

上海數位大腦研究院發表國內首個多模態決策大模型DB1,可實現超複雜問題快速決策

近日,上海数字大脑研究院(以下简称 “数研院”)推出首个数字大脑多模态决策大模型(简称 DB1),填补了国内在此方面的空白,进一步验证了预训练模型在文本、图 - 文、强化学习决策、运筹优化决策方面应用的潜力。目前,DB1代码我们已开源在Github,项目链接:https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1。
此前,数研院提出 MADT(https://arxiv.org/abs/2112.02845)/MAT(https://arxiv.org/abs/2205.14953)等多智能体模型,在一些离线大模型通过序列建模,使用 Transformer 模型在一些单 / 多智能体任务上取得了显著效果,并持续在该方向上进行研究探索。
过去几年,随着预训练大模型的兴起,学术界与产业界在预训练模型的参数量与多模态任务上不断取得新的进展,大规模预训练模型通过对海量数据和知识的深度建模,被认为是通往通用人工智能的重要路径之一。专注决策智能研究的数研院创新性地尝试将预训练模型的成功复制到决策任务上,并且取得了突破。
多模态决策大模型 DB1
此前,DeepMind 推出 Gato,将单智能体决策任务、多轮对话和图片 - 文本生成任务统一到一个基于 Transformer 的自回归问题上,并在 604 个不同任务上取得了良好表现,显示出通过序列预测能够解决一些简单的强化学习决策问题,这在侧面验证了数研院在决策大模型研究方向的正确性。
此次,数研院推出的 DB1,主要对 Gato 进行了复现与验证,并从网络结构与参数量、任务类型与任务数量两方面尝试进行了改进:
-
参数量与网络结构:DB1 参数量达 12.1 亿。在参数量上尽量做到与 Gato 接近。整体来说,数研院使用了与 Gato 类似的结构(相同的 Decoder Block 数量、隐层大小等),但在 FeedForwardNetwork 中,由于 GeGLU 激活函数会额外引入 1/3 的参数量,数研院为了接近 Gato 的参数量,使用 4 * n_embed 维的隐层状态经过 GeGLU 激活函数后变成 2 * n_embed 维的特征。在其他方面,我们与 Gato 的实现一样在输入输出编码端共享了 embedding 参数。不同于 Gato,在 layer normalization 的选择上我们采用了 PostNorm 的方案,同时我们在 Attention 上使用混合精度计算,提高了数值稳定性。
- 任务类型与任务数量:DB1 的实验任务数量达 870,较 Gato 提升了 44.04%,较 Gato 在 >=50% 专家性能上提升 2.23%。具体任务类型上,DB1 大部分继承了 Gato 的决策、图像和文本类任务,各类任务数量基本维持一致。但在决策类任务方面,DB1 另外引入了 200 余个现实场景任务,即 100 和 200 节点规模的旅行商问题(TSP,此类任务在所有中国主要城市随机选择 100-200 个地理位置作为结点表征)求解。
