
譯者 | 李睿
審校 | 孫淑娟
OpenAI又火了!近期許多人的朋友圈都混進了一個讓人既愛又怕的狠角色,以至於StackOverflow不得不急忙下架。
近日,OpenAI發布了聊天AI ChatGPT,短短幾天,其用戶量直衝百萬級,甚至伺服器一度被註冊用戶擠爆了。
這種被網友驚嘆「超越Google搜尋」的神器究竟怎麼做到的?到底可靠嗎?
OpenAI公司日前發布了ChatGPT,這是另一個基於旗艦GPT系列的大型語言模型(LLM),是專門用於對話互動的模型。用戶可以下載該公司的免費演示版本。
與發布的大多數大型語言模型(LLM)一樣,ChatGPT的發布也引發了一些爭議。在發布之後的短短幾個小時內,這個新的語言模型就在Twitter上引起了轟動,用戶紛紛上傳ChatGPT令人印象深刻的成就或遭遇災難性失敗的截圖。
然而,從大型語言模型的廣泛角度來看,ChatGPT反映了該領域短暫而豐富的歷史,代表了在短短幾年內取得了多大的進展,以及還有哪些基本問題有待解決。
無監督學習仍然是人工智慧社群追求的目標之一,而網路上有大量寶貴的知識和資訊。但直到最近,其中大部分的資訊都無法用於機器學習系統。大多數機器學習和深度學習應用程式都是被監督的,這意味著人類必須收集大量資料樣本並對每個樣本進行註釋,以訓練機器學習系統。
隨著Transformer架構(大型語言模型的關鍵元件)的出現,這種情況發生了變化。可以使用大量的無標記文字語料庫來訓練Transformer模型。它們隨機屏蔽文字的部分,並試圖預測缺少的部分。透過重複執行此操作,Transformer調整其參數,以表示大序列中不同單字之間的關係。
這已被證明是一種非常有效且可擴展的策略。不需要人工標記,就可以收集非常大的訓練語料庫,從而允許創建和訓練越來越大的Transformer模型。研究和實驗表明,隨著Transformer模型和大型語言模型(LLM)的規模增大,它們可以產生更長的連貫文字序列。大型語言模型(LLM)也展示了大規模的應急能力。
大型語言模型(LLM)通常只有文本,這意味著它們缺乏試圖模仿的人類豐富的多感官體驗。儘管GPT-3等大型語言模型(LLM)取得了令人印象深刻的成果,但它們存在一些基本缺陷,使得它們在需要常識、邏輯、規劃、推理和其他知識的任務中無法預測,而這些知識通常在文本中被省略。大型語言模型(LLM)以產生幻覺反應、生成連貫但事實上虛假的文本以及經常誤解用戶提示的明顯意圖而聞名。
透過加大模型及其訓練語料庫的規模,科學家們已經能夠減少大型語言模型中明顯錯誤的頻率。但根本的問題並沒有消失,即使是最大的大型語言模型(LLM)也會在很小的推動下犯下愚蠢的錯誤。
如果大型語言模型(LLM)只在科學研究實驗室中用於追蹤基準測試的表現,這可能不會是一個大問題。然而,隨著人們對在現實應用中使用大型語言模型(LLM)越來越感興趣,解決這些問題和其他問題變得更加重要。工程師必須確保他們的機器學習模型在不同的條件下保持健壯,並滿足使用者的需求和要求。
為了解決這個問題,OpenAI使用了來自人類回饋強化學習(RLHF)技術,該技術先前已開發用於優化強化學習模型。人類回饋強化學習(RLHF)不是讓強化學習模型隨機探索其環境和行為,而是使用人類主管的偶爾回饋來引導代理人朝著正確的方向前進。人類回饋的強化學習(RLHF)的好處是,它能夠以極小的人為回饋改善強化學習代理的訓練。
