
只輸入一行文本,就能產生 3D 動態場景?
沒錯,已經有研究者做到了。可以看出來,目前的生成效果還處於初級階段,只能產生一些簡單的物件。不過這種「一步到位」的方法仍然引起了大量研究者的關注:

在最近的一篇論文中,來自Meta 的研究者首次提出了可以從文本描述中產生三維動態場景的方法MAV3D (Make-A-Video3D)。

具體而言,該方法運用4D 動態神經輻射場(NeRF),透過查詢基於文字到視訊(T2V)擴散的模型,優化場景外觀、密度和運動的一致性。任意機位或角度都可以觀看到提供的文字產生的動態視訊輸出,並且可以合成到任何 3D 環境中。
MAV3D 不需要任何 3D 或 4D 數據,T2V 模型只對文字影像對和未標記的影片進行訓練。

讓我們來看看MAV3D 從文字產生4D 動態場景的效果:

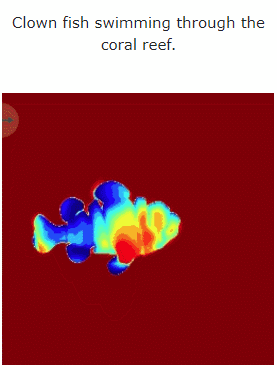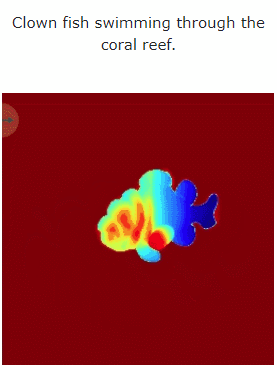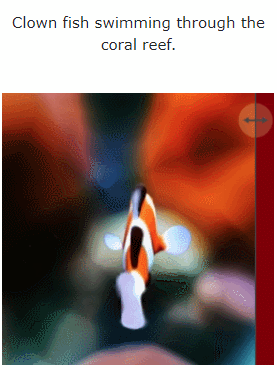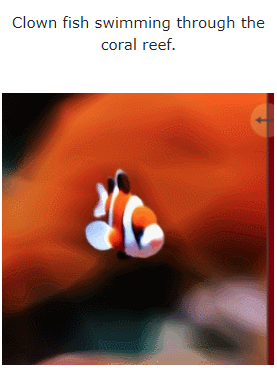
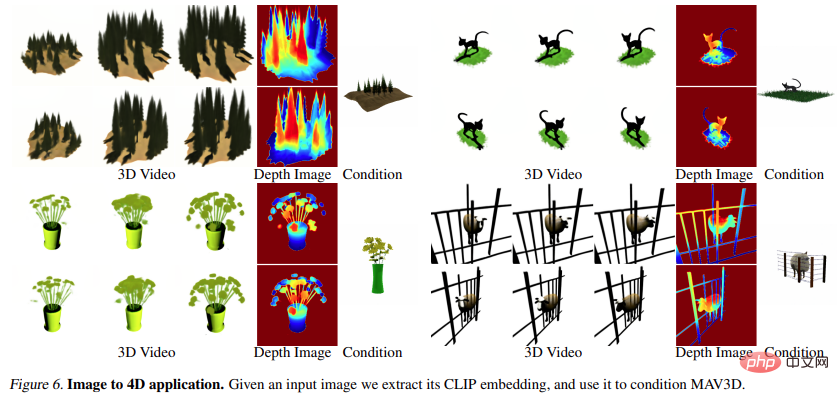
#此外,它也能從圖片直接到4D,效果如下:


