

YOLOv6又快又準的目標偵測框架已經開源了

作者:楚怡、凱衡等
近日,美團視覺智能部研發了一款致力於工業應用的目標偵測架構 YOLOv6,能夠同時專注於偵測的精確度與推理效率。在研發過程中,視覺智能部不斷進行了探索和優化,同時吸取借鑒了學術界和工業界的一些前沿進展和科研成果。在目標偵測權威資料集 COCO 上的實驗結果顯示,YOLOv6 在偵測精度和速度方面均超越其他同體量的演算法,同時支援多種不同平台的部署,極大簡化工程部署時的適配工作。特此開源,希望能幫助更多的同學。
1. 概述
YOLOv6 是美團視覺智能部研發的目標偵測框架,致力於工業應用。本架構同時專注於偵測的精確度與推理效率,在業界常用的尺寸模型中:YOLOv6-nano 在COCO 上精確度可達 35.0% AP,在T4 上推理速度可達 1242 FPS;YOLOv6-s 在COCO 上精確度可達 43.1% AP,在T4 上推理速度可達 520 FPS。在部署方面,YOLOv6 支援GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,極大簡化工程部署時的適配工作。目前,專案已開源至Github,傳送門:#YOLOv6#。歡迎有需要的朋友們Star收藏,隨時取用。
精準度與速度遠超YOLOv5 和YOLOX 的新框架
#目標檢測作為電腦視覺領域的一項基礎性技術,在工業界得到了廣泛的應用,其中YOLO 系列演算法因其較好的綜合性能,逐漸成為大多數工業應用時的首選框架。至今,業界已衍生出許多YOLO 檢測框架,其中以YOLOv5[1]、YOLOX[2] 和PP-YOLOE[3] 最具代表性,但在實際使用中,我們發現上述框架在速度和精度方面仍有很大的提升的空間。基於此,我們透過研究並借鑒了業界已有的先進技術,開發了一套新的目標偵測框架—YOLOv6。該框架支援模型訓練、推理及多平台部署等全鏈條的工業應用需求,並在網路結構、訓練策略等演算法層面進行了多項改進和最佳化,在COCO 資料集上,YOLOv6 在精度和速度方面均超越其他同體量演算法,相關結果如下圖1 所示:
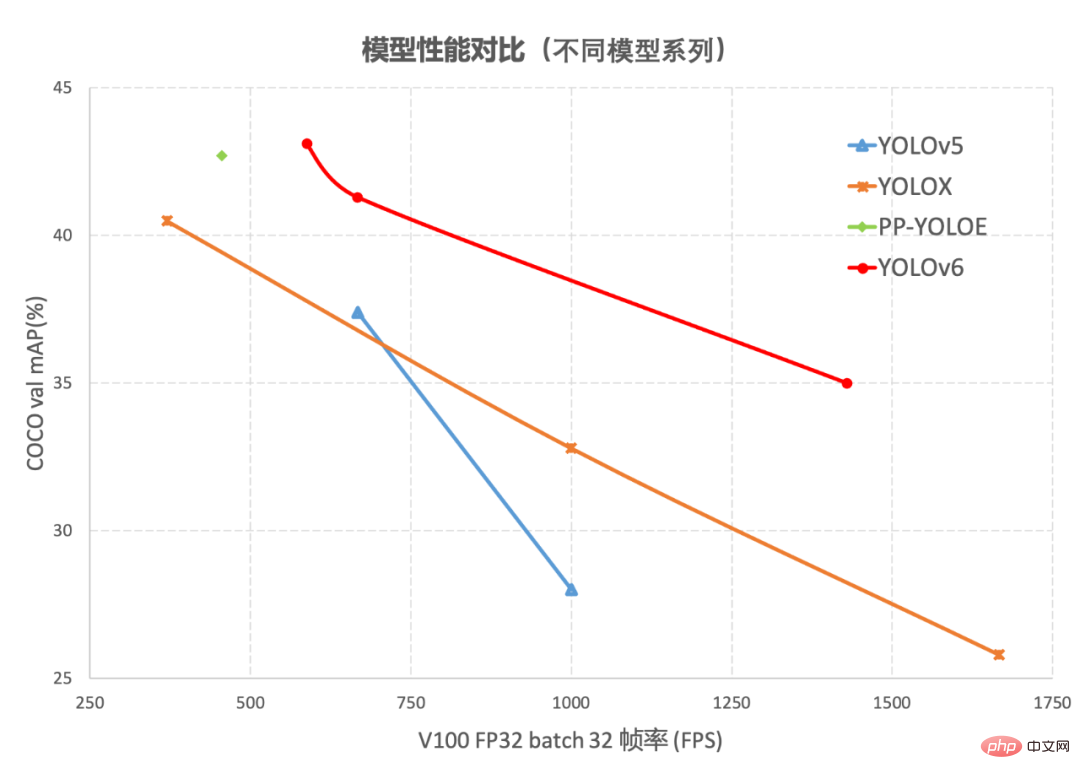
#圖1-1 YOLOv6 各尺寸模型與其他模型效能比較
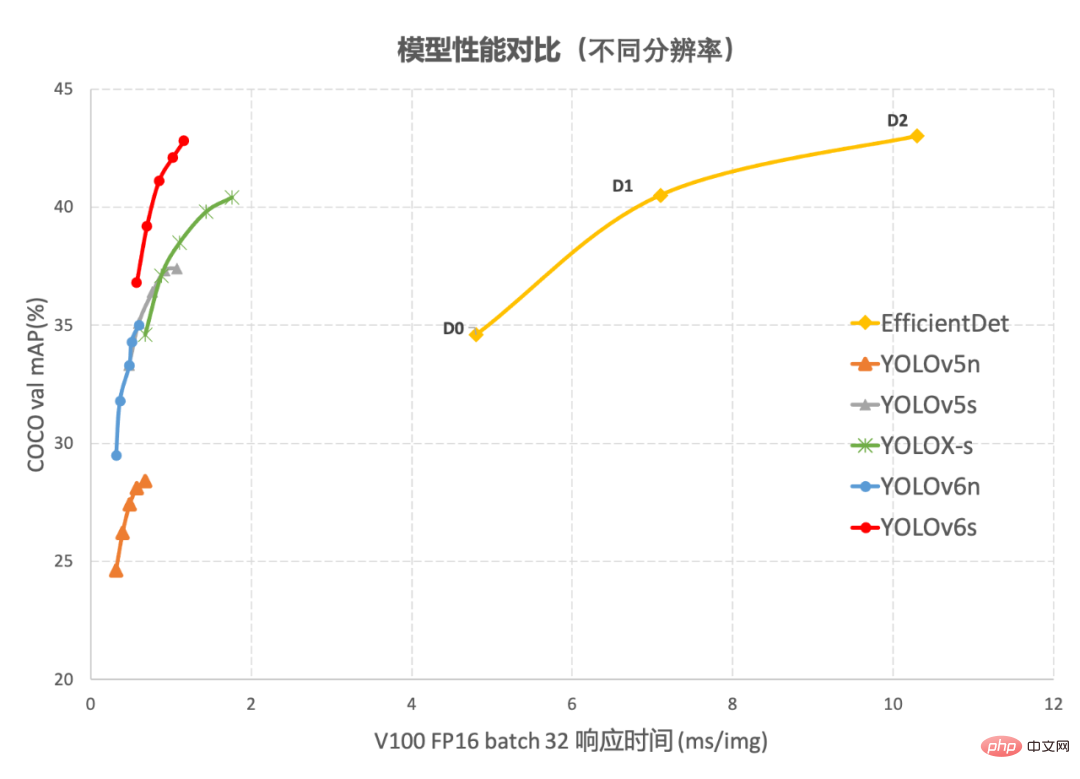
#YOLOv6 與其他模型在不同解析度下效能比較圖1-1
