

Java中常用的序列化方式有哪些?以Kryo、Protostuff和Hessian為例講解它們的實作原理。

前言
前段時間在寫RPC框架的時候用到了Kryo、Hessian、Protostuff三種序列化方式。但當時因為急於實現功能,就只是簡單的看了一下如何使用這三種序列化方式,並沒有去深入研究各自的特性,以及優點和缺點。知道現在就將RPC框架寫完了之後,才有時間靜下心來對三種方式做一個對比,總結。
Kryo、Hessain、Protostuff都是第三方開源的序列化/反序列化框架,要了解各自的特性,我們首先需要知道序列化/反序列化是什麼:
序列化:就是將物件轉換成位元組序列的過程。
反序列化:就是講位元組序列轉換成物件的過程。
seriallization 序列化: 將物件轉換為方便傳輸的格式, 常見的序列化格式:二進位格式,位元組數組,json字串,xml字符串。
deseriallization 反序列化:將序列化的資料恢復為物件的過程
如果對序列化相關概念還不是很清楚的同學可以參考美團技術團隊的序列化與反序列化
效能對比
前期準備
-
我們先建立一個新的Maven專案
然後匯入依賴
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.8.2</version>
<scope>test</scope>
</dependency>
<!-- 代码简化 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--kryo-->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo-shaded</artifactId>
<version>4.0.2</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.10</version>
</dependency>
<!--protostuff-->
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.7.2</version>
</dependency>
<!--hessian2-->
<dependency>
<groupId>com.caucho</groupId>
<artifactId>hessian</artifactId>
<version>4.0.62</version>
</dependency>工具類別:
kryo
package cuit.pymjl.utils;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import org.apache.commons.codec.binary.Base64;
import org.objenesis.strategy.StdInstantiatorStrategy;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.UnsupportedEncodingException;
/**
* @author Pymjl
* @version 1.0
* @date 2022/4/18 20:07
**/
@SuppressWarnings("all")
public class KryoUtils {
private static final String DEFAULT_ENCODING = "UTF-8";
//每个线程的 Kryo 实例
private static final ThreadLocal<Kryo> KRYO_LOCAL = new ThreadLocal<Kryo>() {
@Override
protected Kryo initialValue() {
Kryo kryo = new Kryo();
/**
* 不要轻易改变这里的配置!更改之后,序列化的格式就会发生变化,
* 上线的同时就必须清除 Redis 里的所有缓存,
* 否则那些缓存再回来反序列化的时候,就会报错
*/
//支持对象循环引用(否则会栈溢出)
kryo.setReferences(true); //默认值就是 true,添加此行的目的是为了提醒维护者,不要改变这个配置
//不强制要求注册类(注册行为无法保证多个 JVM 内同一个类的注册编号相同;而且业务系统中大量的 Class 也难以一一注册)
kryo.setRegistrationRequired(false); //默认值就是 false,添加此行的目的是为了提醒维护者,不要改变这个配置
//Fix the NPE bug when deserializing Collections.
