
近年來,基於 Transformer 的大規模多模態訓練促成了不同領域最新技術的改進,包括視覺、語言和音訊。特別是在電腦視覺和圖像語言理解方面,單一預訓練大模型可以優於特定任務的專家模型。
然而,大型多模態模型通常使用模態或特定於資料集的編碼器和解碼器,並相應地導致涉及的協定。例如,此類模型通常涉及在各自的資料集上對模型的不同部分進行不同階段的訓練,並進行特定於資料集的預處理,或以特定於任務的方式遷移不同部分。這種模式和特定於任務的組件可能會導致額外的工程複雜性,並在引入新的預訓練損失或下游任務時面臨挑戰。
因此,發展一個可以處理任何模態或模態組合的單一端對端模型,將是多模態學習的重要一步。本文中,來自谷歌研究院(Google大腦團隊)、蘇黎世的研究者將主要關注圖像和文字。

#論文網址:https://arxiv.org/pdf/2212.08045.pdf
許多關鍵統一加速了多模式學習的進程。首先證實,Transformer 架構可以作為通用主幹,並且在文字、視覺、音訊和其他領域上表現良好。其次,許多論文探索了將不同的模態映射到單一共享嵌入空間以簡化輸入 / 輸出接口,或開發一個用於多個任務的單一接口。第三,模態的替代表示允許在一個領域中利用另一個領域設計的神經架構或訓練程序。例如,[54] 和 [26,48] 分別表示文字和音頻,透過將這些形式呈現為圖像(在音頻的情況下為頻譜圖)進行處理。
本文將對使用純基於像素的模型進行文字和圖像的多模態學習進行探索。該模型是一個單獨的視覺 Transformer,它處理視覺輸入或文本,或兩者一起,所有都呈現為 RGB 圖像。所有模態都使用相同的模型參數,包括低階特徵處理;也就是說,不存在特定於模態的初始卷積、tokenization 演算法或輸入嵌入表。此模型僅用一個任務訓練:對比學習,如 CLIP 和 ALIGN 所推廣的。因此模型被稱為 CLIP-Pixels Only(CLIPPO)。