展示了不同尺寸網路下各檢測演算法的效能對比,曲線上的點分別表示此偵測演算法在不同尺寸網路下(s /tiny/nano)的模型性能,從圖中可以看到,YOLOv6 在精度和速度方面均超越其他YOLO 系列同體量演算法。 圖1-2 展示了輸入解析度變化時各檢測網路模型的效能對比,曲線上的點從左往右分別表示影像解析度依序增加時(
384/448/512/576 /640###)此模型的效能,從圖中可以看到,YOLOv6 在不同解析度下,仍保持較大的效能優勢。 #########2. YOLOv6關鍵技術介紹#########YOLOv6 主要在 Backbone、Neck、Head 以及訓練策略等方面進行了諸多的改進:######- 我們統一設計了更有效率的Backbone 和Neck :受到硬體感知神經網路設計想法的啟發,基於RepVGG style[4] 設計了可重參數化、更高效的骨幹網路EfficientRep Backbone 和Rep-PAN Neck。
- 優化設計了更簡潔有效的 Efficient Decoupled Head,在維持精確度的同時,進一步降低了一般解耦頭帶來的額外延遲開銷。
- 在訓練策略上,我們採用Anchor-free 無錨範式,同時輔以SimOTA[2] 標籤分配策略以及SIoU[9] 邊界框回歸損失來進一步提高偵測精確度。
2.1 Hardware-friendly 的骨幹網路設計
YOLOv5/YOLOX 使用的Backbone 和Neck 都基於CSPNet[5] 搭建,採用了多分支的方式和殘差結構。對於 GPU 等硬體來說,這種結構會一定程度上增加延時,同時減少記憶體頻寬利用率。下圖 2 為電腦體系結構領域中的 Roofline Model[8] 介紹圖,顯示了硬體中運算能力與記憶體頻寬之間的關聯關係。
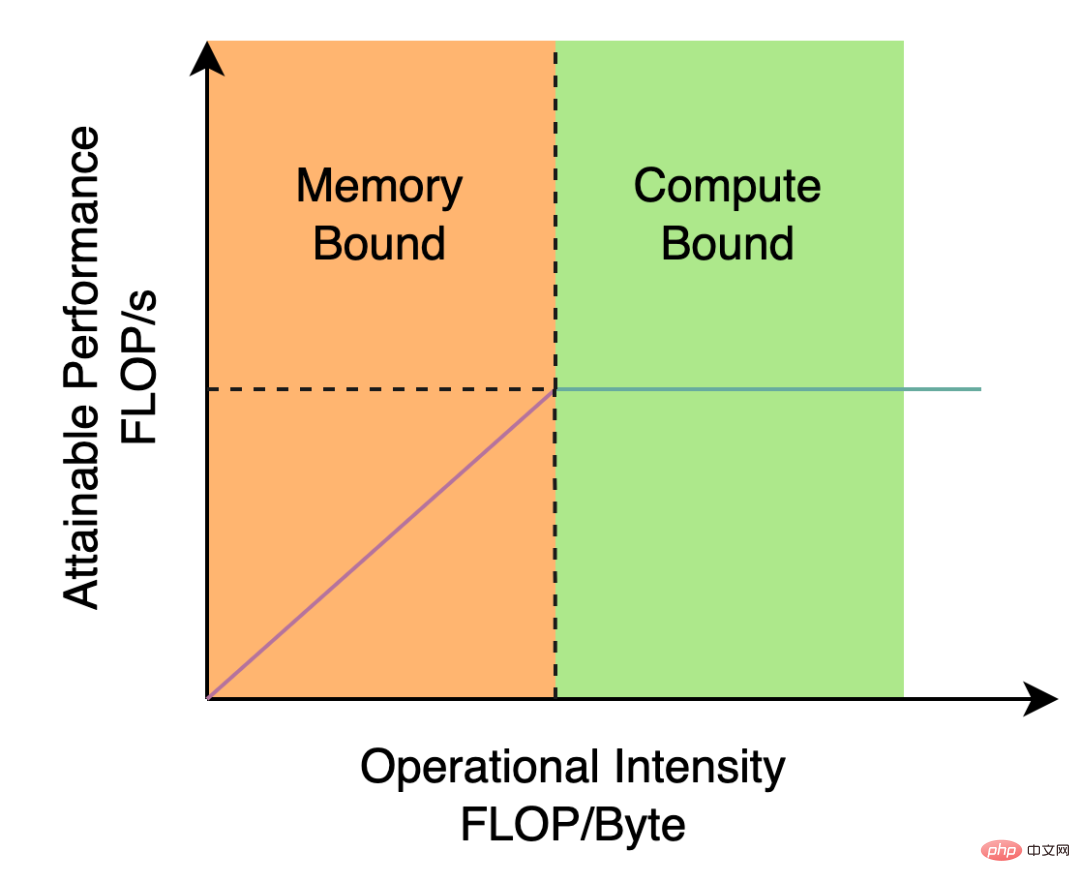
圖2 Roofline Model 介紹圖
#於是,我們基於硬體感知神經網路設計的思想,對Backbone 和Neck 進行了重新設計和最佳化。該思想基於硬體的特性、推理框架/編譯框架的特點,以硬體和編譯友善的結構作為設計原則,在網路建置時,綜合考慮硬體運算能力、記憶體頻寬、編譯最佳化特性、網路表徵能力等,進而獲得又快又好的網路結構。對上述重新設計的兩個偵測元件,我們在YOLOv6 中分別稱為EfficientRep Backbone 和Rep-PAN Neck,其主要貢獻點在於:
- #引入了RepVGG[4] style 結構。