((Kryo.DefaultInstantiatorStrategy) kryo.getInstantiatorStrategy())
.setFallbackInstantiatorStrategy(new StdInstantiatorStrategy());
return kryo;
}
};
/**
* 获得当前线程的 Kryo 实例
*
* @return 当前线程的 Kryo 实例
*/
public static Kryo getInstance() {
return KRYO_LOCAL.get();
}
//-----------------------------------------------
// 序列化/反序列化对象,及类型信息
// 序列化的结果里,包含类型的信息
// 反序列化时不再需要提供类型
//-----------------------------------------------
/**
* 将对象【及类型】序列化为字节数组
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字节数组
*/
public static <T> byte[] writeToByteArray(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream);
Kryo kryo = getInstance();
kryo.writeClassAndObject(output, obj);
output.flush();
return byteArrayOutputStream.toByteArray();
}
/**
* 将对象【及类型】序列化为 String
* 利用了 Base64 编码
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字符串
*/
public static <T> String writeToString(T obj) {
try {
return new String(Base64.encodeBase64(writeToByteArray(obj)), DEFAULT_ENCODING);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
/**
* 将字节数组反序列化为原对象
*
* @param byteArray writeToByteArray 方法序列化后的字节数组
* @param <T> 原对象的类型
* @return 原对象
*/
@SuppressWarnings("unchecked")
public static <T> T readFromByteArray(byte[] byteArray) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArray);
Input input = new Input(byteArrayInputStream);
Kryo kryo = getInstance();
return (T) kryo.readClassAndObject(input);
}
/**
* 将 String 反序列化为原对象
* 利用了 Base64 编码
*
* @param str writeToString 方法序列化后的字符串
* @param <T> 原对象的类型
* @return 原对象
*/
public static <T> T readFromString(String str) {
try {
return readFromByteArray(Base64.decodeBase64(str.getBytes(DEFAULT_ENCODING)));
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
//-----------------------------------------------
// 只序列化/反序列化对象
// 序列化的结果里,不包含类型的信息
//-----------------------------------------------
/**
* 将对象序列化为字节数组
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字节数组
*/
public static <T> byte[] writeObjectToByteArray(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream);
Kryo kryo = getInstance();
kryo.writeObject(output, obj);
output.flush();
return byteArrayOutputStream.toByteArray();
}
/**
* 将对象序列化为 String
* 利用了 Base64 编码
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字符串
*/
public static <T> String writeObjectToString(T obj) {
try {
return new String(Base64.encodeBase64(writeObjectToByteArray(obj)), DEFAULT_ENCODING);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
/**
* 将字节数组反序列化为原对象
*
* @param byteArray writeToByteArray 方法序列化后的字节数组
* @param clazz 原对象的 Class
* @param <T> 原对象的类型
* @return 原对象
*/
@SuppressWarnings("unchecked")
public static <T> T readObjectFromByteArray(byte[] byteArray, Class<T> clazz) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArray);
Input input = new Input(byteArrayInputStream);
Kryo kryo = getInstance();
return kryo.readObject(input, clazz);
}
/**
* 将 String 反序列化为原对象
* 利用了 Base64 编码
*
* @param str writeToString 方法序列化后的字符串
* @param clazz 原对象的 Class
* @param <T> 原对象的类型
