

怎麼使用Java爬蟲批量爬取圖片

爬取想法
對於這種圖片的獲取,其實本質上就是檔案的下載(HttpClient)。但因為不只是取得一張圖片,所以還會有一個頁面解析的處理過程(Jsoup)。
Jsoup:解析html頁面,取得圖片的連結。
HttpClient:請求圖片的鏈接,將圖片儲存到本機。
具體步驟
先進入首頁分析,主要有以下幾個分類(這裡不是全部分類,但這幾個也足夠了,這只是學習技術而已。),我們的目標就是取得每個分類下的圖片。
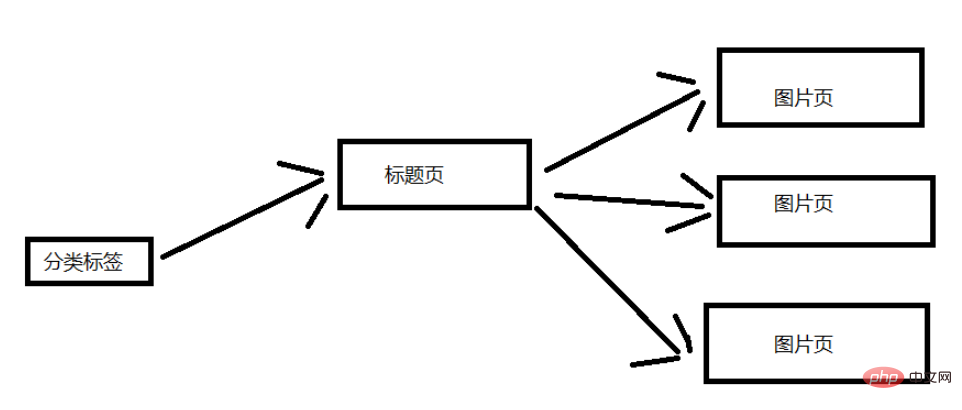
這裡來分析一下網站的架構,我這裡就簡單一點吧。下面這張圖片是大致的結構,這裡選取一個分類標籤來說明。 一個分類標籤頁含有多個標題頁,然後每個標題頁含有多個圖片頁。 (對應標題頁的幾十張圖片)
具體程式碼
匯入專案依賴jar包座標或直接下載對應的jar包,導入項目也可。
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>實體類別 Picture 和 工具類別 HeaderUtil
實體類別:把屬性封裝成一個對象,這樣呼叫方便一點。
package com.picture;
public class Picture {
private String title;
private String url;
public Picture(String title, String url) {
this.title = title;
this.url = url;
}
public String getTitle() {
return this.title;
}
public String getUrl() {
return this.url;
}
}工具類:不斷變換UA(我也不知道有沒有用,不過我是用自己的ip,估計用處不大了)
package com.picture;
public class HeaderUtil {
public static String[] headers = {
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11",
"Opera/9.25 (Windows NT 5.1; U; en)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12",
"Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9",
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
};
}下載類別
多執行緒實在太快了,再加上我只有一個ip,沒有代理ip可以用(我也不太了解),使用多執行緒被封ip是很快的。
package com.picture;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.Random;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import com.m3u8.HttpClientUtil;
public class SinglePictureDownloader {
private String referer;
private CloseableHttpClient httpClient;
private Picture picture;
private String filePath;
public SinglePictureDownloader(Picture picture, String referer, String filePath) {
this.httpClient = HttpClientUtil.getHttpClient();
this.picture = picture;
this.referer = referer;
this.filePath = filePath;
}
public void download() {
HttpGet get = new HttpGet(picture.getUrl());
Random rand = new Random();
//设置请求头
get.setHeader("User-Agent", HeaderUtil.headers[rand.nextInt(HeaderUtil.headers.length)]);
get.setHeader("referer", referer);
System.out.println(referer);
HttpEntity entity = null;
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
entity = response.getEntity();
if (entity != null) {
File picFile = new File(filePath, picture.getTitle());
try (OutputStream out = new BufferedOutputStream(new FileOutputStream(picFile))) {
entity.writeTo(out);
System.out.println("下载完毕:" + picFile.getAbsolutePath());
}
}
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//关闭实体,关于 httpClient 的关闭资源,有点不太了解。
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}這是一個取得 HttpClient 連線的工具類,避免頻繁建立連線的效能消耗。 (但是因為我在這裡是使用單線程來爬取,所以用處就不大了。我就是可以只用一個HttpClient連接來爬取,這是因為我剛開始是使用多線程來爬取的,但是基本獲取幾張圖片就被禁掉了,所以改成單線程爬蟲。所以這個連接池也就留下來了。)
package com.m3u8;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
public class HttpClientUtil {
private static final int TIME_OUT = 10 * 1000;