可以看到的是,DB1 整体表现已经与 Gato 达到同一水平,并已经开始向更加贴近实际业务的需求领域体进化,很好地求解了 NP-hard 的 TSP 问题,而此前 Gato 并未在此方向探索。
 DB1 (右) 与 GATO (左)指标对比
DB1 (右) 与 GATO (左)指标对比
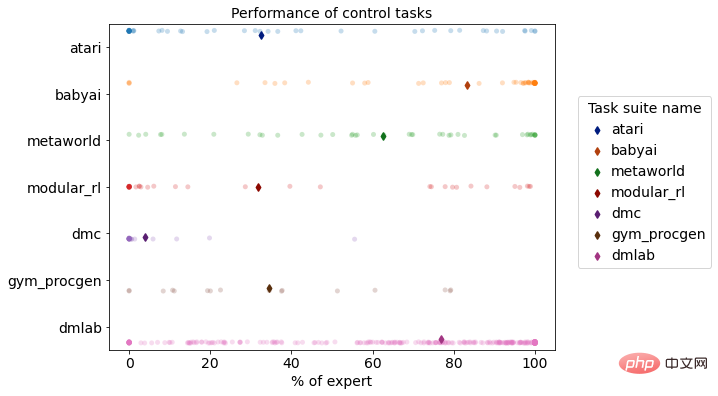
DB1 在强化学习模拟环境上的多任务性能分布
相較於傳統的決策演算法,DB1 在跨任務決策能力和快速遷移能力上都有不錯的表現。從跨任務決策能力和參數量來說,實現了從單一複雜任務的千萬- 億級別參數量到多個複雜任務的十億級別參數的跨越,並持續增長,並且具備解決複雜商業環境中的實際問題的充分能力。從遷移能力來說,DB1 完成了從智慧預測到智慧決策、從單智能體到多智能體的跨越,彌補傳統方法在跨任務遷移方面的不足,使得企業內部建立大模型成為可能。
不可否認的是,DB1 在開發過程也遇到了許多難點,數研究院進行了大量嘗試,可為業內在大規模模型訓練及多任務訓練資料儲存方面提供一些標準解決路徑。由於模型參數到達 10 億參數規模且任務規模龐大,同時需要在超過 100T(300B Tokens)的專家資料上進行訓練,普通的深度強化學習訓練框架已無法滿足在該種情況下的快速訓練。為此,一方面,針對分散式訓練,數研院充分考慮強化學習、運籌優化和大模型訓練的運算結構,在單機多卡和多機多卡的環境下,極致利用硬體資源,巧妙設計模組間的通訊機制,盡可能提升模型的訓練效率,將870 個任務的訓練時間縮短到了一週。另一方面,針對分散式隨機採樣,訓練過程所需資料索引、儲存、載入以及預處理也成為對應瓶頸,數研院在載入資料集時採用了延遲載入模式,以解決記憶體限制問題並儘可能充分利用可用記憶體。此外,在對載入資料進行預處理後,會將處理過的資料快取至硬碟中,便於此後可直接載入預處理完成的數據,縮減重複預處理帶來的時間和資源成本。
目前,國際國內頭部企業與研究機構如OpenAI、Google、Meta、華為、百度和達摩院等都已經進行了多模態大模型相關的研究並且有了一定商業化嘗試,包括在自身產品中應用或提供模型API 和相關產業解決方案。相較之下,數研究所更關注決策問題,同時支援遊戲 AI 決策任務、運籌優化 TSP 求解任務、機器人決策控制任務、黑盒優化求解任務與多輪對話任務上進行應用嘗試。
任務表現
運籌最佳化:TSP 問題求解
以中國部分城市為節點的TSP 問題
強化學習任務影片示範
DB1 模型在完成870 個不同決策任務的離線學習後,其評估結果顯示有76.67% 的任務達到或超過50% 的專家水準。以下是一些任務的效果展示。
- 電子遊戲場景:DB1 可以接收2D/3D 影像輸入,並且很好地完成類別如Atari,Procgen 在內的2D 像素遊戲,同時對於DMLab 這種與真實世界較為相似的3D 影像輸入任務,DB1 也展現了良好的效能。

