

ChatGPT專題之一GPT家族演化史

時間軸
2018 年 6 月
OpenAI發布GPT-1模型,1.1億參數。
2018 年 11 月
OpenAI發布GPT-2模型,15億參數,但由於擔心濫用,不向公眾開放模型的全部程式碼及資料。
2019 年 2 月
OpenAI開放了GPT-2模型的部分程式碼和數據,但仍然限制了存取。
2019 年 6 月 10 日
OpenAI發布GPT-3模型,1750億參數,並向部分合作夥伴提供了存取權限。
2019 年 9 月
OpenAI開放了GPT-2的全部程式碼和數據,並發布了更大版本。
2020 年 5 月
OpenAI宣布推出GPT-3模型的beta版本,該模型擁有1750億個參數,是迄今為止最大的自然語言處理模型。
2022 年3 月
OpenAI發布InstructGPT,用到Instruction Tuning
2022 年11 月30 日
OpenAI透過GPT-3.5系列大型語言模型微調而成的,全新對話式AI模型ChatGPT正式發表。
2022 年 12 月 15 日
ChatGPT 第一次更新,提升了整體效能,增加了保存和查看歷史對話記錄的新功能。
2023 年 1 月 9 日
ChatGPT 第二次更新,改善了答案的真實性,增加了「停止產生」新功能。
2023 年 1 月 21 日
OpenAI發佈限於部分使用者使用的付費版ChatGPT Professional。
2023 年 1 月 30 日
ChatGPT第三次更新,在此提升了答案真實性的同時,也提升了數學能力。
2023 年 2 月 2 日
OpenAI正式推出ChatGPT收費版訂閱服務,新版本比較免費版回應速度更快,運作更為穩定。
2023 年3 月15 日
OpenAI震撼推出了大型多模態模型GPT-4,不僅能夠閱讀文字,還能識別圖像,並產生文本結果,現已接入ChatGPT 向Plus用戶開放。
GPT-1:基於單向Transformer的預訓練模型
在 GPT 出現之前,NLP 模型主要是基於針對特定任務的大量標註資料進行訓練。這會導致一些限制:
大規模高品質的標註資料不易取得;
模型僅限於所接受的訓練,泛化能力不足;
無法執行開箱即用的任務,限制了模型的落地應用。
為了克服這些問題,OpenAI走上了預訓練大模型的道路。 GPT-1是由OpenAI於2018年發布的第一個預訓練模型,它採用了單向Transformer模型,並使用了超過40GB的文字資料進行訓練。 GPT-1的關鍵特徵是:生成式預訓練(無監督) 判別式任務精調(有監督)。先用無監督學習的預訓練,在8 個GPU 上花費了1 個月的時間,從大量未標註數據中增強AI系統的語言能力,獲得大量知識,然後進行有監督的微調,與大型數據集整合來提高系統在NLP任務中的效能。 GPT-1在文字生成和理解任務上表現出了很好的性能,成為了當時最先進的自然語言處理模型之一。
GPT-2:多任務預訓練模型
由於單任務模型缺乏泛化性,並且多任務學習需要大量有效訓練對,GPT-2在GPT-1的基礎上進行了擴展和優化,去掉了有監督學習,只保留了無監督學習。 GPT-2採用了更大的文字資料和更強大的運算資源進行訓練,參數規模達到了1.5億,遠超過GPT-1的1.1億參數。除了使用更大的資料集和更大的模型去學習,GPT-2還提出了一個新的更難的任務:零樣本學習(zero-shot),即將預先訓練好的模型直接應用於諸多的下游任務。 GPT-2在多項自然語言處理任務上展現了卓越的效能,包括文字生成、文字分類、語言理解等。

GPT-3:創造新的自然語言生成與理解能力
GPT-3是GPT系列模型中最新的一款模型,採用了更大的參數規模和更豐富的訓練資料。 GPT-3的參數規模達到了1.75萬億,是GPT-2的100倍以上。 GPT-3在自然語言生成、對話生成和其他語言處理任務上表現出了驚人的能力,在某些任務上甚至能夠創造出新的語言表達形式。
