

意思?請提供更多上下文。

1 進程總覽
進程是對邏輯的抽象,我們從作業系統的書籍中對進程有了很多的認識,但是對進程的實現可能不太了解,這篇文章試著解釋一下關於進程實現的大致原理。
進程的實現,其實和我們平常寫程式碼的時候一樣,例如我們要表示一個東西,我們會定義一個資料結構。進程也不例外。所以進程的本質就是一個資料結構,他保存了一系列的資料。作業系統以數組或鍊錶的形式和全部的進程管理起來。進程可以說分為兩種
1 系統初始化時第一個進程,
2 除了第一個進程外的其他進程,他們都是由fork或fork execute系統呼叫創建出來的。
我們先來看看進程的結構體都有什麼資訊。
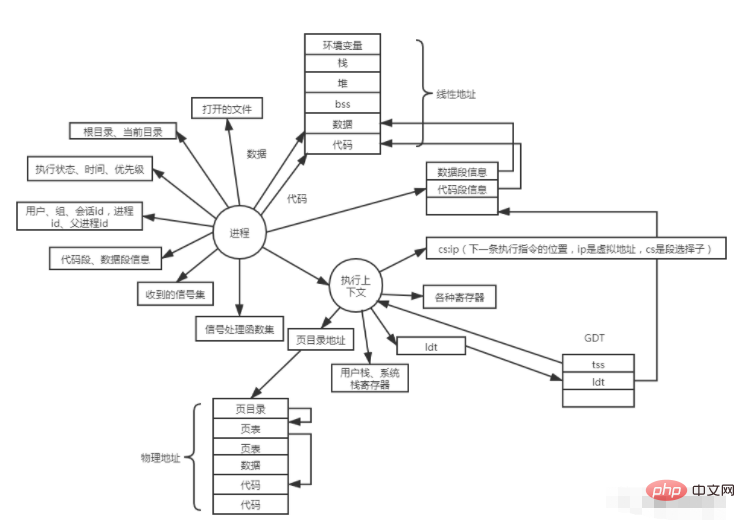
以上就是表示進程的結構體中主要的資訊。那麼一個結構體就是表示一個流程。我們知道fork是以父進程為模組,複製一份父進程的結構體,然後修改某些欄位。就變成了一個新的進程。如果呼叫execute的話,就是進一步修改複製出來的結構體中的欄位(例如頁表、程式碼片段、資料段)。並且從硬碟載入相應的資料到記憶體。那麼第一個進程是如何產生的呢?因為進程只是一個結構體,所以如果我們預先定義了一個結構體,那就可以不透過fork的形式來創建一個進程了。
2 進程的執行
當系統建立一個行程之後,會設定cs:ip暫存器的值,如果是fork,則ip就是fork函數後面的語句的ip位址。如果是execute則ip位址由編譯器指定。不管怎樣,當行程開始執行的時候,cpu就會解析cs:ip拿到一條指令去執行。那麼cs:ip是如何被解析的呢?