- 基於硬體感知想法重新設計了 Backbone 和 Neck。
RepVGG[4] Style 結構是一種在訓練時具有多分支拓撲,而在實際部署時可以等效融合為單一3x3卷積的一種可重參數化的結構(融合過程如下圖3 所示)。透過融合成的3x3 卷積結構,可以有效利用運算密集型硬體運算能力(例如GPU),同時也可獲得GPU/CPU 上已經高度最佳化的NVIDIA cuDNN 和Intel MKL 編譯框架的協助。
實驗表明,透過上述策略,YOLOv6 減少了在硬體上的延時,並顯著提升了演算法的精度,讓檢測網路更快更強。以 nano 尺寸模型為例,比較 YOLOv5-nano 採用的網路結構,本方法在速度上提升了21%,同時精確度提升 3.6% AP。
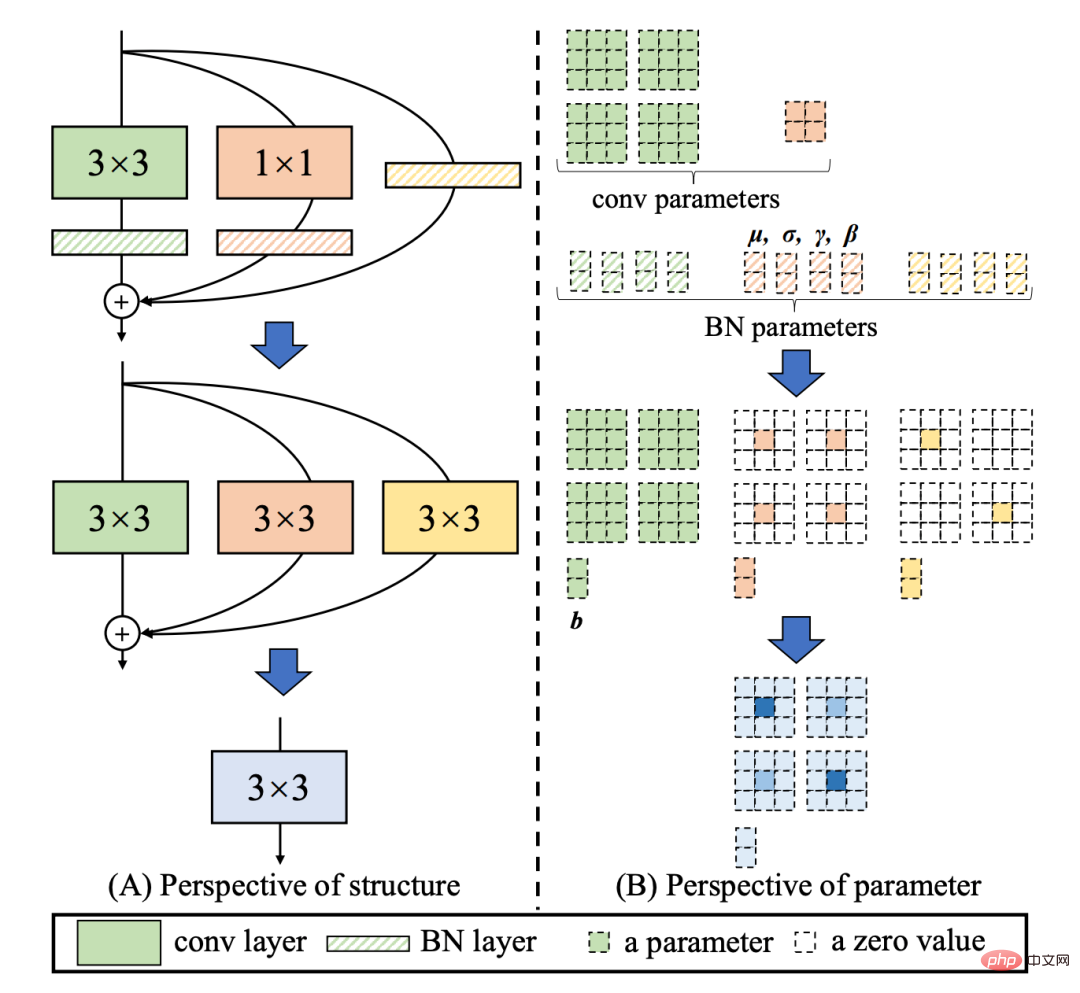
圖3 Rep算子的融合過程[4]
EfficientRep Backbone:在Backbone 設計方面,我們基於上述Rep 算符設計了一個高效率的Backbone。相較於 YOLOv5 採用的 CSP-Backbone,該 Backbone 能夠高效利用硬體(如 GPU)算力的同時,還具有較強的表徵能力。
下圖 4 為 EfficientRep Backbone 具體設計結構圖,我們將 Backbone 中 stride=2 的普通 Conv 層替換成了 stride=2 的 RepConv層。同時,將原始的 CSP-Block 都重新設計為 RepBlock,其中 RepBlock 的第一個 RepConv 會做 channel 維度的變換和對齊。另外,我們也將原始的 SPPF 最佳化設計為更有效率的 SimSPPF。
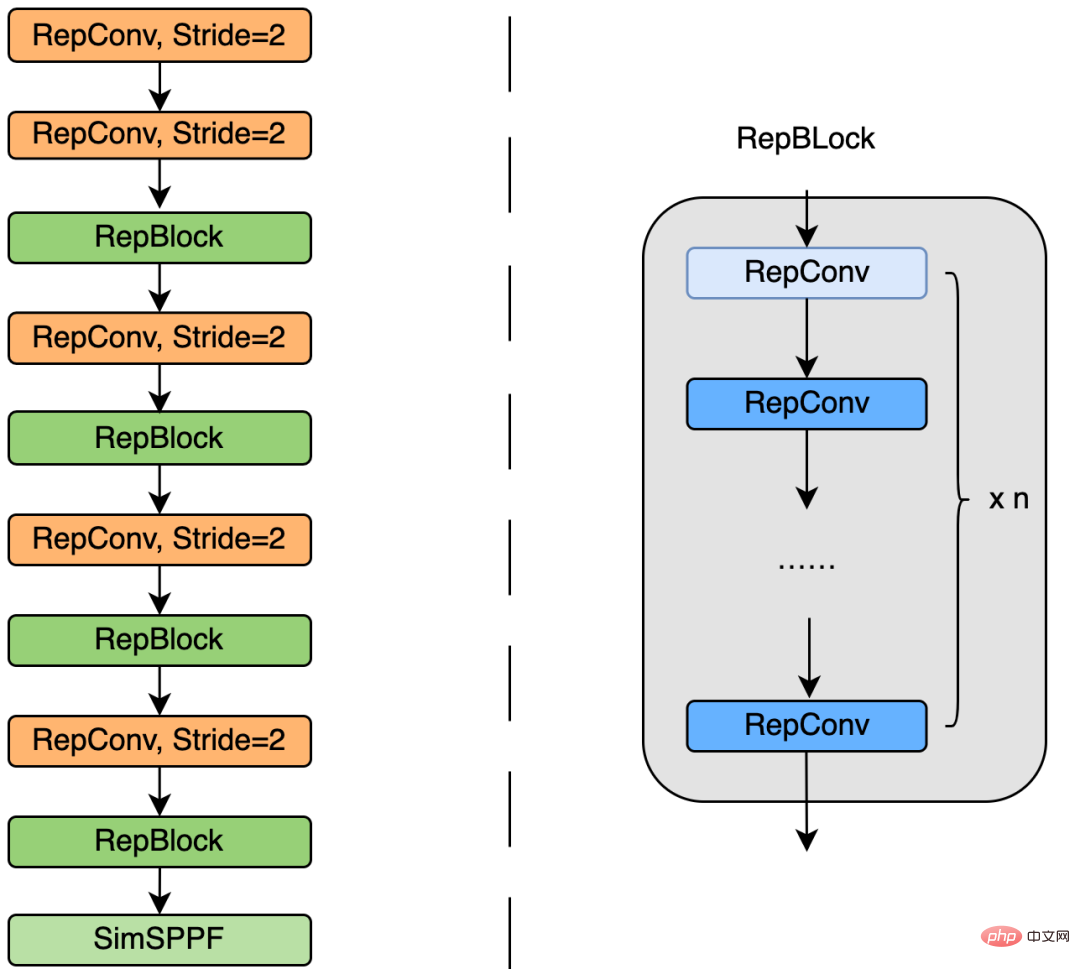
圖4 EfficientRep Backbone 結構圖
Rep-PAN#:在Neck 設計方面,為了讓其在硬體上推理更加高效,以達到更好的精度與速度的平衡,我們基於硬體感知神經網路設計思想,為YOLOv6 設計了一個更有效的特徵融合網路結構。
Rep-PAN 基於PAN[6] 拓撲方式,用RepBlock 取代了YOLOv5 中使用的CSP-Block,同時對整體Neck 中的算子進行了調整,目的是在在硬體上達到高效推理的同時,保持較好的多尺度特徵融合能力(Rep-PAN 結構圖如下圖5 所示)。
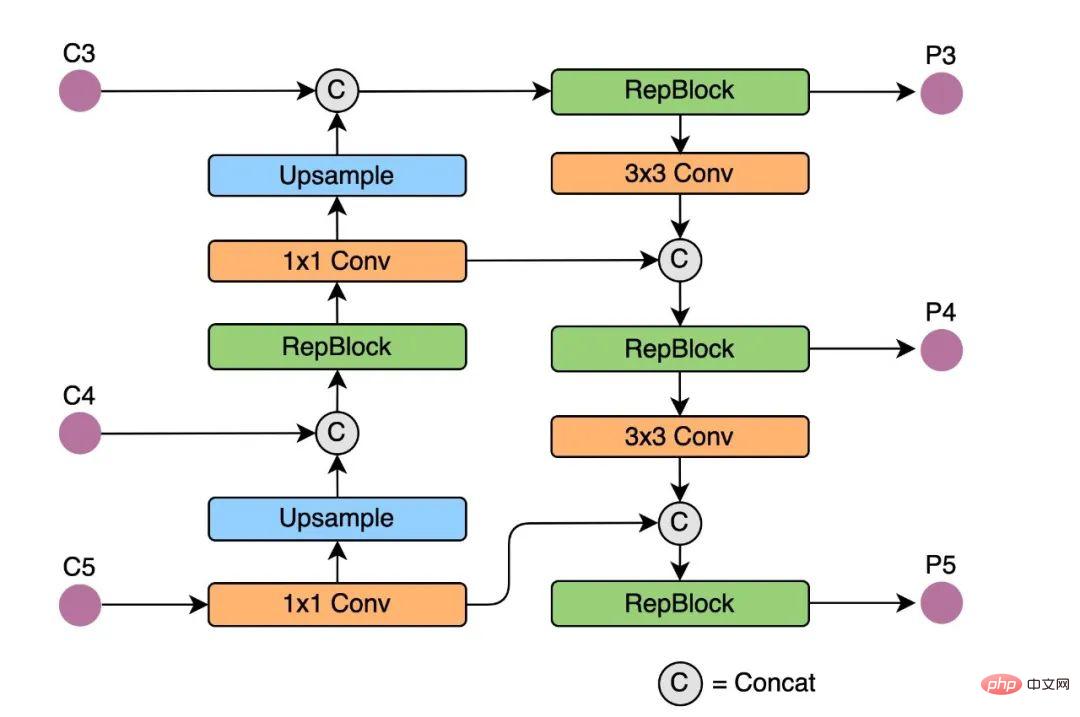
