
強化學習(RL)可以讓機器人透過反覆試錯進行交互,進而學會複雜行為,並隨著時間的推移變得越來越好。之前谷歌的一些工作探索了 RL 如何使機器人掌握複雜的技能,例如抓取、多任務學習,甚至是打乒乓球。雖然機器人強化學習已經取得了長足進步,但我們仍然沒有在日常環境中看到有強化學習加持的機器人。因為現實世界是複雜多樣的,並且隨著時間的推移而不斷變化,這為機器人系統帶來巨大挑戰。然而,強化學習應該是應對這些挑戰的優秀工具:透過不斷練習、不斷進步和在工作中學習,機器人應該能夠適應不斷變化的世界。
在Google的論文《 Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators 》中,研究人員探討如何透過最新的大規模實驗解決這個問題,他們在兩年內部署了一支由23 個支援RL 的機器人組成的群組,用於在谷歌辦公大樓中進行垃圾分類和回收。使用的機器人系統將來自真實世界數據的可擴展深度強化學習與來自模擬訓練的引導和輔助對象感知輸入相結合,以提高泛化能力,同時保留端到端訓練優勢,透過對240 個垃圾站進行4800 次評估試驗來驗證。

論文網址:https://rl-at-scale.github.io/assets/rl_at_scale .pdf
如果人們沒有正確分類垃圾,成批的可回收物品可能會受到污染,堆肥可能會被不當丟棄到垃圾掩埋場。在Google的實驗中,機器人在辦公大樓周圍漫遊,尋找 「垃圾站」(可回收垃圾箱、堆肥垃圾箱和其它垃圾箱)。機器人的任務是到達每個垃圾站進行垃圾分類,在不同垃圾箱之間運輸物品,以便將所有可回收物品(罐頭、瓶子)放入可回收垃圾箱,將所有可堆肥物品(紙板容器、紙杯)放入堆肥垃圾箱,其他所有東西都放在其它垃圾箱裡。
其實這項任務並不像看起來那麼容易。光是撿起人們丟進垃圾桶的不同物品的子任務,就已經是一個巨大的挑戰。機器人還必須為每個物體識別合適的垃圾箱,並盡可能快速有效地對它們進行分類。在現實世界中,機器人會遇到各種獨特的情況,例如以下真實辦公大樓的例子:
在工作中不斷學習是有幫助的,但在達到這一點之前,需要用一套基本的技能來引導機器人。為此,Google使用了四種經驗來源:(1)簡單的手工設計策略,成功率很低,但有助於提供初步經驗;(2)模擬訓練框架,使用模擬- 真實的遷移來提供一些初步的垃圾分類策略;(3)“robot classrooms”,機器人使用代表性的垃圾站不斷練習(4)真實的部署環境,機器人在有真實垃圾的辦公大樓裡練習。
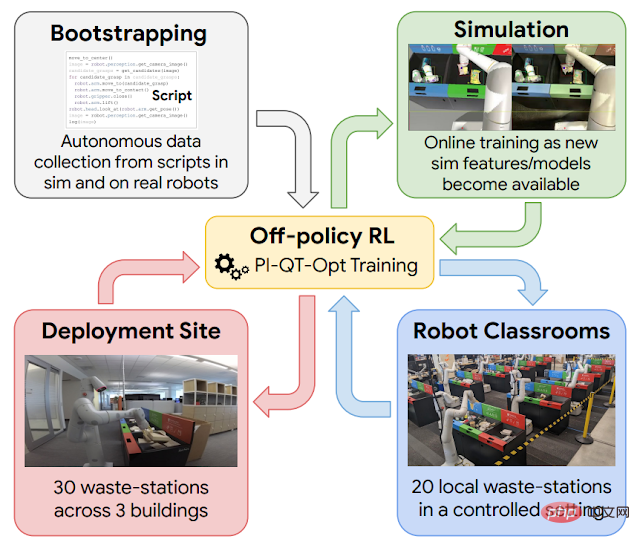
強化學習在該大規模應用中的示意圖。使用腳本產生的資料引導策略的啟動(左上圖)。然後訓練一個從模擬到實際的模型,在模擬環境中產生額外的資料(右上圖)。在每個部署週期中,新增在 “robot classrooms” 中收集的資料(右下圖)。在辦公大樓中部署和收集資料(左下圖)。
這裡使用的強化學習框架是基於 QT-Opt,實驗室環境下的不同垃圾的抓取以及一系列其他技能也是使用該框架。在模擬環境中從簡單的腳本策略開始引導,應用強化學習,並使用基於 CycleGAN 的遷移方法,利用 RetinaGAN 讓模擬影像看起來更逼真。
到此就開始進入 “robot classrooms”。雖然實際的辦公大樓可以提供最真實的體驗,但資料收集的吞吐量是有限的 —— 有些時間會有很多垃圾需要分類,有些時間則不會有那麼多。機器人在 “robot classrooms” 中累積了大部分的經驗。在下面展示的「robot classrooms」 裡,有20 個機器人練習垃圾分類任務:

當這些機器人在「robot classrooms」接受訓練時,其它機器人正在3 座辦公大樓中的30 個垃圾站上同時學習。
最終,研究人員從 「robot classrooms」 收集了 54 萬個試驗數據,在實際部署環境收集了 32.5 萬個試驗數據。隨著數據的不斷增加,整個系統的性能得到了改善。研究者在 “robot classrooms” 中對最終系統進行了評估,以便進行受控比較,根據機器人在實際部署中看到的情況設定了場景。最終系統的平均準確率約為 84%,隨著數據的增加,性能穩步提高。在現實世界中,研究人員記錄了 2021 年至 2022 年實際部署的統計數據,發現系統可以按重量將垃圾桶中的污染物減少 40%至 50%。谷歌研究人員在論文提供了有關技術設計、各種設計決策的削弱研究以及實驗的更詳細統計數據的更深入見解。
實驗結果表明,基於強化學習的系統可以使機器人在真實辦公環境中處理實際任務。離線和線上數據的結合使得機器人能夠適應真實世界中廣泛變化的情況。同時,在更受控的 「課堂」 環境中學習,包括在模擬環境和實際環境中,可以提供強大的啟動機制,使得強化學習的 「飛輪」 開始轉動,從而實現適應性。
雖然已經取得了重要成果,但還有很多工作需要完成:最終的強化學習策略並不總是成功的,需要更強大的模型來改善其性能,並將其擴展到更廣泛的任務範圍。除此之外,其它經驗來源,包括來自其它任務、其它機器人,甚至是互聯網視頻,也可能會進一步補充從仿真和” 課堂 “中獲得的啟動經驗。這些都是未來需要解決的問題。
以上是耗時兩年谷歌用強化學習打造23個機器人幫助垃圾分類的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