OpenAI後來將人類回饋強化學習(RLHF)應用於InstructGPT,這是一個大型語言模型(LLM)系列,旨在更好地理解和回應使用者提示中的指令。 InstructGPT是一個GPT-3模型,它根據人類回饋進行了微調。
這顯然是一種權衡。人工註釋可能成為可擴展訓練過程中的瓶頸。但透過在無監督學習和監督學習之間找到正確的平衡,OpenAI能夠獲得重要的好處,包括更好地回應指令、減少有害輸出和資源最佳化。根據OpenAI的研究結果,13億個參數的InstructionGPT在指令跟隨方面通常優於1750億個參數GPT-3模型。
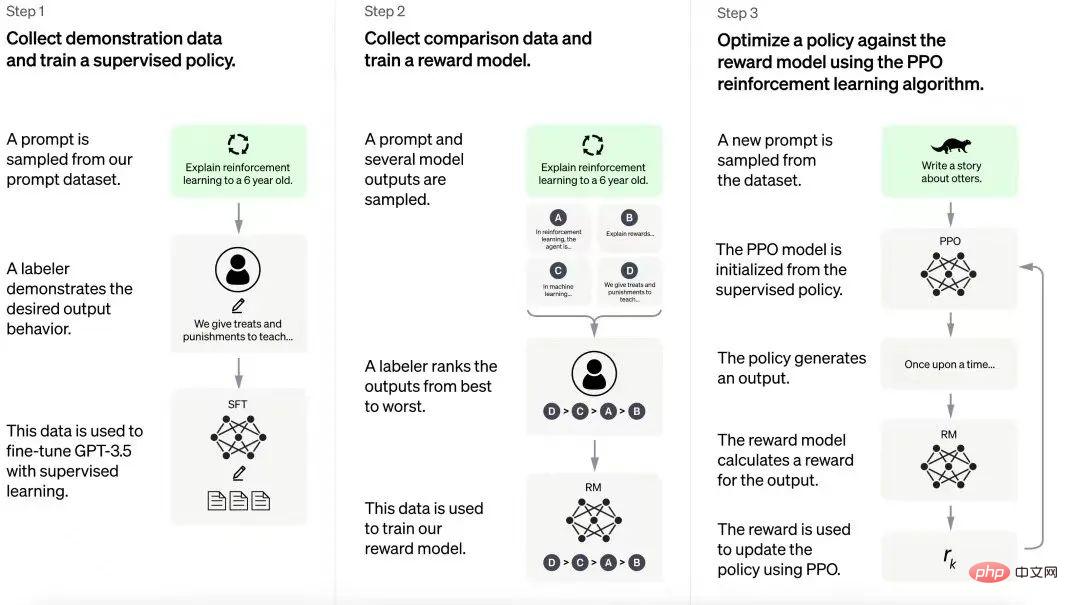
ChatGPT的訓練流程
ChatGPT建立在從InstructGPT模型中獲得的經驗之上。人工註釋器會建立一組範例對話,其中包括使用者提示和模型回應。這些數據用於微調建構ChatGPT所基於的GPT-3.5模型。在下一步中,將為經過微調的模型提供新的提示,並為其提供若干響應。標註人員對這些反應進行排名。然後,從這些交互作用產生的資料被用來訓練獎勵模型,這有助於在強化學習管道中進一步微調大型語言模型(LLM)。
OpenAI尚未透露強化學習過程的全部細節,但人們很想知道這個過程的“不可擴展的成本”,也就是需要多少人力。
ChatGPT的結果令人印象深刻。該模型已經完成了各種各樣的任務,包括提供程式碼回饋、寫詩、用不同的音調解釋技術概念、為生成人工智慧模型產生提示。
然而,該模型也容易出現類似大型語言模型(LLM)所犯的那種錯誤,例如引用不存在的論文和書籍,誤解直觀的物理學,以及在組合性方面失敗。
人們對這些失敗並不感到驚訝。 ChatGPT並沒有發揮什麼神奇的作用,它應該會遇到與它的前一代相同的問題。然而,在現實世界的應用中,可以在哪裡以及在多大程度上信任它?顯然,這裡有一些有價值的內容,正如人們在Codex和GitHubCopilot中所看到的,大型語言模型(LLM)可以被非常有效地使用。
在這裡,決定ChatGPT是否有用的是與它一起實現的工具和保護的種類。例如,ChatGPT可能成為為企業創建聊天機器人的一個非常好的平台,例如編碼和圖形設計的數位伴侶。首先,如果它遵循InstructGPT的範例,那麼應該能夠以更少的參數獲得複雜模型的效能,這將使它具有成本效益。此外,如果OpenAI提供了工具,使企業能夠實現自己的人類反饋強化學習(RLHF)的微調,那麼它可以進一步針對特定應用程式進行最佳化,在大多數情況下,這比聊天機器人更有用,聊天機器人可以隨意談論任何事情。最後,如果為應用程式開發人員提供了將ChatGPT與應用程式場景集成,並將其輸入和輸出映射到特定應用程式事件和操作的工具,他們將能夠設定正確的護欄,以防止模型採取不穩定的操作。
基本上,OpenAI創造了一個強大的人工智慧工具,但具有明顯的缺陷。現在它需要創建正確的開發工俱生態系統,以確保產品團隊能夠利用ChatGPT的力量。 GPT-3為許多不可預測的應用開闢了道路,因此了解ChatGPT的庫存會很有趣。
原文連結:https://bdtechtalks.com/2022/12/05/openai-chatgpt/
以上是5天用戶破百萬,ChatGPT背後有何玄機?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