圖5 Rep-PAN 結構圖
2.2 更簡潔有效率的Decoupled Head
#在YOLOv6 中,我們採用了解耦檢測頭(Decoupled Head)結構,並對其進行了精簡設計。原始YOLOv5 的檢測頭是透過分類和回歸分支融合共享的方式來實現的,而YOLOX 的檢測頭則是將分類和回歸分支進行解耦,同時新增了兩個額外的3x3 的捲積層,雖然提升了偵測精度,但一定程度上增加了網路延遲。
因此,我們對解耦頭進行了精簡設計,同時綜合考慮到相關算子表徵能力和硬體上計算開銷這兩者的平衡,採用Hybrid Channels 策略重新設計了一個更有效率的解耦頭結構,在維持精度的同時降低了延時,緩解了解耦頭中3x3 卷積帶來的額外延時開銷。透過在 nano 尺寸模型上進行消融實驗,對比相同通道數的解耦頭結構,精度提升 0.2% AP 的同時,速度提升6.8%。
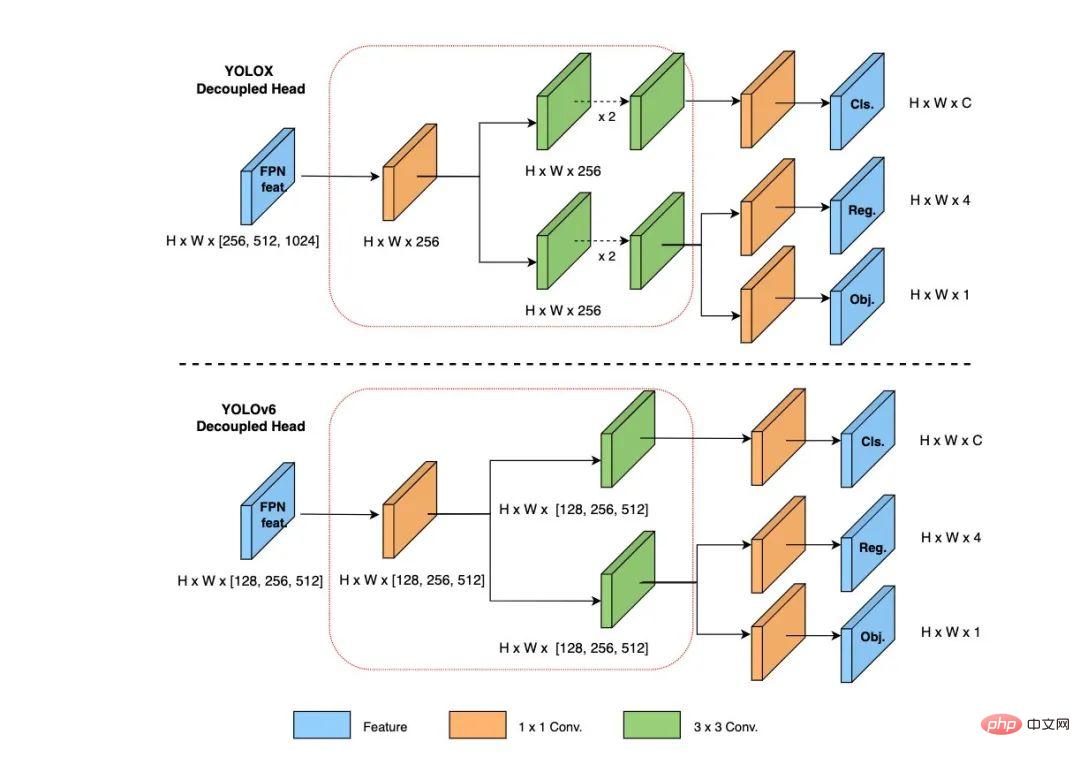
圖6 Efficient Decoupled Head 結構圖
2.3 更有效的訓練策略
#為了進一步提升檢測精度,我們吸收借鑒了學術界和業界其他檢測框架的先進研究進展:Anchor-free 無錨範式、SimOTA 標籤分配策略以及SIoU 邊界框回歸損失。
Anchor-free 無錨範式
#YOLOv6 採用了更簡潔的 Anchor-free 偵測方法。由於Anchor-based檢測器需要在訓練之前進行聚類分析以確定最佳Anchor 集合,這會一定程度提高檢測器的複雜度;同時,在一些邊緣端的應用中,需要在硬體之間搬運大量檢測結果的步驟,也會帶來額外的延遲。而 Anchor-free 無錨範式因其泛化能力強,解碼邏輯更簡單,在近幾年中應用比較廣泛。經過 Anchor-free 的實驗研究,我們發現,相較於Anchor-based 檢測器的複雜度所帶來的額外延時,Anchor-free 檢測器在速度上有51%的提升。
SimOTA 標籤分配策略
為了獲得更多高品質的正樣本,YOLOv6 引入了SimOTA [4]演算法動態分配正樣本,進一步提高偵測精度。 YOLOv5 的標籤分配策略是基於 Shape 匹配,並透過跨網格匹配策略增加正樣本數量,從而使得網路快速收斂,但是該方法屬於靜態分配方法,並不會隨著網路訓練的過程而調整。