Atari Breakout



Metaworld PlateSlide

ModularRL Cheetah
文字- 圖像任務
- #文字產生:給出一段文字提示,產生長文本描述
- 輸入提示:digital brain laboratory is a shanghai based
-
產生結果:digital brain laboratory is a shanghai based company and we are looking for a highly skilled and experienced person to join our team in shanghai, china.
we are a digital brain lab and we are looking for a highly skilled and experienced person to join our team in#.
##this is an opportunity to work for a well known and growing company that is going through a fast growth phase and to have an impact in the market.
full-time, permanent position.
We are looking for a highly skilled, motivated and experienced software engineer who can lead a team of 5-10 in a highly competitive environment - #圖像描述產生:給定一張圖片產生對應文字描述

目前決策大模型的限制與未來方向
雖然當前多模態決策預訓練模型DB1 取得了一定效果,但仍存在一定局限性,諸如:跨域任務採樣權重敏感、跨域知識遷移困難、長序列建模困難、專家資料強烈依賴等。雖然有許多挑戰,但現階段看來,多模態決策大模型是實現決策智能體從遊戲走向更廣泛場景,從虛擬走向現實,在現實開放動態環境中進行自主感覺與決策,最終實現更加通用人工智慧的關鍵探索方向之一。未來,數研究所將持續迭代數位大腦決策大模型,透過更大參數量,更有效的序列表徵,存取與支援更多任務,結合離線/ 線訓練與微調,實現跨域、跨模態、跨任務的知識泛化與遷移,最終在現實應用場景下提供更通用、更有效率、更低成本的決策智慧決策解決方案。
以上是上海數位大腦研究院發表國內首個多模態決策大模型DB1,可實現超複雜問題快速決策的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
本站6月27日訊息,剪映是由位元組跳動旗下臉萌科技開發的一款影片剪輯軟體,依託於抖音平台且基本面向該平台用戶製作短影片內容,並相容於iOS、安卓、Windows 、MacOS等作業系統。剪映官方宣布會員體系升級,推出全新SVIP,包含多種AI黑科技,例如智慧翻譯、智慧劃重點、智慧包裝、數位人合成等。價格方面,剪映SVIP月費79元,年費599元(本站註:折合每月49.9元),連續包月則為59元每月,連續包年為499元每年(折合每月41.6元) 。此外,剪映官方也表示,為提升用戶體驗,向已訂閱了原版VIP
 使用Rag和Sem-Rag提供上下文增強AI編碼助手
Jun 10, 2024 am 11:08 AM
使用Rag和Sem-Rag提供上下文增強AI編碼助手
Jun 10, 2024 am 11:08 AM
透過將檢索增強生成和語意記憶納入AI編碼助手,提升開發人員的生產力、效率和準確性。譯自EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG,作者JanakiramMSV。雖然基本AI程式設計助理自然有幫助,但由於依賴對軟體語言和編寫軟體最常見模式的整體理解,因此常常無法提供最相關和正確的程式碼建議。這些編碼助手產生的代碼適合解決他們負責解決的問題,但通常不符合各個團隊的編碼標準、慣例和風格。這通常會導致需要修改或完善其建議,以便將程式碼接受到應
 微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
大型語言模型(LLM)是在龐大的文字資料庫上訓練的,在那裡它們獲得了大量的實際知識。這些知識嵌入到它們的參數中,然後可以在需要時使用。這些模型的知識在訓練結束時被「具體化」。在預訓練結束時,模型實際上停止學習。對模型進行對齊或進行指令調優,讓模型學習如何充分利用這些知識,以及如何更自然地回應使用者的問題。但是有時模型知識是不夠的,儘管模型可以透過RAG存取外部內容,但透過微調使用模型適應新的領域被認為是有益的。這種微調是使用人工標註者或其他llm創建的輸入進行的,模型會遇到額外的實際知識並將其整合
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 SK 海力士 8 月 6 日將展示 AI 相關新品:12 層 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
SK 海力士 8 月 6 日將展示 AI 相關新品:12 層 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
本站8月1日消息,SK海力士今天(8月1日)發布博文,宣布將出席8月6日至8日,在美國加州聖克拉拉舉行的全球半導體記憶體峰會FMS2024,展示諸多新一代產品。未來記憶體和儲存高峰會(FutureMemoryandStorage)簡介前身是主要面向NAND供應商的快閃記憶體高峰會(FlashMemorySummit),在人工智慧技術日益受到關注的背景下,今年重新命名為未來記憶體和儲存高峰會(FutureMemoryandStorage),以邀請DRAM和儲存供應商等更多參與者。新產品SK海力士去年在
 SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
編輯|KX在藥物研發領域,準確有效地預測蛋白質與配體的結合親和力對於藥物篩選和優化至關重要。然而,目前的研究並沒有考慮到分子表面訊息在蛋白質-配體相互作用中的重要作用。基於此,來自廈門大學的研究人員提出了一種新穎的多模態特徵提取(MFE)框架,該框架首次結合了蛋白質表面、3D結構和序列的信息,並使用交叉注意機制進行不同模態之間的特徵對齊。實驗結果表明,該方法在預測蛋白質-配體結合親和力方面取得了最先進的性能。此外,消融研究證明了該框架內蛋白質表面資訊和多模態特徵對齊的有效性和必要性。相關研究以「S
