

Python大數據為啥一定要用Numpy Array?


Numpy 是Python科學計算的一個核心模組。它提供了非常有效率的數組對象,以及用於處理這些數組對象的工具。一個Numpy數組由許多值組成,所有值的類型是相同的。
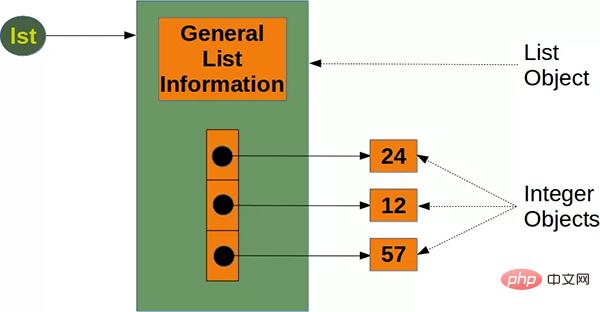
Python的核心庫提供了 List 清單。清單是最常見的Python資料類型之一,它可以調整大小並且包含不同類型的元素,非常方便。
那麼List和Numpy Array到底有什麼差別?為什麼我們需要在大數據處理的時候使用Numpy Array?答案是性能。
Numpy資料結構在以下方面表現較好:
1.記憶體大小—Numpy資料結構所佔用的記憶體較小。
2.效能—Numpy底層是用C語言實現的,比列表更快。
3.運算方法—內建最佳化了代數運算等方法。
下面分別講解在大數據處理時,Numpy陣列相對於List的優勢。
1.記憶體佔用更小
適當地使用Numpy陣列取代List,你能讓你的記憶體佔用降低20倍。
對於Python原生的List列表,由於每次新增對象,都需要8個位元組來引用新對象,新的對象本身佔28個位元組(以整數為例)。所以列表list 的大小可以用以下公式計算:
64 8 * len(lst) len(lst) * 28 位元組
而使用Numpy ,就能減少非常多的空間佔用。例如長度為n的Numpy整形Array,它需要:
96 len(a) * 8 位元組

可見,陣列越大,你省的記憶體空間越多。假設你的陣列有10億個元素,那麼這個記憶體佔用大小的差距會是GB等級的。
2.速度更快、內建運算方法
運行下面這個腳本,同樣是產生某個維度的兩個陣列並相加,你就能看到原生List和Numpy Array的性能差距。
import time
import numpy as np
size_of_vec = 1000
def pure_python_version():
t1 = time.time()
X = range(size_of_vec)
Y = range(size_of_vec)
Z = [X[i] + Y[i] for i in range(len(X)) ]
return time.time() - t1
def numpy_version():
t1 = time.time()
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
Z = X + Y
return time.time() - t1
t1 = pure_python_version()
t2 = numpy_version()
print(t1, t2)
print("Numpy is in this example " + str(t1/t2) + " faster!")
結果如下:
0.00048732757568359375 0.0002491474151611328 Numpy is in this example 1.955980861244019 faster!
可以看到,Numpy比原生陣列快1.95倍。
如果你細心的話,還能發現,Numpy array可以直接執行加法操作。而原生的陣列是做不到這一點的,這就是Numpy 運算方法的優勢。
我們再做幾次重複試驗,以證明這個效能優勢是持久性的。
import numpy as np
from timeit import Timer
size_of_vec = 1000
X_list = range(size_of_vec)
Y_list = range(size_of_vec)
X = np.arange(size_of_vec)
Y = np.arange(size_of_vec)
def pure_python_version():
Z = [X_list[i] + Y_list[i] for i in range(len(X_list)) ]
def numpy_version():
Z = X + Y
timer_obj1 = Timer("pure_python_version()",
"from __main__ import pure_python_version")
timer_obj2 = Timer("numpy_version()",
"from __main__ import numpy_version")
print(timer_obj1.timeit(10))
print(timer_obj2.timeit(10)) # Runs Faster!
print(timer_obj1.repeat(repeat=3, number=10))
print(timer_obj2.repeat(repeat=3, number=10)) # repeat to prove it!
結果如下:
0.0029753120616078377 0.00014940369874238968 [0.002683573868125677, 0.002754641231149435, 0.002803879790008068] [6.536301225423813e-05, 2.9387418180704117e-05, 2.9171351343393326e-05]
可以看到,第二個輸出的時間總是小得多,這證明了這個效能優勢是具有持久性的。
所以,如果你在做一些大數據研究,像是金融數據、股票數據的研究,使用Numpy能夠節省你不少記憶體空間,並擁有更強大的效能。
參考文獻:https://www.php.cn/link/5cce25ff8c3ce169488fe6c6f1ad3c97
#我們的文章到此就結束啦,如果你喜歡今天的Python 實戰教程,請持續關注我們。
以上是Python大數據為啥一定要用Numpy Array?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
