

一份Google內部文件外洩顯示,Google和OpenAI都缺乏有效的保護機制,因此大型模式的門檻正被開源社群不斷降低。

「我們沒有護城河,OpenAI 也沒有。」在最近洩漏的一份文件中,一位谷歌內部的研究人員表達了這樣的觀點。
這位研究人員認為,雖然表面看起來OpenAI 和谷歌在AI 大模型上你追我趕,但真正的贏家未必會從這兩家中產生,因為一個第三方力量正悄悄崛起。
這個力量叫做「開源」。圍繞著Meta 的LLaMA 等開源模型,整個社區正在迅速構建與OpenAI、谷歌大模型能力類似的模型,而且開源模型的迭代速度更快,可定制性更強,更有私密性……“當免費的、不受限制的替代品品質相當時,人們不會為受限制的模型付費。」作者寫道。
這份文件最初由一位匿名人士在公共 Discord 伺服器上分享,獲得轉載授權的產業媒體 SemiAnalysis 表示,他們已經驗證了這份文件的真實性。
這篇文章在推特等社群平台上得到了大量轉發。其中,德州大學奧斯汀分校教授Alex Dimakis 發表瞭如下觀點:
- #開源AI 正在取得勝利,我同意,對於全世界來說,這是件好事,對於建構一個有競爭力的生態系統來說也是好事。雖然在 LLM 領域,我們還沒有做到這一點,但我們剛剛讓 OpenClip 擊敗了 openAI Clip,並且 Stable Diffusion 比封閉模型更好。
- 你不需要龐大的模型,高品質的數據更有效、更重要,API 背後的羊駝模型進一步削弱了護城河。
- 你可以從一個好的基礎模型和參數高效微調(PEFT)演算法開始,例如 Lora 在一天內就能運行得非常好。演算法創新終於開始了!
- 大學和開源社群應該組織更多的工作來管理資料集,訓練基礎模型,並像 Stable Diffusion 一樣建立微調社群。
當然,並非所有研究者都同意文章中的觀點。有人對開源模型是否真能擁有媲美 OpenAI 的大模型的能力和通用性持懷疑態度。
不過,對於學術界來說,開源力量的崛起總歸是件好事,意味著即使沒有1000 塊GPU,研究者也依然有事可做。
以下是檔案原文:
Google、OpenAI 都沒有護城河
我們沒有護城河,OpenAI 也沒有。
我們一直在關注 OpenAI 的動態和發展。誰將跨越下一個里程碑?下一步會是什麼?
但令人不安的事實是,我們沒有能力贏得這場軍備競賽,OpenAI 也是如此。在我們爭吵不休的時候,第三個派別一直在漁翁得利。
這個派別就是「開源派」。坦白說,他們正在超越我們。我們所認為的那些「重要的待解決問題」如今已經被解決了,而且已經送到了人們的手中。
我舉幾個例子:
#- 能在手機上運行的大型語言模型:人們可以在 Pixel 6 上運行基礎模型,速度為 5 tokens / 秒。
- 可擴展的個人 AI:你可以花一個晚上在你的筆記型電腦上微調一個個人化的 AI。
- 負責任的發布:這個問題與其說是「被解決了」,不如說是「被忽略了」。有的網站整體都是沒有任何限制的藝術模型,而文字也不例外。