在CLIP 設計用於影像分類和文字/ 影像檢索的主要任務上,儘管沒有特定的tower 模態,CLIPPO 的表現也與CLIP 相似(相似度在1- 2% 之內)。令人驚訝的是,CLIPPO 不需要任何從左到右的語言建模、遮罩語言建模或顯式的詞級損失,就可以執行複雜的語言理解任務。特別是在 GLUE 基準測試上,CLIPPO 優於經典的 NLP 基線,如 ELMO BiLSTM attention,此外,CLIPPO 還優於基於像素的掩碼語言模型,並接近 BERT 的分數。
有趣的是,當簡單地將圖像和文字一起渲染時,CLIPPO 也可以在 VQA 上獲得良好的性能,儘管從未在此類資料上進行預訓練。與常規語言模型相比,基於像素的模型的一個直接優勢是不需要預先確定詞彙。因此,與使用經典 tokenizer 的等效模型相比,多語言檢索的效能有所提高。最後,研究還發現,在某些情況下訓練 CLIPPO 時,先前觀察到的模態差距減少。
CLIP 已成為一種強大的、可擴展的範式,用於在資料集上訓練多用途視覺模型。具體來說,這種方法依賴圖像 /alt-text 對,這些可以從網路上大規模自動收集。因此,文字描述通常是有雜訊的,並且可能由單一關鍵字、關鍵字集或潛在的冗長描述組成。利用這些數據,聯合訓練兩個編碼器,即嵌入 alt-text 的文本編碼器和將相應圖像嵌入共享潛在空間的圖像編碼器。這兩個編碼器使用對比損失進行訓練,鼓勵相應圖像和 alt-text 的嵌入相似,同時與所有其他圖像和 alt-text 的嵌入不同。
