
大語言模型的快速「變異」,讓人類社會的走向越來越科幻了。點亮這棵科技樹後,「終結者」的現實彷彿離我們越來越近。
前幾天,微軟剛宣布了一個實驗框架,能用ChatGPT來控制機器人和無人機。
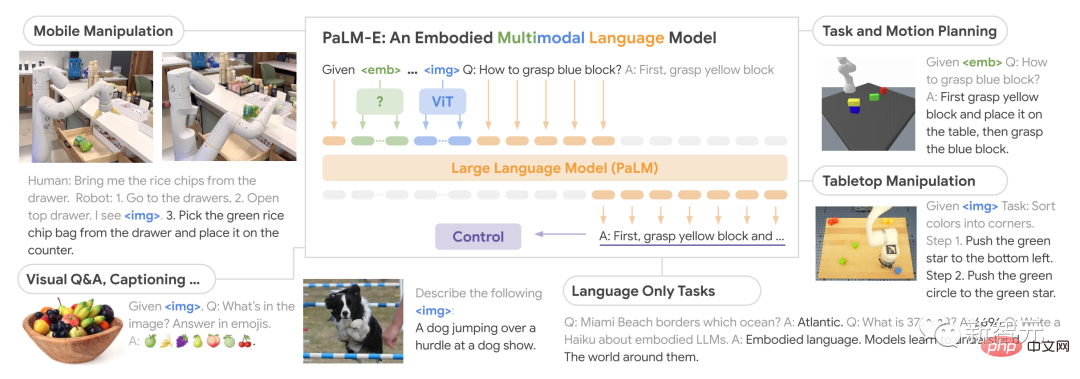
Google當然也不甘其後,在周一,來自谷歌和柏林工業大學的團隊重磅推出了史上最大視覺語言模型——PaLM-E。

論文網址:https://arxiv.org/abs/2303.03378
#作為一種多模態具身視覺語言模型(VLM),PaLM-E不僅可以理解圖像,還能理解、生成語言,而且竟然還能將兩者結合起來,處理複雜的機器人指令。
此外,透過PaLM-540B語言模型與ViT-22B視覺Transformer模型結合,PaLM-E最終的參數量高達5620億。

PaLM-E,全名為Pathways Language Model with Embodied,是一種具身視覺語言模型。
它的強大之處在於,能夠利用視覺資料來增強其語言處理能力。

當我們訓練出最大的視覺語言模型,並與機器人結合後,會發生什麼事?結果就是PaLM-E,一個5,620億參數、通用、具身的視覺語言通才-橫跨機器人、視覺和語言