近年來,也出現不少基於動態標籤分配的方法,此類方法會根據訓練過程中的網路輸出來分配正樣本,從而可以產生更多高品質的正樣本,繼而又促進網路的正向優化。例如,OTA[7] 將樣本匹配建模成最佳傳輸問題,求出全局資訊下的最佳樣本匹配策略以提升精確度,但OTA 由於使用了Sinkhorn-Knopp 演算法導致訓練時間加長,而SimOTA[4]演算法使用Top-K 近似策略來得到樣本最佳匹配,大大加快了訓練速度。故 YOLOv6 採用了SimOTA 動態分配策略,並結合無錨範式,在 nano 尺寸模型上平均檢測精度提升 1.3% AP。
SIoU 邊界框回歸損失
#為了進一步提升回歸精確度,YOLOv6 採用了SIoU[9 ] 邊界框回歸損失函數來監督網路的學習。目標偵測網路的訓練一般需要至少定義兩個損失函數:分類損失和邊界框迴歸損失,而損失函數的定義往往對偵測精度以及訓練速度產生較大的影響。
近年來,常用的邊界框回歸損失包括IoU、GIoU、CIoU、DIoU loss等等,這些損失函數透過考慮預測框與目標框之前的重疊程度、中心點距離、縱橫比等因素來衡量兩者之間的差距,從而指導網路最小化損失以提升回歸精度,但是這些方法都沒有考慮到預測框與目標框之間方向的匹配性。 SIoU 損失函數透過引入了所需回歸之間的向量角度,重新定義了距離損失,有效降低了回歸的自由度,加快網路收斂,進一步提升了回歸精度。透過在 YOLOv6s 上採用 SIoU loss 進行實驗,對比 CIoU loss,平均偵測精度提升 0.3% AP。
3. 實驗結果
經過以上最佳化策略和改進,YOLOv6 在多個不同尺寸下的模型均取得了卓越的表現。下表 1 展示了 YOLOv6-nano 的消融實驗結果,從實驗結果可以看出,我們自主設計的偵測網路在精確度和速度上都帶來了極大的增益。 
表1 YOLOv6-nano 消融實驗結果下表 2 展示了 YOLOv6 與當前主流的其他 YOLO 系列演算法相比較的實驗結果。從表格中可以看到:
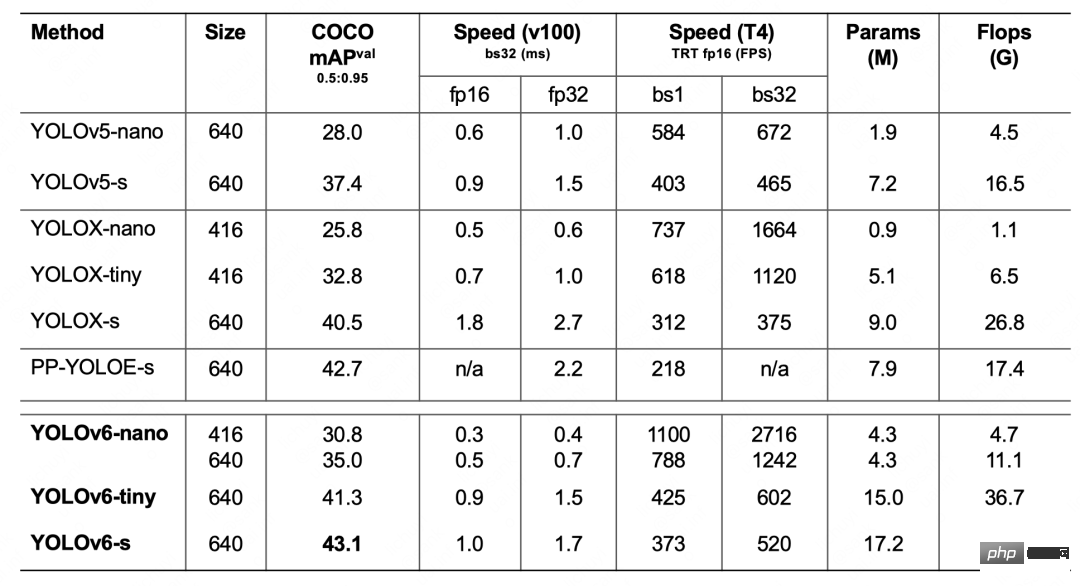
表2 YOLOv6各尺寸模型效能與其他模型的比較
- YOLOv6-nano 在COCO val 上取得了35.0% AP 的精度,同時在T4 上使用TRT FP16 batchsize=32 進行推理,可達到1242FPS 的性能,相較於YOLOv5-nano 精度提升7% AP ,速度提升85%。
- YOLOv6-tiny 在COCO val 上取得了41.3% AP 的精確度, 同時在T4 上使用TRT FP16 batchsize=32 進行推理,可達到602FPS 的效能,相較於YOLOv5 -s 精度提升3.9% AP,速度提升29.4%。