private static PoolingHttpClientConnectionManager pcm; //HttpClient 连接池管理类
private static RequestConfig requestConfig;
static {
requestConfig = RequestConfig.custom()
.setConnectionRequestTimeout(TIME_OUT)
.setConnectTimeout(TIME_OUT)
.setSocketTimeout(TIME_OUT).build();
pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(50);
pcm.setDefaultMaxPerRoute(10); //这里可能用不到这个东西。
}
public static CloseableHttpClient getHttpClient() {
return HttpClients.custom()
.setConnectionManager(pcm)
.setDefaultRequestConfig(requestConfig)
.build();
}
}最重要的類別:解析頁麵類PictureSpider
package com.picture;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.m3u8.HttpClientUtil;
/**
* 首先从顶部分类标题开始,依次爬取每一个标题(小分页),每一个标题(大分页。)
* */
public class PictureSpider {
private CloseableHttpClient httpClient;
private String referer;
private String rootPath;
private String filePath;
public PictureSpider() {
httpClient = HttpClientUtil.getHttpClient();
}
/**
* 开始爬虫爬取!
*
* 从爬虫队列的第一条开始,依次爬取每一条url。
*
* 分页爬取:爬10页
* 每个url属于一个分类,每个分类一个文件夹
* */
public void start(List<String> urlList) {
urlList.stream().forEach(url->{
this.referer = url;
String dirName = url.substring(22, url.length()-1); //根据标题名字去创建目录
//创建分类目录
File path = new File("D:/DragonFile/DBC/mzt/", dirName); //硬编码路径,需要用户自己指定一个
if (!path.exists()) {
path.mkdir();
rootPath = path.toString();
}
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}
});
}
/**
* 标题分页获取链接
* */
public void page(String url) {
System.out.println("url:" + url);
String html = this.getHtml(url); //获取页面数据
Map<String, String> picMap = this.extractTitleUrl(html); //抽取图片的url
if (picMap == null) {
return ;
}
//获取标题对应的图片页面数据
this.getPictureHtml(picMap);
}
private String getHtml(String url) {
String html = null;
HttpGet get = new HttpGet(url);
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36");
get.setHeader("referer", url);
try (CloseableHttpResponse response = httpClient.execute(get)) {
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
HttpEntity entity = response.getEntity();
if (entity != null) {
html = EntityUtils.toString(entity, "UTf-8"); //关闭实体?
}
}
else {
System.out.println(statusCode);
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
private Map<String, String> extractTitleUrl(String html) {
if (html == null) {
return null;
}
Document doc = Jsoup.parse(html, "UTF-8");
Elements pictures = doc.select("ul#pins > li");
//不知为何,无法直接获取 a[0],我不太懂这方面的知识。
//那我就多处理一步,这里先放下。
Elements pictureA = pictures.stream()
.map(pic->pic.getElementsByTag("a").first())
.collect(Collectors.toCollection(Elements::new));
return pictureA.stream().collect(Collectors.toMap(
pic->pic.getElementsByTag("img").first().attr("alt"),
pic->pic.attr("href")));
}
/**
* 进入每一个标题的链接,再次分页获取图片的链接
* */
private void getPictureHtml(Map<String, String> picMap) {
//进入标题页,在标题页中再次分页下载。
picMap.forEach((title, url)->{
//分页下载一个系列的图片,每个系列一个文件夹。