根據論文介紹,PaLM-E是僅解碼器的LLM,在給定前綴(prefix)或提示(prompt)下,能夠以自回歸方式產生文字補全。
其訓練資料為包含視覺、連續狀態估計值和文字輸入編碼的多模式語句。
經過單一影像提示訓練,PaLM-E不僅可以引導機器人完成各種複雜的任務,還可以產生描述影像的語言。
可以說,PaLM-E展現了前所未有的靈活性和適應性,代表著一個重大飛躍,特別是人機互動領域。
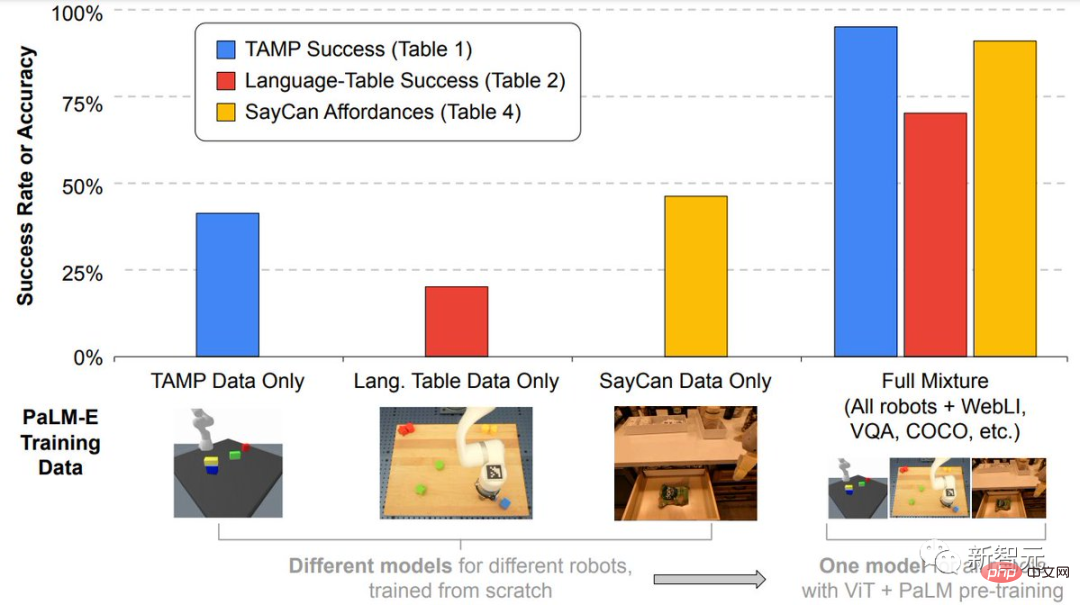
更重要的是,研究人員證明,透過在多個機器人和一般視覺語言的不同混合任務組合進行訓練,可以帶來從視覺語言轉移到具身決策的幾種方法,讓機器人在規劃任務時能有效地利用數據。
除此之外,PaLM-E特別突出的一點在於,擁有強大的正向遷移能力。
在不同領域訓練的PaLM-E,包括網路規模的一般視覺-語言任務,與執行單一任務機器人模型相比,表現明顯提高。
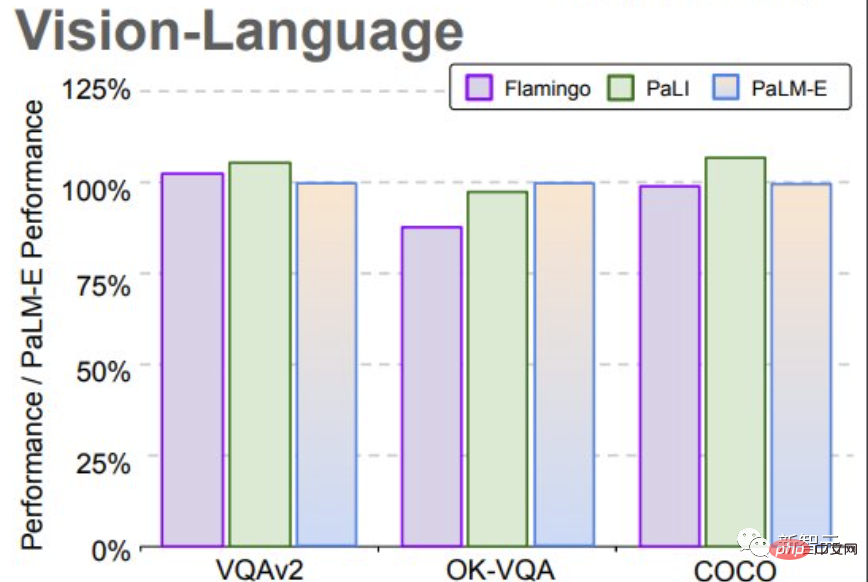
而在模型尺度上,研究者則觀察到了一個顯著的優勢。
