

如何使用Python的pandas庫建立多層次索引(MultiIndex)?

引言
pd.MultiIndex,即具有多個層次的索引。透過多層次索引,我們就可以操作整個索引組的資料。本文主要介紹在Pandas中建立多層索引的6種方式:
pd.MultiIndex.from_arrays():多維數組作為參數,高維度指定高層索引,低維指定低層索引。
pd.MultiIndex.from_tuples():元組的清單作為參數,每個元組指定每個索引(高維和低維索引)。
pd.MultiIndex.from_product():可迭代物件的列表作為參數,根據多個可迭代物件元素的笛卡爾積(元素間的兩兩組合)進行創建索引。
pd.MultiIndex.from_frame:根據現有的資料框來直接產生
groupby():透過資料分組統計量得到
pivot_table():產生透視表的方式來得到
pd.MultiIndex.from_arrays()
In [1] :
import pandas as pd import numpy as np
透過陣列的方式來生成,通常指定的是清單中的元素:
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [3]:
type(m1) # 查看数据类型
透過type函數來查看資料類型,發現的確是:MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
在建立的同時可以指定每個層級的名字:
In [4]:
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])下面的範例是產生3個層次的索引且指定名字:
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])pd.MultiIndex.from_tuples()
透過元組的形式來產生多層索引:
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5Out [7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)清單和元組是可以混合使用的
#最外層是列表
- ##裡面全部是元組
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"])
m6MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)使用可迭代物件的列表作為參數,根據多個可迭代物件元素的笛卡爾積(元素間的兩兩組合)進行建立索引。 在Python中,我們使用
isinstance()函數來判斷python物件是否可迭代:
# 导入 collections 模块的 Iterable 对比对象 from collections import Iterable


names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number'])# 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
df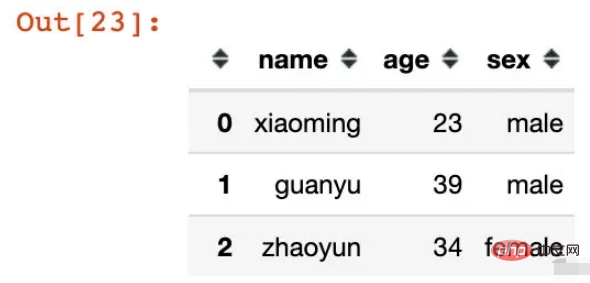
pd.MultiIndex.from_frame(df)
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])# 可以自定义名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1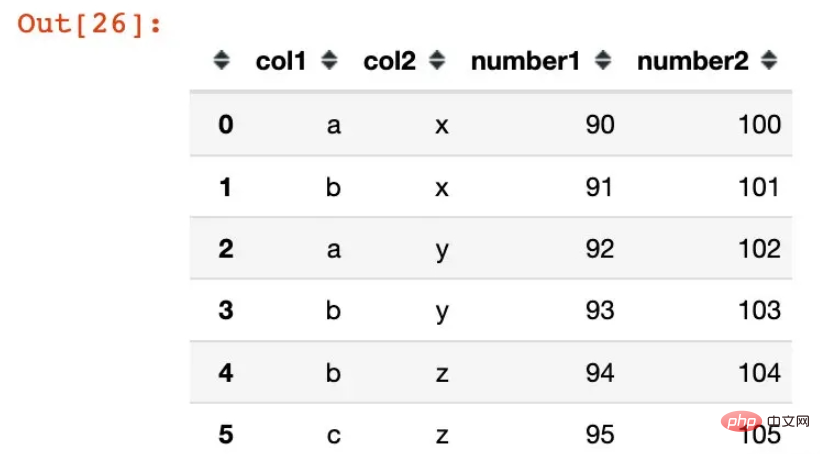
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2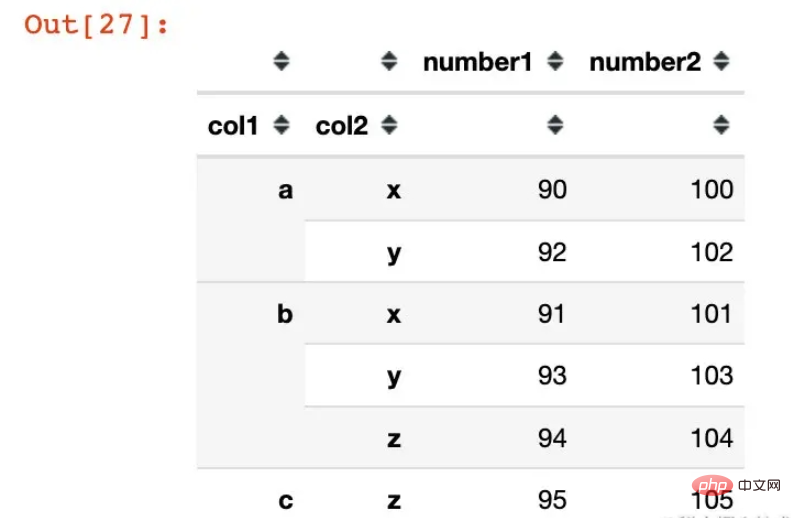
df2.index
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3

df3.index
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])以上是如何使用Python的pandas庫建立多層次索引(MultiIndex)?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
VS Code 擴展存在惡意風險,例如隱藏惡意代碼、利用漏洞、偽裝成合法擴展。識別惡意擴展的方法包括:檢查發布者、閱讀評論、檢查代碼、謹慎安裝。安全措施還包括:安全意識、良好習慣、定期更新和殺毒軟件。