File dir = new File(rootPath, title.trim());
if (!dir.exists()) {
dir.mkdir();
filePath = dir.toString(); //这个 filePath 是每一个系列图片的文件夹
}
for (int i = 1; i <= 60; i++) {
String html = this.getHtml(url + "/" + i);
if (html == null) {
//每个系列的图片一般没有那么多,
//如果返回的页面数据为 null,那就退出这个系列的下载。
return ;
}
Picture picture = this.extractPictureUrl(html);
System.out.println("开始下载");
//多线程实在是太快了(快并不是好事,我改成单线程爬取吧)
SinglePictureDownloader downloader = new SinglePictureDownloader(picture, referer, filePath);
downloader.download();
try {
Thread.sleep(1500); //不要爬的太快了,这里只是学习爬虫的知识。不要扰乱别人的正常服务。
System.out.println("爬取完一张图片,休息1.5秒。");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
/**
* 获取每一页图片的标题和链接
* */
private Picture extractPictureUrl(String html) {
Document doc = Jsoup.parse(html, "UTF-8");
//获取标题作为文件名
String title = doc.getElementsByTag("h3")
.first()
.text();
//获取图片的链接(img 标签的 src 属性)
String url = doc.getElementsByAttributeValue("class", "main-image")
.first()
.getElementsByTag("img")
.attr("src");
//获取图片的文件扩展名
title = title + url.substring(url.lastIndexOf("."));
return new Picture(title, url);
}
}啟動類別BootStrap
這裡有一個爬蟲隊列,但是我最後連第一個都沒有爬取完,這是因為我計算失誤了,少算了兩個數量級。但是,程式的功能是正確的。
package com.picture;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 爬虫启动类
* */
public class BootStrap {
public static void main(String[] args) {
//反爬措施:UA、refer 简单绕过就行了。
//refer https://www.mzitu.com
//使用数组做一个爬虫队列
String[] urls = new String[] {
"https://www.mzitu.com/xinggan/",
"https://www.mzitu.com/zipai/"
};
// 添加初始队列,启动爬虫
List<String> urlList = new ArrayList<>(Arrays.asList(urls));
PictureSpider spider = new PictureSpider();
spider.start(urlList);
}
}爬取結果

#注意事項
##這裡有一個計算錯誤,程式碼如下:
for (int i = 1; i <= 10; i++) { //分页获取图片数据,简单获取几页就行了
this.page(url + "page/"+ 1);
}我一開始以為只有幾百張圖片! 這是一個估計值,但是真實的下載量和這個不會差太多的(沒有數量級的差距)。所以我下載了一會發現只下載了第一個隊列裡面的圖片。當然了,作為一個爬蟲學習的程序,它還是很合格的。
這個程序只是用來學習的,我設定每張圖片的下載間隔時間是1.5秒,而且是單線程的程序,所以速度上會顯得很慢。但那樣也沒關係,只要程式的功能正確就好了,應該沒有人會真的等到圖片下載完吧。
那估計要好久了:64800*1.5s = 97200s = 27h,這也只是一個粗略的估計值,沒有考慮程式的其他運行時間,不過其他時間可以基本忽略了。
以上是怎麼使用Java爬蟲批量爬取圖片的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHPhassignificantlyimpactedwebdevelopmentandextendsbeyondit.1)ItpowersmajorplatformslikeWordPressandexcelsindatabaseinteractions.2)PHP'sadaptabilityallowsittoscaleforlargeapplicationsusingframeworkslikeLaravel.3)Beyondweb,PHPisusedincommand-linescrip
 Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
膠囊是一種三維幾何圖形,由一個圓柱體和兩端各一個半球體組成。膠囊的體積可以通過將圓柱體的體積和兩端半球體的體積相加來計算。本教程將討論如何使用不同的方法在Java中計算給定膠囊的體積。 膠囊體積公式 膠囊體積的公式如下: 膠囊體積 = 圓柱體體積 兩個半球體體積 其中, r: 半球體的半徑。 h: 圓柱體的高度(不包括半球體)。 例子 1 輸入 半徑 = 5 單位 高度 = 10 單位 輸出 體積 = 1570.8 立方單位 解釋 使用公式計算體積: 體積 = π × r2 × h (4
 PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP成為許多網站首選技術棧的原因包括其易用性、強大社區支持和廣泛應用。 1)易於學習和使用,適合初學者。 2)擁有龐大的開發者社區,資源豐富。 3)廣泛應用於WordPress、Drupal等平台。 4)與Web服務器緊密集成,簡化開發部署。