GPT-3提出了一個非常重要的概念:情境學習(In-context learning),具體內容會在下次推文中解釋。
InstructGPT & ChatGPT
InstructGPT/ChatGPT的訓練分成3步,每一步所需的資料也有些許差異,下面我們分別介紹它們。
從一個預先訓練的語言模型開始,應用以下三個步驟。
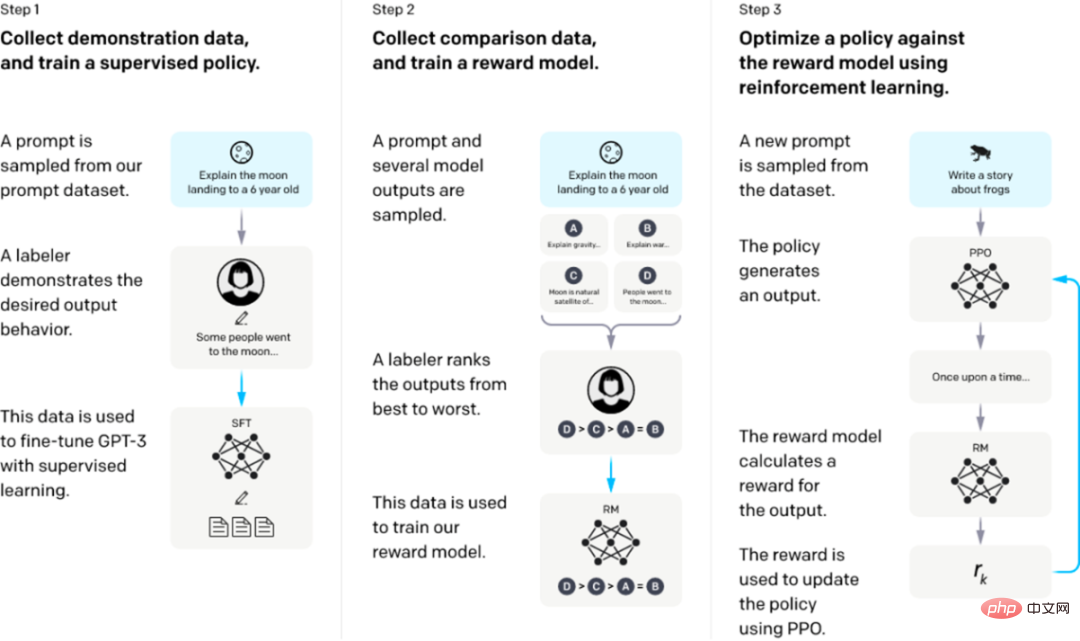
步驟1:監督微調SFT:收集演示數據,訓練一個受監督的策略。我們的標籤器提供了輸入提示分佈上所需行為的示範。然後,我們使用監督式學習在這些資料上對預先訓練的GPT-3模型進行微調。
步驟2:獎勵模型Reward Model訓練。收集比較數據,訓練一個獎勵模型。我們收集了一個模型輸出之間比較的資料集,其中標籤者表示他們更喜歡給定輸入的哪個輸出。然後我們訓練一個獎勵模型來預測人類偏好的輸出。
步驟3:透過獎勵模型上的近端策略優化(PPO)強化學習:使用RM的輸出作為標量獎勵。我們使用PPO演算法對監督策略進行微調,以優化該獎勵。
步驟2和步驟3可以連續迭代;在目前最優策略上收集更多的比較數據,這些數據用於訓練一個新的RM,然後是一個新的策略。
前兩步的prompts,來自OpenAI的線上API上的用戶使用數據,以及僱用的標註者手寫的。最後一步則全都是從API資料中取樣的,InstructGPT的具體資料:
1. SFT資料集
SFT資料集是用來訓練第1步有監督的模型,即使用採集的新數據,依照GPT-3的訓練方式對GPT-3進行微調。因為GPT-3是一個基於提示學習的生成模型,因此SFT資料集也是由提示-答案對組成的樣本。 SFT資料一部分來自使用OpenAI的PlayGround的用戶,另一部分來自OpenAI僱用的40名標註工(labeler)。並且他們對labeler進行了培訓。在這個資料集中,標註工的工作是根據內容自己寫指示。
2. RM資料集
RM資料集用來訓練步驟2的獎勵模型,我們也需要為InstructGPT/ChatGPT的訓練設定一個獎勵目標。這個獎勵目標不必可導,但是一定要盡可能全面且真實的對齊我們需要模型產生的內容。很自然的,我們可以透過人工標註的方式來提供這個獎勵,透過人工對可以給那些涉及偏見的生成內容更低的分從而鼓勵模型不去生成這些人類不喜歡的內容。 InstructGPT/ChatGPT的做法是先讓模型產生一批候選文本,讓後透過labeler根據產生資料的品質對這些生成內容進行排序。
3. PPO資料集
InstructGPT的PPO資料沒有進行標註,它皆來自GPT-3的API的使用者。既不同使用者提供的不同種類的生成任務,其中佔比最高的包括生成任務(45.6%),QA(12.4%),腦力激盪(11.2%),對話(8.4%)等。
附 錄:
ChatGPT 的各項能力來源:

以上是ChatGPT專題之一GPT家族演化史的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
ChatGPT 現在允許免費用戶使用 DALL-E 3 產生每日限制的圖像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 於 2023 年 9 月正式推出,是比其前身大幅改進的車型。它被認為是迄今為止最好的人工智慧圖像生成器之一,能夠創建具有複雜細節的圖像。然而,在推出時,它不包括
 YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度學習方法專注於設計最適合的目標函數,以使模型的預測結果與實際情況最接近。同時,必須設計一個合適的架構,以便為預測取得足夠的資訊。現有方法忽略了一個事實,當輸入資料經過逐層特徵提取和空間變換時,大量資訊將會遺失。本文將深入探討資料透過深度網路傳輸時的重要問題,即資訊瓶頸和可逆函數。基於此提出了可編程梯度資訊(PGI)的概念,以應對深度網路實現多目標所需的各種變化。 PGI可以為目標任務提供完整的輸入訊息,以計算目標函數,從而獲得可靠的梯度資訊以更新網路權重。此外設計了一種新的輕量級網路架
