任何意義,正確的做法是使用 aiohttp 或 httpx。因此如果想使用協程,那麼需要重新封裝底層的系統調用,如果實在沒辦法就丟到線程池中運行。
再例如MySQL 官方提供的客戶端SDK,它使用了阻塞socket 做網絡訪問,會導致線程休眠,必須用非阻塞socket 把SDK 改造為協程函數後,才能在協程中使用。
當然,並不是所有的函數都能用協程改造,例如磁碟的非同步 IO 讀。它雖然是非阻塞的,但無法使用 PageCache,反而降低了系統吞吐量。如果使用快取 IO 讀取文件,在沒有命中 PageCache 時是可能發生阻塞的。這種時候,如果對效能有更高的要求,就需要把執行緒與協程結合起來用,把可能阻塞的操作丟到執行緒池中執行,透過生產者 / 消費者模型與協程配合工作。
實際上,面對多核心系統,也需要協程與執行緒配合工作。因為協程的載體是線程,而一個線程同一時間只能使用一顆 CPU,所以開啟更多的線程,將所有協程分佈在這些線程中,就能充分使用 CPU 資源。有過 Go 語言使用經驗的話,應該很清楚這一點。
除此之外,為了讓協程獲得更多的CPU 時間,還可以設定所在執行緒的優先權,例如在Linux 中把執行緒的優先權設定到-20,就可以每次都獲得更長的時間片。另外 CPU 快取對程式效能也是有影響的,為了減少 CPU 快取失效的比例,也可以把執行緒綁定到某個 CPU 上,增加協程執行時命中 CPU 快取的機率。
雖然這裡一直說協程框架在調度協程,然而你會發現,很多協程庫只提供了創建、掛起、恢復執行等基本方法,並沒有協程框架的存在,需要業務代碼自行調度協程。這是因為,這些通用的協程庫(例如 asyncio)並不是專為伺服器設計的,伺服器中可以由客戶端網路連線的建立,驅動著建立出協程,同時伴隨著請求的結束而終止。
而在協程的運作條件不滿足時,多路復用框架會將它掛起,並根據優先權策略選擇另一個協程執行。因此,使用協程實現伺服器端的高並發服務時,並不只是選擇協程庫,還要從其生態中找到結合 IO 多路復用的協程框架(例如 Tornado),這樣可以加快開發速度。
從廣義上講,協程是一種輕量級的並發模型,說的比較高大上。但從狹義上講,協程就是呼叫一個可以暫停並切換的函數。像我們使用 async def 定義的就是一個協程函數,本質上也是個函數,而呼叫協程函數就會得到一個協程。
將協程丟進事件循環,由事件循環驅動執行,一旦發生阻塞,便將執行權主動交給事件循環,事件循環再驅動其它協程執行。所以自始至終都只有一個線程,而協程只不過是我們參考線程的結構,在用戶態模擬出來的。
所以呼叫一個普通函數,會一直將內部的程式碼邏輯全部執行完;而呼叫一個協程函數,在內部出現了阻塞,那麼會切換到其它的協程。
但是協程出現阻塞能夠切換有一個重要的前提,就是這個阻塞不能涉及任何的系統調用,例如 time.sleep、同步的 socket 等等。這些都需要核心參與,而核心一旦參與了,那麼造成的阻塞就不單單是阻塞某個協程那麼簡單了(OS 也感知不到協程),而是會使線程阻塞。線程一旦阻塞,在其之上的所有協程都會阻塞,由於協程是以線程作為載體的,實際執行的肯定是線程,如果每個協程都會使得線程阻塞,那麼此時不就相當於串行了嗎?
所以想使用協程,必須將阻塞的系統呼叫重新封裝,我們舉個栗子:
@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
所以在使用協程的時候,最好再搭配一個線程池,如果某些阻塞必須要經過內核,實在無法協程化,那麼就把它丟到線程池裡面,在線程的層面完成切換。雖然開啟多個執行緒會佔用資源,還有執行緒切換會帶來開銷,但為了讓經過核心的阻塞能夠切換,這是無法避免的,只能將希望寄託於執行緒;當然,CPU 過度密集的任務,也可以考慮丟到線程池。或許有人好奇,如果能利用多核心,那麼丟到執行緒池是理所當然的,但是 Python 的多執行緒用不了多核呀,為什麼要這麼做呢?原因很簡單,如果只有單一線程,那麼這種 CPU 過度密集的任務會長時間霸占 CPU 資源,導致其它任務無法執行。而開啟多線程,雖然還是只有一個核,但是由於 GIL 會使得線程切換,所以不會出現“楚王好細腰,後宮多餓死”的情況,CPU 能夠雨露均霑,讓所有任務都得到執行。
以上是滿滿的乾貨!全面的介紹Python的協程是如何實現!看懂算你牛!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