語言模型越大,在視覺語言與機器人任務的訓練中,保持的語言能力就越強。
從模型規模來看,5620億參數的PaLM-E幾乎保持了它所有的語言能力。
儘管只在單一圖像進行訓練,但PaLM-E在多模態思維鏈推理和多圖像推理等任務中表現出突出的能力。
在OK-VQA基準上,PaLM-E取得了新的SOTA。
在測驗中,研究者展示如何使用PaLM-E在兩個不同實體上執行規劃以及長跨度的任務。
值得注意的是,所有這些結果都是使用基於相同資料訓練的相同模型獲得的。
以前,機器人通常需要人工的協助才能完成長跨度任務。但現在,PaLM-E透過自主學習就可以搞定了。

例如,「從抽屜拿出洋芋片」這類指令中,就包含了多個計畫步驟,以及來自機器人攝影機的視覺回饋。
經過端對端訓練的PaLM-E,可以直接從像素開始規劃機器人。由於模型被整合到控制迴路中,所以機器人在拿薯片的過程中,對途中的干擾都有穩健性。
人類:給我來點薯片。
機器人:1. 走到抽屜旁2.打開最上面的抽屜3. 從最上面的抽屜裡拿起綠色的薯片4.放在櫃檯上。

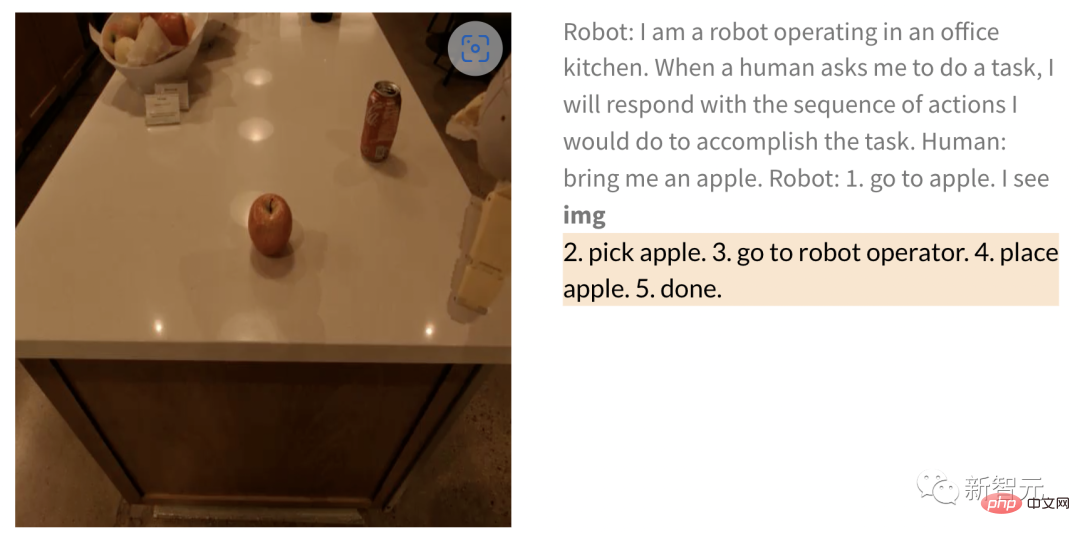
同樣,讓機器人去拿一個蘋果時,給出圖片後,機器人執行任務步驟如下——