- YOLOv6-s 在COCO val 上取得了43.1% AP 的精度, 同時在T4 上使用TRT FP16 batchsize=32 進行推理,可達到520FPS 的性能,相較於YOLOX -s 精度提升2.6% AP,速度提升38.6%;相較於PP-YOLOE-s 精度提升0.4% AP的條件下,在T4上使用TRT FP16 進行單batch 推理,速度提升71.3%。
4. 總結與展望
#本文介紹了美團視覺智能部在目標偵測框架上的最佳化及實務經驗,我們針對YOLO 系列框架,在訓練策略、主幹網絡、多尺度特徵融合、檢測頭等方面進行了思考和優化,設計了新的檢測框架-YOLOv6,初衷來自於解決工業應用落地時所遇到的實際問題。
在打造YOLOv6 框架的同時,我們探索並優化了一些新的方法,例如基於硬體感知神經網路設計想法自研了EfficientRep Backbone、Rep-Neck 和Efficient Decoupled Head ,同時也吸收借鑒了學術界和工業界的一些前沿進展和成果,例如Anchor-free、SimOTA 和SIoU 回歸損失。在 COCO 資料集上的實驗結果顯示,YOLOv6 在偵測精度和速度方面都屬於佼佼者。
未來我們會持續建立和完善YOLOv6 生態,主要工作包括以下幾個面向:
- 完善YOLOv6 全系列模型,持續提升檢測性能。
- 在多種硬體平台上,設計硬體友善的模型。
- 支援 ARM 平台部署以及量化蒸餾等全鏈條適配。
- 橫向拓展和引入關聯技術,如半監督、自監督學習等等。
- 探索 YOLOv6 在更多的未知業務場景上的泛化效能。
以上是YOLOv6又快又準的目標偵測框架已經開源了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 十個推薦開源免費文字標註工具
Mar 26, 2024 pm 08:20 PM
十個推薦開源免費文字標註工具
Mar 26, 2024 pm 08:20 PM
文字標註工作是將標籤或標記與文字中特定內容相對應的工作。其主要目的是為文本提供額外的信息,以便進行更深入的分析和處理,尤其是在人工智慧領域。文字標註對於人工智慧應用中的監督機器學習任務至關重要。用於訓練AI模型,有助於更準確地理解自然語言文本訊息,並提高文本分類、情緒分析和語言翻譯等任務的表現。透過文本標註,我們可以教導AI模型識別文本中的實體、理解上下文,並在出現新的類似數據時做出準確的預測。本文主要推薦一些較好的開源文字標註工具。 1.LabelStudiohttps://github.com/Hu