 手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
手機怎麼安裝chatgpt
Mar 05, 2024 pm 02:31 PM
安裝步驟:1、在ChatGTP官網或手機商店下載ChatGTP軟體;2、開啟後在設定介面中,選擇語言為中文;3、在對局介面中,選擇人機對局並設定中文相譜;4 、開始後在聊天視窗中輸入指令,即可與軟體互動。
 深入了解Win10分區格式:GPT和MBR的比較
Dec 22, 2023 am 11:58 AM
深入了解Win10分區格式:GPT和MBR的比較
Dec 22, 2023 am 11:58 AM
對自己的系統分區時由於用戶使用的硬碟不同因此很多的用戶也不知道win10分區格式gpt還是mbr,為此我們給大家帶來了詳細的介紹,幫助大家了解兩者間的不同。 win10分區格式gpt還是mbr:答:如果你使用的是超過3t的硬碟,可以用gpt。 gpt比mbr更加的先進,但相容性方面還是mbr比較厲害。當然這也是完全可以依照使用者的喜好來進行選擇的。 gpt和mbr的差別:一、支援的分割個數:1、MBR最多支援劃分4個主分割區。 2、GPT則不受分區數的限制。二、支援的硬碟大小:1、MBR最大僅支援2TB
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 Kubernetes調試終極武器: K8sGPT
Feb 26, 2024 am 11:40 AM
Kubernetes調試終極武器: K8sGPT
Feb 26, 2024 am 11:40 AM
隨著人工智慧和機器學習技術的不斷發展,企業和組織開始積極探索創新策略,以利用這些技術來提升競爭力。 K8sGPT[2]是該領域內強大的工具之一,它是基於k8s的GPT模型,兼具k8s編排的優勢和GPT模型出色的自然語言處理能力。什麼是K8sGPT?先看一個例子:根據K8sGPT官網解釋:K8sgpt是一個專為掃描、診斷和分類kubernetes集群問題而設計的工具,它整合了SRE經驗到其分析引擎中,以提供最相關的信息。透過人工智慧技術的應用,K8sgpt持續豐富其內容,幫助使用者更快速、更精確地解
 如何確定電腦硬碟採用的是GPT還是MBR分割方式
Dec 25, 2023 pm 10:57 PM
如何確定電腦硬碟採用的是GPT還是MBR分割方式
Dec 25, 2023 pm 10:57 PM
何看電腦硬碟是GPT分割區還是MBR分割區呢?當我們用到電腦硬碟的時候,需要進行GPT與MBR的區分,其實這個檢視方法特別簡單,下面跟我一起來看看吧。查看電腦硬碟是GPT還是MBR的方法1、右鍵點選桌面上的'電腦「點選」管理2、在」管理「中找得」磁碟管理「3、進入磁碟管理可以看到我們硬碟的一般情況,那麼該如何查看我的硬碟的分區模式,右鍵單擊”磁碟0“選擇”屬性“4、在”屬性“中切換到”卷“標籤,這時我們就可以看到”磁碟分區形式“可以看到為MBR分割區win10磁碟相關問題如何將MBR分割區轉換成GPT分割區>
 如何使用ChatGPT和Java開發智慧聊天機器人
Oct 28, 2023 am 08:54 AM
如何使用ChatGPT和Java開發智慧聊天機器人
Oct 28, 2023 am 08:54 AM
在這篇文章中,我們將介紹如何使用ChatGPT和Java開發智慧聊天機器人,並提供一些具體的程式碼範例。 ChatGPT是由OpenAI開發的困境預測轉換(GenerativePre-trainingTransformer)的最新版本,它是一種基於神經網路的人工智慧技術,可以理解自然語言並產生人類類似的文本。使用ChatGPT,我們可以輕鬆地創建自適應的聊天