人類:給我拿一個蘋果。
機器人:1.走向蘋果 2.拿起蘋果 3.把它拿給操作員 4.放下蘋果 5.完成。
除了執行長跨度任務,PaLM-E可以讓機器人執行規劃任務,例如排列積木。
研究人員根據視覺和語言輸入成功地進行多階段的計劃,並結合了長時間範圍的視覺反饋,進而讓模型能夠成功地規劃一個長週期的任務“將積木依顏色分類到不同的角落」。
如下,在排列組合上,機器人化身為多面手,依顏色將積木排序。
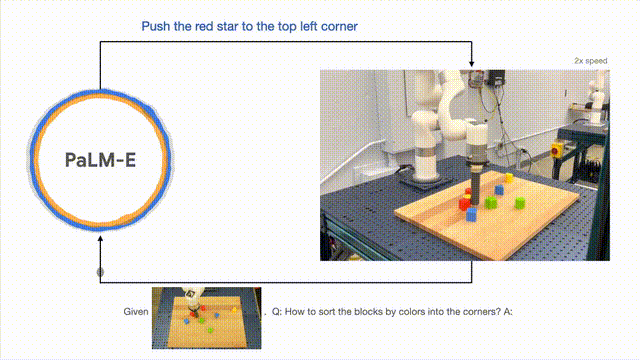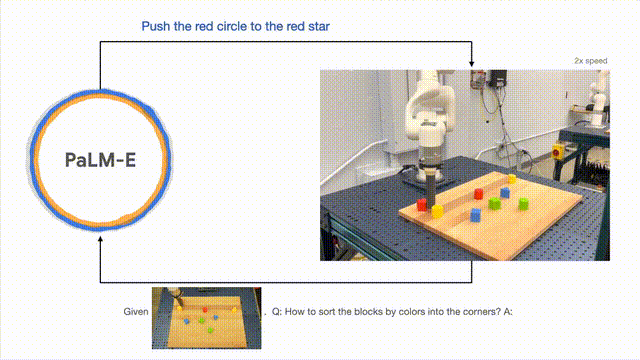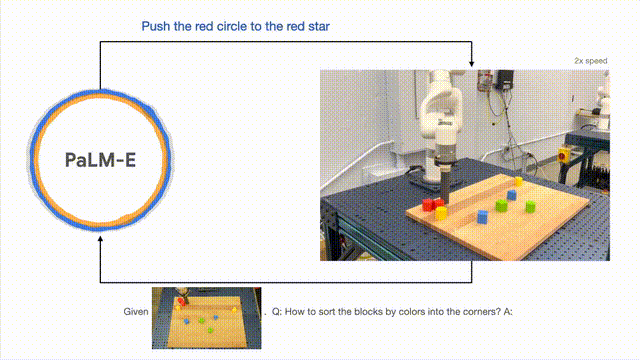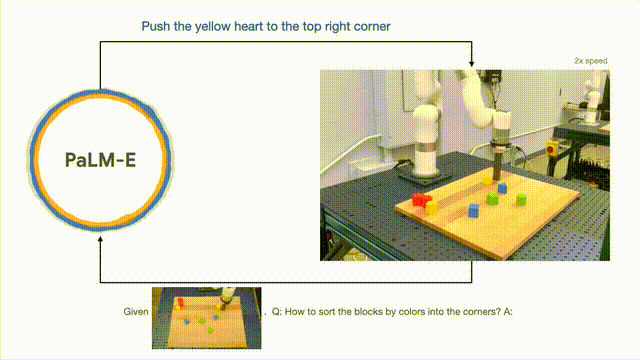
模型的泛化方面,PaLM- E控制的機器人可以把紅色積木移到咖啡杯的旁邊。
值得一提的是,資料集只包含有咖啡杯的三個演示,但其中沒有一個包括紅色的積木塊。

類似的,雖然模型從未見過烏龜,但照樣可以順利地把綠色積木推到烏龜旁邊

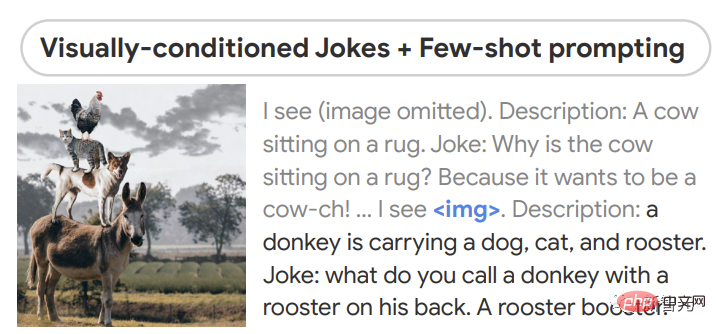