- 多模態:目前的多模態科學 QA SOTA 是在一個小時內訓練完成的。
雖然我們的模型在品質方面仍然保持著輕微的優勢,但差距正在以驚人的速度縮小。開源模型的速度更快,可自訂性更強,更有私密性,而且在同等條件下能力更強大。他們正在用 100 美元和 130 億的參數做一些事情,而我們在 1000 萬美元和 540 億的參數上卻很難做到。而且他們在幾週內就能做到,而不是幾個月。這對我們有深遠的影響:
- 我們沒有秘密武器。我們最大的希望是向谷歌以外的其他人學習並與他們合作。我們應該優先考慮實現 3P 整合。
- 當免費的、不受限制的替代品質相當時,人們不會為受限制的模型付費。我們應該考慮我們的附加價值到底在哪裡。
- 巨大的模型拖慢了我們的速度。從長遠來看,最好的模型是那些可以快速迭代的模型。既然我們知道 200 億以下參數的模型能做什麼,那我們應該在一開始就把它們做出來。
LLaMA 掀起的開源變革
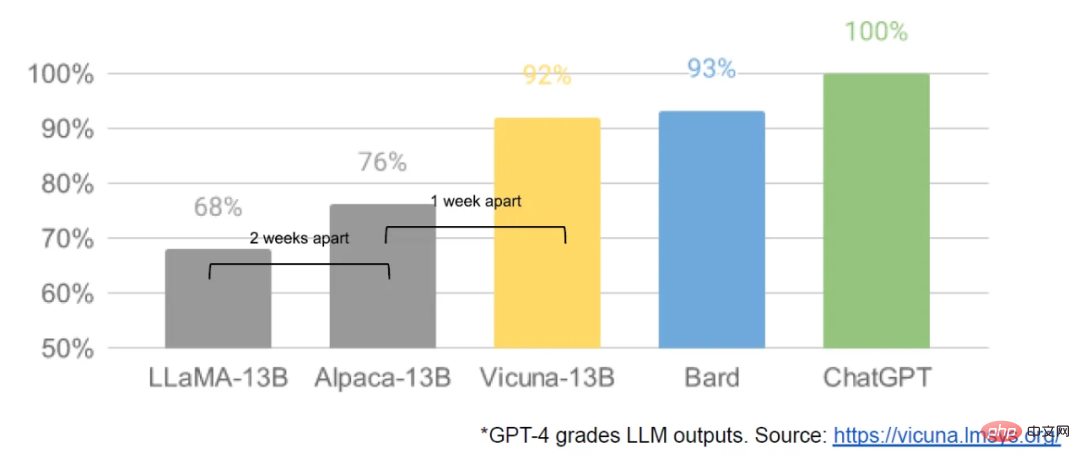
三月初,隨著Meta 的LLaMA 模型被洩漏給公眾,開源社群得到了第一個真正有用的基礎模型。該模型沒有指令或對話調整,也沒有 RLHF。儘管如此,開源社群立即掌握住了 LLaMA 的重要性。
隨之而來的是源源不絕的創新,主要進展出現的間隔只有幾天(如在樹莓派4B 上運行LLaMA 模型、在筆記本上對LLaMA 指令微調、在MacBook 上跑LLaMA 等)。僅僅一個月之後, 指令微調、量化、品質改進、多模態、RLHF 等變體都出現了,其中許多都是在彼此的基礎上建構的。
最重要的是,他們已經解決了規模化問題,這意味著任何人都可以自由地修改和最佳化這個模型。很多新想法都出自普通人。訓練和實驗門檻已經從主要研究機構下放到一個人、一個晚上和一台功能強大的筆記型電腦。
LLM 的 Stable Diffusion 時刻
從很多方面來說,任何人都不應該對此感到驚訝。開源 LLM 目前的復興緊接著影像生成的復興出現,許多人稱這是 LLM 的 Stable Diffusion 時刻。
在這兩種情況下,低成本的公眾參與是透過一種成本低得多的低秩適應(low rank adaptation, LoRA)微調機制實現的,並結合了scale 上的重大突破。高品質模型的易得幫助世界各地的個人和機構孕育了一系列想法,並讓他們得以迭代想法,並很快超過了大型企業。
這些貢獻在影像生成領域至關重要,使 Stable Diffusion 走上了與 Dall-E 不同的道路。擁有一個開放的模型促成了 Dall-E 沒有出現的產品整合、市場、使用者介面和創新。
效果是顯而易見的:與 OpenAI 解決方案相比,Stable Diffusion 的文化影響迅速佔據主導地位。 LLM 是否會出現類似的發展趨勢還有待觀察,但廣泛的結構要素是相同的。
Google錯過了什麼?