執行進程的時候,tss選擇子(GDT索引)被載入到tss暫存器,然後把tss裡的上下文也載入到對應的暫存器,例如cr3,ldt選擇子。根據tss資訊中的ldt索引首先從GDT找到進程ldt結構體資料的首地址,然後根據當前段的屬性,例如代碼段,則從cs中取得選擇子,系統從ldt表中取得進程線性空間的首地址、限長、權限等資訊。用線性位址的首位址加上ip中的偏移,得到線性位址,然後再透過頁目錄和頁表得到實體位址,物理位址還沒有分配則進行缺頁異常等處理。
3 進程的暫停與喚醒
進程的掛起、阻斷、多進程。這些概念我們平常聽得比較多,現在我們來看看他是實現是怎樣的。進程的掛起,或者說阻塞分為兩種。
1 主動掛起。透過sleep讓進程間歇性掛起。 sleep的原理之前有分析過,就不再分析。大概的原理
就是設定一個定時器,到期後喚醒進程。
修改行程為掛起狀態,等待喚醒。
2 被動掛起。
被動掛起的場景比較多,主要是行程申請一個資源,但是資源沒有滿足條件,則行程被作業系統掛起。比如我們讀一個管道的時候。管道沒有資料可讀,則進程被掛起。插入到管道的等待隊列。
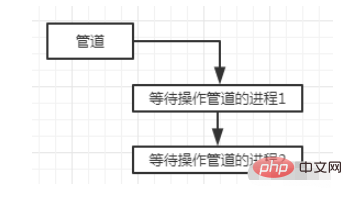
當管道有內容寫入的時候,流程就會被喚醒。進程被掛起(分為可被訊號喚醒和不能被訊號喚醒兩種)和喚醒的實現。
<code>// 当前进程挂载到睡眠队列p中,p指向队列头指针的地址<br>void sleep_on(struct task_struct **p)<br>{<br> struct task_struct *tmp;<br><br> if (!p)<br> return;<br> if (current == &(init_task.task))<br> panic("task[0] trying to sleep");<br> /*<br> *p为第一个睡眠节点的地址,即tmp指向第一个睡眠节点<br> 头指针指向当前进程,这个版本的实现没有采用真正链表的形式,<br> 他通过每个进程在栈中的临时变量形成一个链表,每个睡眠的进程,<br> 在栈里有一个变量指向后面一个睡眠节点,然后把链表的头指针指向当前进程,<br> 然后切换到其他进程执行,当被wake_up唤醒的时候,wake_up会唤醒链表的第一个<br> 睡眠节点,因为第一个节点里保存了后面一个节点的地址,所以他唤醒后面一个节点,<br> 后面一个节点以此类推,从而把整个链表的节点唤醒,这里的实现类似nginx的filter,<br> 即每个模块保存后面一个节点的地址,然后把全局指针指向自己。<br> */<br> tmp = *p;<br> *p = current;<br> // 不可中断睡眠只能通过wake_up唤醒,即使有信号也无法唤醒<br> current->state = TASK_UNINTERRUPTIBLE;<br> // 进程调度<br> schedule();<br> // 唤醒后面一个节点<br> if (tmp)<br> tmp->state=0;<br>}<br><br>// 唤醒队列中的第一个节点,并清空链表,因为第一个节点会向后唤醒其他节点<br>void wake_up(struct task_struct **p)<br>{<br> if (p && *p) {<br> (**p).state=0;<br> *p=NULL;<br> }<br>}</code>我們發現,進程的實現,跟我們平時寫程式碼差不多,就是定義資料結構,然後實作操作資料結構的演算法。當然,因為涉及硬體底層,作業系統的實作比我們的程式碼複雜得多。
以上是意思?請提供更多上下文。的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHPhassignificantlyimpactedwebdevelopmentandextendsbeyondit.1)ItpowersmajorplatformslikeWordPressandexcelsindatabaseinteractions.2)PHP'sadaptabilityallowsittoscaleforlargeapplicationsusingframeworkslikeLaravel.3)Beyondweb,PHPisusedincommand-linescrip
 PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP成為許多網站首選技術棧的原因包括其易用性、強大社區支持和廣泛應用。 1)易於學習和使用,適合初學者。 2)擁有龐大的開發者社區,資源豐富。 3)廣泛應用於WordPress、Drupal等平台。 4)與Web服務器緊密集成,簡化開發部署。
 PHP與Python:用例和應用程序
Apr 17, 2025 am 12:23 AM
PHP與Python:用例和應用程序
Apr 17, 2025 am 12:23 AM
PHP適用於Web開發和內容管理系統,Python適合數據科學、機器學習和自動化腳本。 1.PHP在構建快速、可擴展的網站和應用程序方面表現出色,常用於WordPress等CMS。 2.Python在數據科學和機器學習領域表現卓越,擁有豐富的庫如NumPy和TensorFlow。