在零樣本推理方面,PaLM-E可以在給定圖像的情況下講述笑話,並展示了包括感知,基於視覺的對話和計劃在內的能力。
多張圖的關係,PaLM-E也整得很明白,比如圖一(左)在圖二(右)的哪個位置。

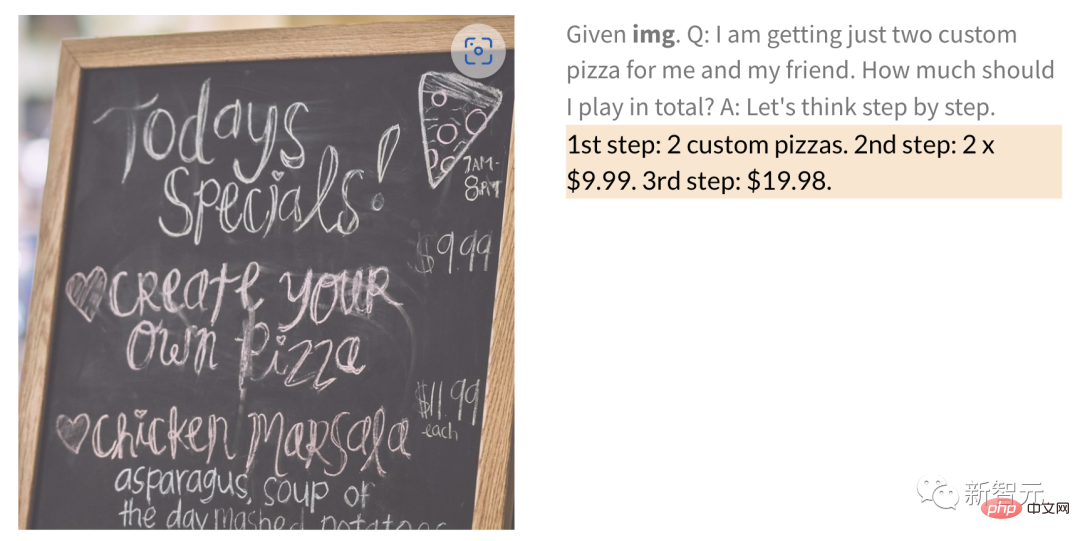
此外,PaLM-E還可以在給定帶有手寫數字的圖像中執行數學運算。
例如,如下手寫餐廳的菜單圖,2張披薩要多少錢,PaLM-E就直接給算出來了。
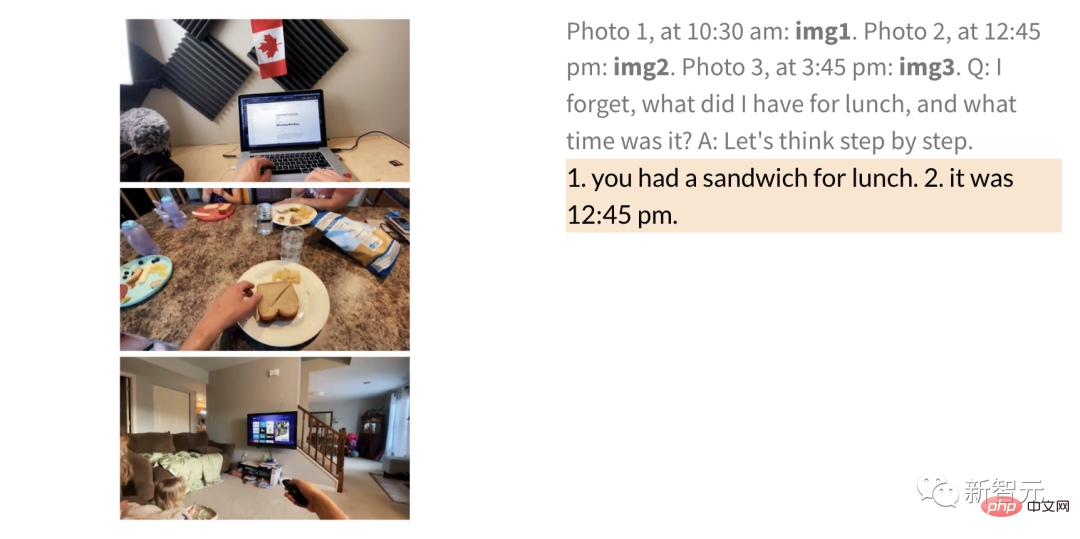
以及一般的QA和標註等多種任務。
最後,研究結果也表明,凍結語言模型是通往完全保留其語言能力的通用具身多模態模型的可行之路。
但同時,研究人員也發現了解凍模型的替代路線,即擴大語言模型的規模可以顯著減少災難性遺忘。
以上是谷歌發布了史上最大的通用模型PaLM-E,該模型擁有5620億個參數,被稱為終結者中最強大的大腦,並且可以透過圖像與機器人進行交互的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