 15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
15個值得推薦的開源免費圖片標註工具
Mar 28, 2024 pm 01:21 PM
圖像標註是將標籤或描述性資訊與圖像相關聯的過程,以賦予圖像內容更深層的含義和解釋。這個過程對於機器學習至關重要,它有助於訓練視覺模型以更準確地識別圖像中的各個元素。透過為圖像添加標註,使得電腦能夠理解圖像背後的語義和上下文,從而提高對圖像內容的理解和分析能力。影像標註的應用範圍廣泛,涵蓋了許多領域,如電腦視覺、自然語言處理和圖視覺模型具有廣泛的應用領域,例如,輔助車輛識別道路上的障礙物,幫助疾病的檢測和診斷透過醫學影像識別。本文主要推薦一些較好的開源免費的圖片標註工具。 1.Makesens
 美團外帶櫃怎麼取
Apr 08, 2024 pm 03:41 PM
美團外帶櫃怎麼取
Apr 08, 2024 pm 03:41 PM
1.當外送員將餐點放入櫃中後,會透過簡訊、電話或美團訊息通知顧客取餐。 2.顧客可以透過微信或美團APP掃描取餐櫃上的二維碼,進入智慧取餐櫃小程式。 3.輸入取件碼或使用「一鍵開櫃」功能,即可輕鬆開啟櫃門,取走外帶。
 建議:優秀JS開源人臉偵測辨識項目
Apr 03, 2024 am 11:55 AM
建議:優秀JS開源人臉偵測辨識項目
Apr 03, 2024 am 11:55 AM
人臉偵測辨識技術已經是一個比較成熟且應用廣泛的技術。而目前最廣泛的網路應用語言非JS莫屬,在Web前端實現人臉偵測辨識相比後端的人臉辨識有優勢也有弱勢。優點包括減少網路互動、即時識別,大大縮短了使用者等待時間,提高了使用者體驗;弱勢是:受到模型大小限制,其中準確率也有限。如何在web端使用js實現人臉偵測呢?為了實現Web端人臉識別,需要熟悉相關的程式語言和技術,如JavaScript、HTML、CSS、WebRTC等。同時也需要掌握相關的電腦視覺和人工智慧技術。值得注意的是,由於Web端的計
 美團付密碼忘了怎麼找回_美團找回支付密碼忘記的方法
Mar 28, 2024 pm 03:29 PM
美團付密碼忘了怎麼找回_美團找回支付密碼忘記的方法
Mar 28, 2024 pm 03:29 PM