一旦經過訓練,這樣的編碼器對可以以多種方式使用:它可以透過文字描述對固定的視覺概念集進行分類(零樣本分類); 嵌入可用於檢索給定文字描述的影像,反之亦然;或者,視覺編碼器可以透過對標記的資料集進行微調或透過在凍結的影像編碼器表示上訓練頭部,以有監督的方式傳輸到下游任務。原則上,文字編碼器可以作為一個獨立的文本嵌入使用,不過據悉,還沒有人針對這種應用展開深入探討,一些研究引用了低品質的alt-text 導致文本編碼器的語言建模性能較弱。
先前的工作表明,圖像和文字編碼器可以用一個共享transformer 模型(也稱為單塔模型,或1T-CLIP)實現,其中圖像使用patch embedding 嵌入, tokenized 文字使用單獨的word embedding 嵌入。除了模態特定的嵌入外,兩種模態的所有模型參數都是共享的。雖然這種類型的共享通常會導致圖像 / 圖像 - 語言任務的表現下降,但它也使模型參數的數量減少了一半。
CLIPPO 將此想法更進一步:文字輸入呈現在空白圖像上,隨後完全作為圖像處理,包括初始的 patch embedding(參見圖 1)。透過與先前的工作進行對比訓練,產生了一個單一的視覺transformer 模型,它可以透過單一的視覺介面來理解圖像和文本,並提供了一個可以用於解決圖像、圖像- 語言和純語言理解任務的單一表示。
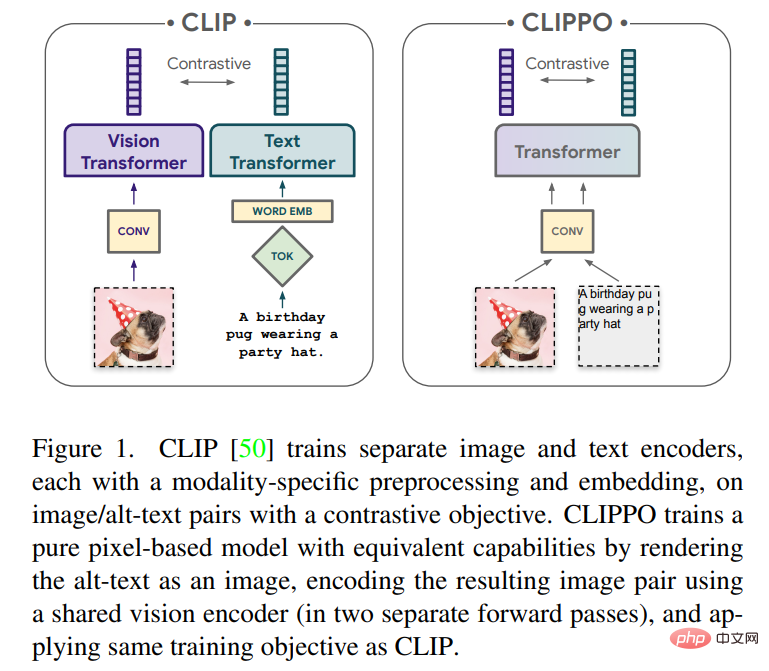
除了多模態多功能性,CLIPPO 還減輕了文本處理的常見困難,即開發適當的 tokenizer 和詞彙表。這在大量多語言設定的上下文中特別有趣,其中文字編碼器必須處理數十種語言。
可以發現,在圖像/alt-text 對上訓練的CLIPPO 在公共圖像和圖像語言基準上的表現與1T-CLIP 相當,並且在GLUE 基準上與強大的基準語言模型競爭。然而,由於 alt-texts 的品質較低,通常不是語法句子,僅從 alt-texts 學習語言理解從根本上是有限的。因此,可以在影像 /alt-texts 對比預訓練中加入基於語言的對比訓練。具體而言,需要考慮到從文本語料庫中採樣的連續句對,不同語言的翻譯句對,後翻譯句對,以及有單字缺失的句子對。