#研究者透過全面的量化和質化實驗證明了此方法的有效性,先前建立的內部baseline 也得到了改進。據悉,這是第一個根據文字描述產生 3D 動態場景的方法。
研究的目標在於開發一項能從自然語言描述中產生動態 3D 場景表徵的方法。這極具挑戰性,因為既沒有文字或 3D 對,也沒有用於訓練的動態 3D 場景資料。因此,研究者選擇依靠預訓練的文本到視頻(T2V)的擴散模型作為場景先驗,該模型已經學會了通過對大規模圖像、文本和視頻數據的訓練來建模場景的真實外觀和運動。
從更高層次來看,在給定一個文字 prompt p 的情況下,研究可以擬合一個 4D 表徵,它模擬了在時空任意點上與 prompt 匹配的場景外觀。沒有配對訓練數據,研究無法直接監督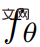 的輸出;然而,給定一系列的相機姿勢
的輸出;然而,給定一系列的相機姿勢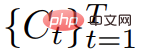 #就可以從
#就可以從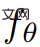 渲染出影像序列
渲染出影像序列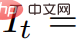
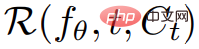 並將它們堆疊成一個視訊V。然後,將文本prompt p 和視頻V 傳遞給凍結和預訓練的T2V 擴散模型,由該模型對視頻的真實性和prompt alignment 進行評分,並使用SDS(得分蒸餾採樣)來計算場景參數θ 的更新方向。
並將它們堆疊成一個視訊V。然後,將文本prompt p 和視頻V 傳遞給凍結和預訓練的T2V 擴散模型,由該模型對視頻的真實性和prompt alignment 進行評分,並使用SDS(得分蒸餾採樣)來計算場景參數θ 的更新方向。
上面的 pipeline 可以算是 DreamFusion 的擴展,為場景模型添加了一個時間維度,並使用 T2V 模型而不是文字到圖像(T2I)模型進行監督。然而,要實現高品質的文本到4D 的生成還需要更多的創新:
具體說明請見下圖:
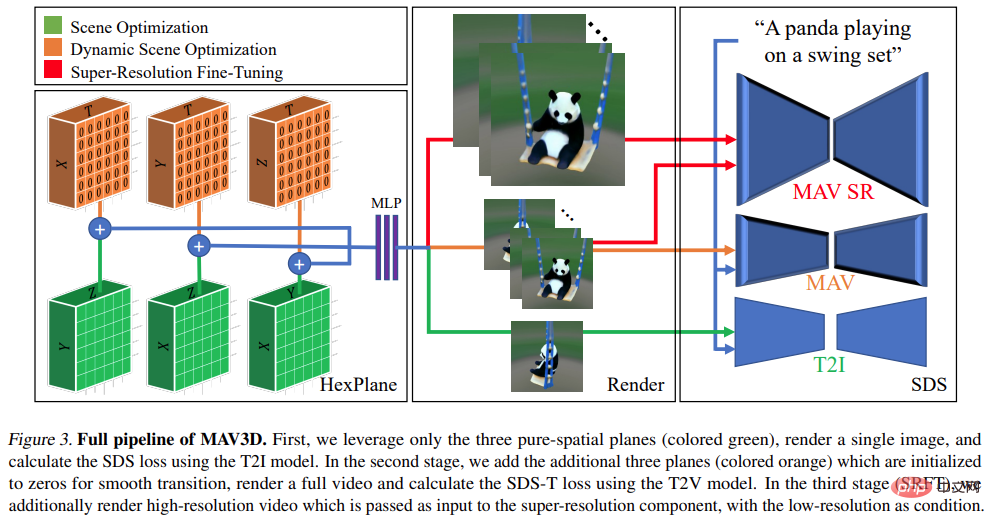
##在實驗中,研究者評估了MAV3D 從文字描述產生動態場景的能力。首先,研究者評估了該方法在 Text-To-4D 任務上的有效性。據悉,MAV3D 是第一個該任務的解決方案,因此研究開發了三種替代方法作為基準。其次,研究者評估了 T2V 和 Text-To-3D 子任務模型的簡化版本,並將其與文獻中現有的基準進行比較。第三,全面的消融研究證明了方法設計的合理性。第四,實驗描述了將動態 NeRF 轉換為動態網格的過程,最終將模型擴展到 Image-to-4D 任務。
#########指標################研究使用CLIP R-Precision 來評估生成的視頻,它可以測量文字和生成場景之間的一致性。報告的指標是從呈現的訊框中檢索輸入 prompt 的準確性。研究者使用CLIP 的ViT-B/32 變體,並在不同的視圖和時間步長中提取幀,並且還通過詢問人工評分人員在兩個生成的視頻中的偏好來使用四個定性指標,分別是:(i) 視訊品質;(ii) 忠於文字prompt;(iii) 活動量;(四) 運動的現實性。研究者評估了在文本 prompt 分割中使用的所有基線和消融。 ######圖 1 和圖 2 為範例。若想了解更詳細的視覺化效果,請參閱 make-a-video3d.github.io。

#表1 顯示了與基線的比較(R - 精確度和人類偏好)。人工評量以在特定環境下與該模型相比,贊成基線多數票的百分比呈現。
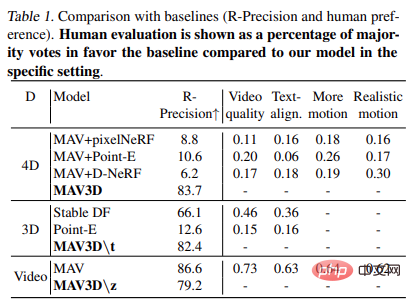
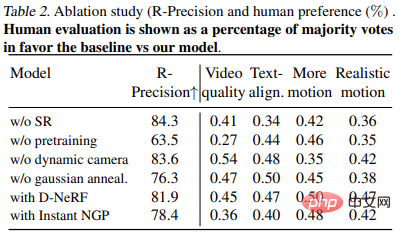
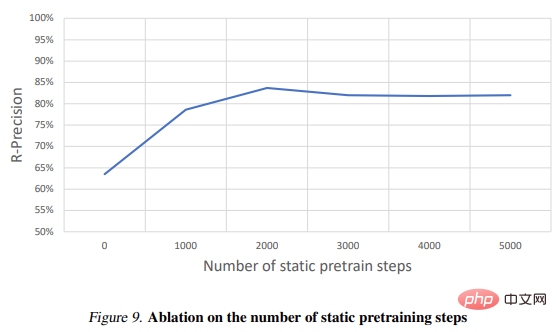
表2 展示了消融實驗的結果:
即時渲染
#使用傳統圖形引擎的虛擬實境和遊戲等應用程式需要標準的格式,如紋理網格。 HexPlane 模型可以輕易轉換為如下的動畫網格。首先,使用 marching cube 演算法從每個時刻 t 產生的不透明度場中提取一個簡單網格,然後進行網格抽取(為了提高效率)並且去除小雜訊連接組件。 XATLAS 演算法用於將網格頂點對應到紋理圖集,紋理初始化使用以每個頂點為中心的小球體中平均的 HexPlane 顏色。最後,為了更好地匹配一些由 HexPlane 使用可微網格渲染的範例幀,紋理會進一步優化。這將產生一個紋理網格集合,可以在任何現成的 3D 引擎中重播。
圖片到4D
#圖6 和圖10 展示了該方法能夠從給定的輸入影像產生深度和運動,從而產生4D 資產。



####### #####更多研究細節,可參考原論文。 ######
以上是一行文本,產生3D動態場景:Meta這個「一步到位」模型有點厲害的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