1.首先我們進入美團軟體,在我的選單頁面找到設置,點選進入設定。 2、接著我們在設定頁面中找到支付設置,點選進入支付設定。 3.進入支付中心,找到支付密碼設置,點選進入支付密碼設定。 4.在支付密碼設定頁面中,找到找回支付密碼,點選進入頁面選項。 5.輸入想要找回的支付密碼訊息,點選驗證,通過後即可找回支付密碼。
 阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模態文件理解能力新SOTA!阿里mPLUG團隊發布最新開源工作mPLUG-DocOwl1.5,針對高解析度圖片文字辨識、通用文件結構理解、指令遵循、外部知識引入四大挑戰,提出了一系列解決方案。話不多說,先來看效果。複雜結構的圖表一鍵識別轉換為Markdown格式:不同樣式的圖表都可以:更細節的文字識別和定位也能輕鬆搞定:還能對文檔理解給出詳細解釋:要知道,“文檔理解”目前是大語言模型實現落地的一個重要場景,市面上有許多輔助文檔閱讀的產品,有的主要透過OCR系統進行文字識別,配合LLM進行文字理
 美團怎麼刪除評價 刪除評價操作方法
Mar 12, 2024 pm 07:31 PM
美團怎麼刪除評價 刪除評價操作方法
Mar 12, 2024 pm 07:31 PM
我們在使用這款平台的時候,上面也是擁有對於各種美食還有消費方面都是有評價的,其中的一些操作方法也是極為簡單的,我們所去消費的時候,都應該能夠看到上面對於一些功能上的一些選擇,都是可以自己來進行一些打分評價的,不過有些時候我們可能要自己來刪除對於一些店舖方面的錯誤評價,但是用戶們不知道怎麼去進行這些評價,所以今日小編就來給你們詳細的講解上面的一些功能,所以有任何想法的,今日小編就來給你們詳解怎麼去進行刪除,有興趣的話,現在就和小編一起來看看吧,我相信大家們應該都會有所了解,不要錯過了。 刪
 美團地址在哪裡改?美團地址修改教學!
Mar 15, 2024 pm 04:07 PM
美團地址在哪裡改?美團地址修改教學!
Mar 15, 2024 pm 04:07 PM
一、美團地址在哪裡改?美團地址修改教學!方法(一)1.進入美團我的頁面,點選設定。 2.選擇個人資訊。 3.再點選收貨地址。 4.最後選擇要修改的地址,點選地址右側的筆圖標,修改即可。方法(二)1.在美團app首頁,點選外賣,進入後點選更多功能。 2.在更多介面,點選管理地址。 3.在我的收貨地址介面,選擇編輯。 4.依需求一一修改,最後點選儲存地址即可。