開源專案使用的創新方法或技術直接解決了我們仍在努力應對的問題。專注於開源工作可以幫助我們避免重蹈覆轍。其中,LoRA 是功能極其強大的技術,我們應該對其投入更多的關注。
LoRA 將模型的更新展現為低秩因式分解,能夠使更新矩陣的大小縮減數千倍。如此一來,模型的微調只需要很小的成本和時間。將在消費級硬體上對語言模型進行個人化調整的時間縮減至幾個小時非常重要,尤其是對於那些希望在近乎即時的情況下整合新的、多樣化知識的願景而言。雖然該技術對我們想要完成的一些項目有很大影響,但它並未在谷歌內部得到充分的利用。
LoRA 的神奇力量
LoRA 如此高效的一個原因是:就像其他形式的微調一樣,它可以堆疊。我們可以應用指令微調等改進,幫助完成對話、推理等任務。雖然單一微調是低秩的,當它們的總和並不是,LoRA 允許對模型的全等級更新隨著時間的推移累積起來。
這意味著,隨著更新更好資料集和測試的出現,模型可以低成本地保持更新,而不需要支付完整的運行成本。
相較之下,從頭開始訓練大模型不僅丟掉了預訓練,還丟掉了之前進行的所有迭代和改進。在開源世界中,這些改進很快就會盛行起來,這讓全面重新訓練的成本變得非常高。
我們應該認真考慮,每個新應用或想法是否真的需要一個全新的模型。如果我們真的有重大的架構改進,排除了直接重用模型權重,那麼我們應該致力於更積極的蒸餾方式,盡可能保留前一代功能。
大模型 vs. 小模型,誰比較有競爭力?
對於最受歡迎的型號尺寸,LoRA 更新的成本非常低(約 100 美元)。這意味著,幾乎任何有想法的人都可以產生並分發它。在訓練時間小於一天的正常速度下,微調的累積效應很快就可以克服開始時的尺寸劣勢。事實上,就工程師時間而言,這些模型的改進速度遠遠超過了我們的最大變體所能做到的。而最好的模型在很大程度上已經與 ChatGPT 基本沒有區別了。因此,專注於維護一些最大的模型實際上使我們處於不利地位。
資料品質優於資料大小
這些專案中有許多是透過在小型、高度策劃的資料集上進行訓練來節省時間。這顯示在資料縮放規律中較為靈活。這種資料集的存在源自於《資料並非你所想(Data Doesn't Do What You Think)》中的想法,並且正迅速成為無需谷歌的標準訓練方式。這些資料集是使用合成方法(例如從現有的模型中濾出最好的反映)以及從其他項目中搜尋出來的,這但兩種方法在Google並不常用。幸運的是,這些高品質的資料集是開源的,所以它們可以免費使用。
與開源競爭注定失敗
最近的這項進展對商業策略有非常直接的影響。如果有一個沒有使用限制的免費、高品質的替代品,誰會為有使用限制的Google產品買單?況且,我們不該指望能夠追趕上。現代互聯網在開放原始碼上運行,是因為開放原始碼有一些我們無法複製的顯著優勢。
「我們需要他們」多於「他們需要我們」
什麼保守我們的技術機密始終是一個脆弱的命題。谷歌研究人員正定期前往其他公司學習,這樣可以假設他們知道我們所知道的一切。並且只要這種 pipeline 開放,他們就會繼續這樣做。
但由於 LLMs 領域的尖端研究可以負擔得起,因此保持技術競爭優勢變得越來越難了。世界各地的研究機構都在相互借鑒,以廣度優先的方式探索解決方案空間,這遠遠超出了我們自身的能力。我們可以努力抓住自己的秘密,但外部創新會稀釋它們的價值,因此可以嘗試相互學習。
個人不像企業那樣受到許可證的限制
多數創新建構在 Meta 洩漏的模型權重之上。隨著真正開放的模型變得越來越好,這將不可避免發生變化,但關鍵是他們不必等待。 「個人使用」提供的法律保護和不切實際的個人起訴意味著個人可以在這些技術炙手可熱的時候使用它們。
擁有生態系統:讓開源工作為自己所用
矛盾的是,所有這一切只有一個贏家,那就是 Meta,畢竟洩漏的模型是他們的。由於大多數開源創新是基於他們的架構, 因此沒有什麼可以阻止他們直接整合到自家的產品中。
可以看到,擁有生態系統的價值再怎麼強調都不為過。谷歌本身已經在 Chrome 和 Android 等開源產品中使用這種範式。透過孵化創新工作的平台,Google鞏固了自己思想領導者和方向制定者的地位,獲得了塑造比自身更宏大思想的能力。
我們對模型的控制越嚴格,做出開放替代方案的吸引力就越大,Google和OpenAI 都傾向於防禦性的發布模式,使得他們可以嚴格地控制模型使用方式。但是,這種控制是不切實際的。任何想要將 LLMs 用於未經批准目的的人都可以選擇免費提供的模型。
因此, 谷歌應該讓自己成為開源社群的領導者,透過更廣泛的對話合作而不是忽視來起到帶頭作用。這可能意味著採取一些不舒服的舉措,例如發布小型 ULM 變體的模型權重。這也必然意味著放棄對自身模型的一些控制,但這種妥協不可避免。我們不能既希望推動創新又要控制它。
OpenAI 未來的路在何方?