* @return 原对象
*/
public static <T> T readObjectFromString(String str, Class<T> clazz) {
try {
return readObjectFromByteArray(Base64.decodeBase64(str.getBytes(DEFAULT_ENCODING)), clazz);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
}Hessian
package cuit.pymjl.utils;
import com.caucho.hessian.io.Hessian2Input;
import com.caucho.hessian.io.Hessian2Output;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* @author Pymjl
* @version 1.0
* @date 2022/7/2 12:39
**/
public class HessianUtils {
/**
* 序列化
*
* @param obj obj
* @return {@code byte[]}
*/
public static byte[] serialize(Object obj) {
Hessian2Output ho = null;
ByteArrayOutputStream baos = null;
try {
baos = new ByteArrayOutputStream();
ho = new Hessian2Output(baos);
ho.writeObject(obj);
ho.flush();
return baos.toByteArray();
} catch (Exception ex) {
ex.printStackTrace();
throw new RuntimeException("serialize failed");
} finally {
if (null != ho) {
try {
ho.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != baos) {
try {
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 反序列化
*
* @param bytes 字节
* @param clazz clazz
* @return {@code T}
*/
public static <T> T deserialize(byte[] bytes, Class<T> clazz) {
Hessian2Input hi = null;
ByteArrayInputStream bais = null;
try {
bais = new ByteArrayInputStream(bytes);
hi = new Hessian2Input(bais);
Object o = hi.readObject();
return clazz.cast(o);
} catch (Exception ex) {
throw new RuntimeException("deserialize failed");
} finally {
if (null != hi) {
try {
hi.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != bais) {
try {
bais.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}Protostuff
package cuit.pymjl.utils;
import io.protostuff.LinkedBuffer;
import io.protostuff.ProtostuffIOUtil;
import io.protostuff.Schema;
import io.protostuff.runtime.RuntimeSchema;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author Pymjl
* @version 1.0
* @date 2022/6/28 21:00
**/
public class ProtostuffUtils {
/**
* 避免每次序列化都重新申请Buffer空间
* 这个字段表示,申请一个内存空间用户缓存,LinkedBuffer.DEFAULT_BUFFER_SIZE表示申请了默认大小的空间512个字节,
* 我们也可以使用MIN_BUFFER_SIZE,表示256个字节。
*/
private static final LinkedBuffer BUFFER = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
/**
* 缓存Schema
* 这个字段表示缓存的Schema。那这个Schema是什么呢?就是一个组织结构,就好比是数据库中的表、视图等等这样的组织机构,
* 在这里表示的就是序列化对象的结构。
*/
private static final Map<Class<?>, Schema<?>> SCHEMA_CACHE = new ConcurrentHashMap<>();
/**
* 序列化方法,把指定对象序列化成字节数组
*
* @param obj 对象
* @return byte[]
*/
@SuppressWarnings("unchecked")
public static <T> byte[] serialize(T obj) {
Class<T> clazz = (Class<T>) obj.getClass();
Schema<T> schema = getSchema(clazz);
byte[] data;
try {
data = ProtostuffIOUtil.toByteArray(obj, schema, BUFFER);
} finally {
BUFFER.clear();
}
return data;
}
/**
* 反序列化方法,将字节数组反序列化成指定Class类型
*
* @param data 字节数组
* @param clazz 字节码
* @return
*/
public static <T> T deserialize(byte[] data, Class<T> clazz) {
Schema<T> schema = getSchema(clazz);
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(data, obj, schema);
return obj;
}