視覺與視覺語言理解
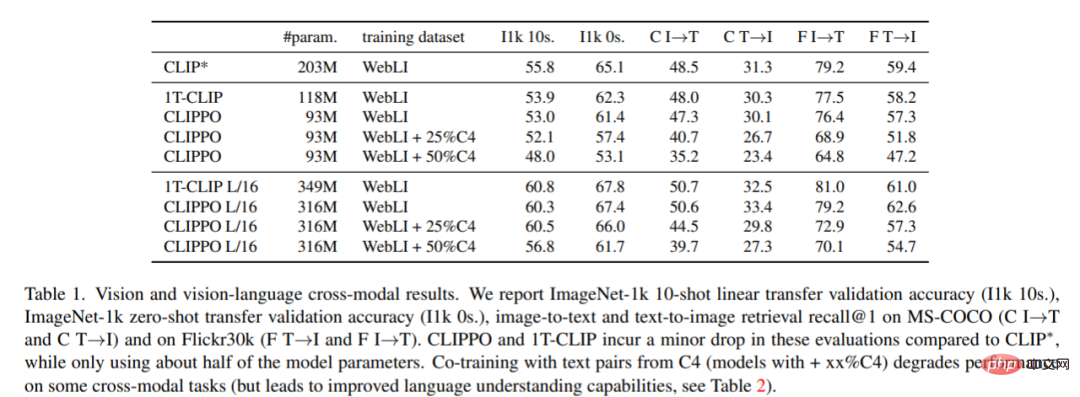
#影像分類與檢索。表 1 顯示了 CLIPPO 的效能,可以看到,與 CLIP∗ 相比,CLIPPO 和 1T-CLIP 產生了 2-3 個百分點的絕對下降。
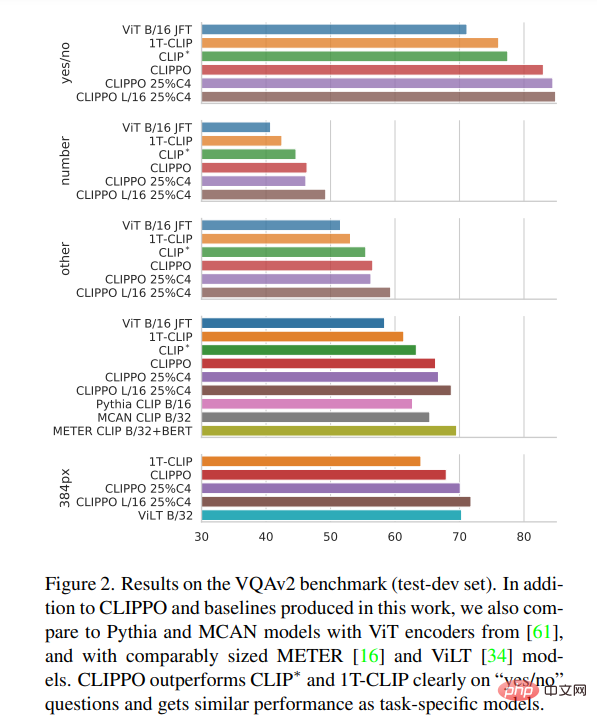
VQA。圖 2 中報告了模型和基線的 VQAv2 評分。可以看到,CLIPPO 優於 CLIP∗ 、1T-CLIP,以及 ViT-B/16,獲得了 66.3 的分數。
多語言視覺- 語言理解
圖3 表明,CLIPPO實現了與這些基線相當的檢索性能。在 mT5 的情況下,使用額外的資料可以提高效能;在多語言上下文中利用這些額外的參數和資料將是 CLIPPO 未來一個有趣的方向。
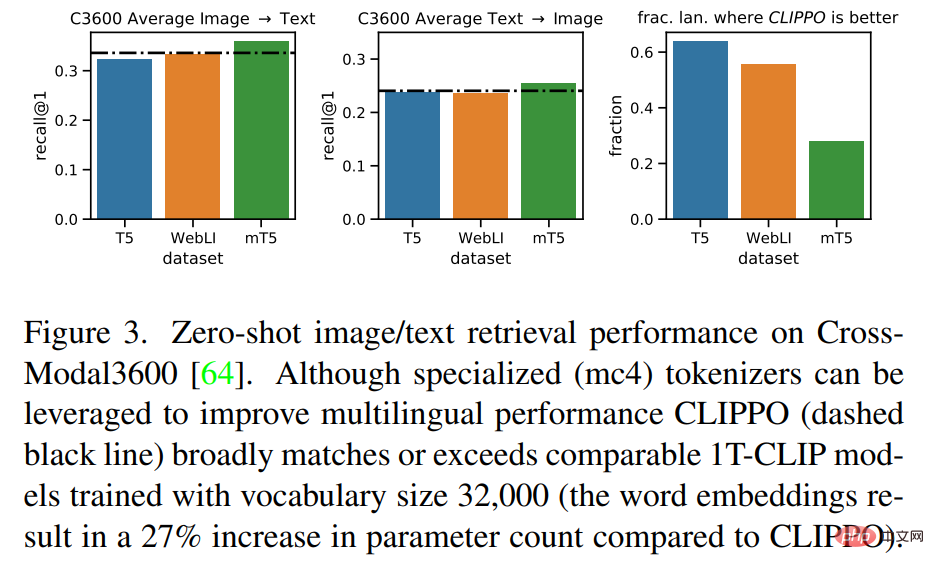
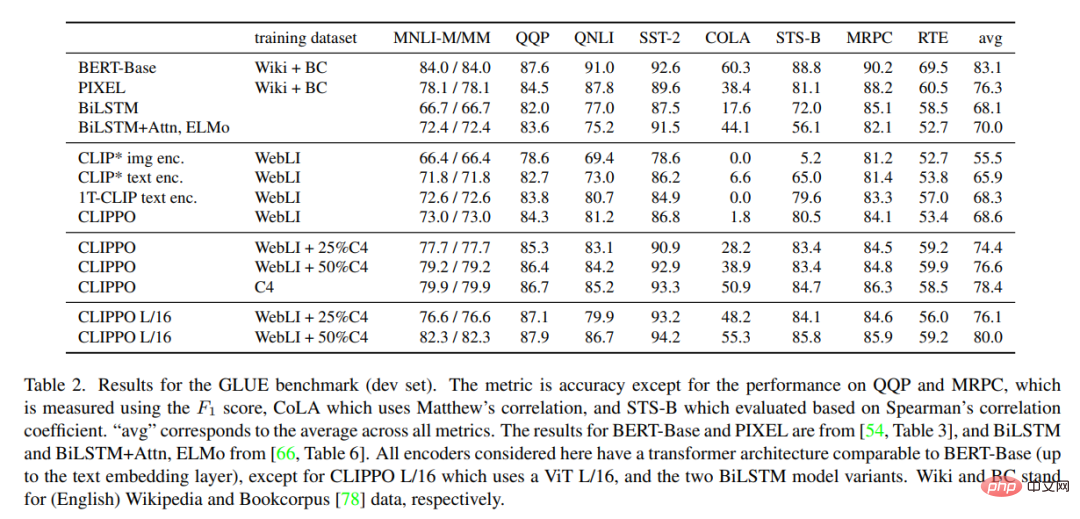
表 2 顯示了 CLIPPO 和基準的 GLUE 基準測試結果。可以觀察到,在 WebLI 上訓練的 CLIPPO 與 BiLSTM Attn ELMo 基線(其具有在大型語言語料庫上訓練的深度詞嵌入)相比具有競爭力。此外,我們還可以看到,CLIPPO 和 1T-CLIP 優於使用標準對比語言視覺預訓練訓練的語言編碼器。
更多研究細節,可參考原文。
以上是參數減半、與CLIP一樣好,視覺Transformer從像素入手實現影像文字統一的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