考慮到 OpenAI 目前的封閉政策,所有這些開源討論都會令人覺得不公平。如果他們都不願意公開技術,我們為什麼要分享呢?但事實是,我們透過源源不絕地挖角 OpenAI 的高級研究員,已經與他們分享著一切。在我們阻止這一潮流之前,保密仍是一個有爭議的問題。
最後要說的是,OpenAI 並不重要。他們在開源立場上犯了與我們一樣的錯誤,他們保持優勢的能力必然遭到質疑。除非 OpenAI 改變立場,否則開源替代產品能夠並最終會讓他們傲然失色。至少在這方面,我們可以踏出這一步。
以上是一份Google內部文件外洩顯示,Google和OpenAI都缺乏有效的保護機制,因此大型模式的門檻正被開源社群不斷降低。的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,刪除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段時,需指定位置以優化查詢性能和數據結構;刪除字段前需確認操作不可逆;使用在線DDL、備份數據、測試環境和低負載時間段修改表結構是性能優化和最佳實踐。
 量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
交易所內置量化工具包括:1. Binance(幣安):提供Binance Futures量化模塊,低手續費,支持AI輔助交易。 2. OKX(歐易):支持多賬戶管理和智能訂單路由,提供機構級風控。獨立量化策略平台有:3. 3Commas:拖拽式策略生成器,適用於多平台對沖套利。 4. Quadency:專業級算法策略庫,支持自定義風險閾值。 5. Pionex:內置16 預設策略,低交易手續費。垂直領域工具包括:6. Cryptohopper:雲端量化平台,支持150 技術指標。 7. Bitsgap:
 MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入数据的高效方法包括:1.使用INSERTINTO...VALUES语法,2.利用LOADDATAINFILE命令,3.使用事务处理,4.调整批量大小,5.禁用索引,6.使用INSERTIGNORE或INSERT...ONDUPLICATEKEYUPDATE,这些方法能显著提升数据库操作效率。
 deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
如何實現鼠標滾動事件穿透效果?在我們瀏覽網頁時,經常會遇到一些特別的交互設計。比如在deepseek官網上,�...
 如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
MySQL函數可用於數據處理和計算。 1.基本用法包括字符串處理、日期計算和數學運算。 2.高級用法涉及結合多個函數實現複雜操作。 3.性能優化需避免在WHERE子句中使用函數,並使用GROUPBY和臨時表。
 數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10分別是:1. Binance,2. OKX,3. Coinbase,4. Kraken,5. Huobi Global,6. Bitfinex,7. KuCoin,8. Gemini,9. Bitstamp,10. Bittrex,這些平台均提供高安全性和多種交易選項,適用於不同用戶需求。
 輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
這種開創性的開發將使金融機構能夠利用全球認可的ISO20022標準來自動化不同區塊鏈生態系統的銀行業務流程。 Ease協議是一個企業級區塊鏈平台,旨在通過易用的方式促進廣泛採用,今日宣布已成功集成ISO20022消息傳遞標準,直接將其納入區塊鏈智能合約。這一開發將使金融機構能夠使用全球認可的ISO20022標準,輕鬆自動化不同區塊鏈生態系統的銀行業務流程,該標準正在取代Swift消息傳遞系統。這些功能將很快在“EaseTestnet”上進行試用。 EaseProtocolArchitectDou
 如何分析MySQL查詢的執行計劃
Apr 29, 2025 pm 04:12 PM
如何分析MySQL查詢的執行計劃
Apr 29, 2025 pm 04:12 PM
使用EXPLAIN命令可以分析MySQL查詢的執行計劃。 1.EXPLAIN命令顯示查詢的執行計劃,幫助找出性能瓶頸。 2.執行計劃包括id、select_type、table、type、possible_keys、key、key_len、ref、rows和Extra等字段。 3.根據執行計劃,可以通過添加索引、避免全表掃描、優化JOIN操作和使用覆蓋索引來優化查詢。