@SuppressWarnings("unchecked")
private static <T> Schema<T> getSchema(Class<T> clazz) {
Schema<T> schema = (Schema<T>) SCHEMA_CACHE.get(clazz);
if (schema == null) {
schema = RuntimeSchema.getSchema(clazz);
if (schema == null) {
SCHEMA_CACHE.put(clazz, schema);
}
}
return schema;
}
}建立一個實體類別進行測試:
package cuit.pymjl.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serial;
import java.io.Serializable;
/**
* @author Pymjl
* @version 1.0
* @date 2022/7/2 12:32
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements Serializable {
@Serial
private static final long serialVersionUID = -91809837793898L;
private String name;
private String password;
private int age;
private String address;
private String phone;
}序列化後位元組所佔空間大小比較
編寫測試類別:
public class MainTest {
@Test
void testLength() {
Student student = new Student("pymjl", "123456", 18, "北京", "123456789");
int kryoLength = KryoUtils.writeObjectToByteArray(student).length;
int hessianLength = HessianUtils.serialize(student).length;
int protostuffLength = ProtostuffUtils.serialize(student).length;
System.out.println("kryoLength: " + kryoLength);
System.out.println("hessianLength: " + hessianLength);
System.out.println("protostuffLength: " + protostuffLength);
}
}運行截圖:
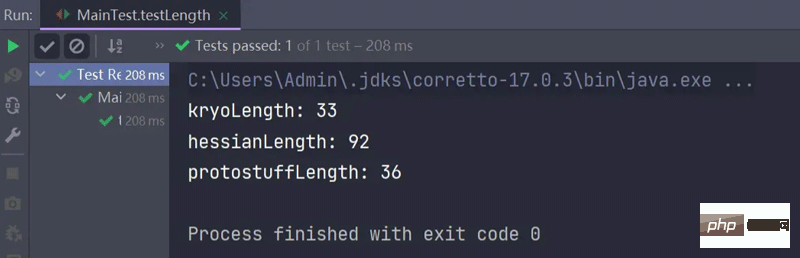
由圖可知,Hessian序列化後位元組所佔的空間都顯著比其他兩種方式要大得多
其他比較
Hessian使用固定長度儲存int和long,而kryo使用變長的int和long保證這種基本資料型別序列化後盡量小,實際應用中,很大的資料不會經常出現。
Kryo進行序列化的時候,需要傳入完整類別名稱或利用register() 提前將類別註冊到Kryo上,其類別與一個int型的ID相關聯,序列中只存放這個ID,因此序列體積就更小,而Hessian則是將所有類別字段資訊都放入序列化位元組數組中,直接利用位元組數組進行反序列化,不需要其他參與,因為存的東西多處理速度就會慢點
Kryo使用不需要實作Serializable接口,Hessian則需實作
- ##Kryo資料類的欄位增、減,序列化和反序列化時無法兼容,而Hessian則兼容,Protostuff是只能在末尾添加新字段才兼容
Kryo和Hessian使用涉及到的資料類別中必須擁有無參構函數
- Hessian會把複雜物件的所有屬性儲存在一個Map中進行序列化。所以在父類、子類存在同名成員變數的情況下,Hessian序列化時,先序列化子類,然後序列化父類,因此反序列化結果會導致子類同名成員變數被父類的值覆蓋
- Kryo不是線程安全的,要透過ThreadLocal或建立Kryo執行緒池來確保線程安全,而Protostuff則是線程安全的
- Protostuff和Kryo序列化的格式有相似之處,都是利用一個標記來記錄字段類型,因此序列化出來體積都比較小
| 優點 | #缺點 | |
|---|---|---|
| 速度快,序列化後體積小 | 跨語言支援較複雜 | |
| 預設支援跨語言 | 較慢 | |
| 速度快,基於protobuf | 需靜態編譯 | |
| 無靜態編譯,但序列化前需預先傳入schema | 不支援無預設建構函數的類,反序列化時需使用者自行初始化序列化後的對象,其只負責將該物件賦值 | |
| 使用方便,可序列化所有類別 | 速度慢,佔空間 |
以上是Java中常用的序列化方式有哪些?以Kryo、Protostuff和Hessian為例講解它們的實作原理。的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
膠囊是一種三維幾何圖形,由一個圓柱體和兩端各一個半球體組成。膠囊的體積可以通過將圓柱體的體積和兩端半球體的體積相加來計算。本教程將討論如何使用不同的方法在Java中計算給定膠囊的體積。 膠囊體積公式 膠囊體積的公式如下: 膠囊體積 = 圓柱體體積 兩個半球體體積 其中, r: 半球體的半徑。 h: 圓柱體的高度(不包括半球體)。 例子 1 輸入 半徑 = 5 單位 高度 = 10 單位 輸出 體積 = 1570.8 立方單位 解釋 使用公式計算體積: 體積 = π × r2 × h (4
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 創造未來:零基礎的 Java 編程
Oct 13, 2024 pm 01:32 PM
創造未來:零基礎的 Java 編程
Oct 13, 2024 pm 01:32 PM
Java是熱門程式語言,適合初學者和經驗豐富的開發者學習。本教學從基礎概念出發,逐步深入解說進階主題。安裝Java開發工具包後,可透過建立簡單的「Hello,World!」程式來實踐程式設計。理解程式碼後,使用命令提示字元編譯並執行程序,控制台上將輸出「Hello,World!」。學習Java開啟了程式設計之旅,隨著掌握程度加深,可創建更複雜的應用程式。
 PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP成為許多網站首選技術棧的原因包括其易用性、強大社區支持和廣泛應用。 1)易於學習和使用,適合初學者。 2)擁有龐大的開發者社區,資源豐富。 3)廣泛應用於WordPress、Drupal等平台。 4)與Web服務器緊密集成,簡化開發部署。
