

ChatGPT核心方法可用於AI繪畫,效果飛升47%,通訊作者:已跳槽OpenAI

ChatGPT中有這樣一個核心訓練方法,名叫「人類回饋強化學習(RLHF)」。
它可以讓模型更安全、輸出結果更遵循人類意圖。
現在,來自GoogleResearch和UC伯克利的研究人員發現,將該方法用在AI繪畫上,「治療」圖像跟輸入不完全匹配的情況,效果也奇好——
可以實現高達47%的改進。

△ 左為Stable Diffusion,右為改進後效果
這一刻,AIGC領域中兩類大火的模型,似乎找到了某種“共鳴」。
如何將RLHF用於AI繪畫?
RLHF,全名為“Reinforcement Learning from Human Feedback”,是OpenAI和DeepMind於2017年合作開發的一種強化學習技術。
如同其名,RLHF就是用人類對模型輸出結果的評價(即回饋)來直接優化模型,在LLM中,它可以使得「模型價值」更符合人類價值。
而在AI圖像生成模型中,它可以讓生成圖像與文字提示得到充分對齊。
具體而言,首先,收集人類回饋資料。
在這裡,研究人員一共生成了27000餘個“文字圖像對”,然後讓一些人類來評分。
為了簡單起見,文字提示只包括以下四個類別,分別關乎數量、顏色、背景和混合選項;人類的回饋則只分「好」、「壞」與「不知道(skip) 」。

其次,學習獎勵函數。
這一步,就是利用剛剛獲得的人類評估所組成的資料集,訓練出獎勵函數,然後用該函數來預測人類對模型輸出的滿意度(公式紅色部分)。
這樣,模型就知道自己的結果究竟有幾分符合文字。
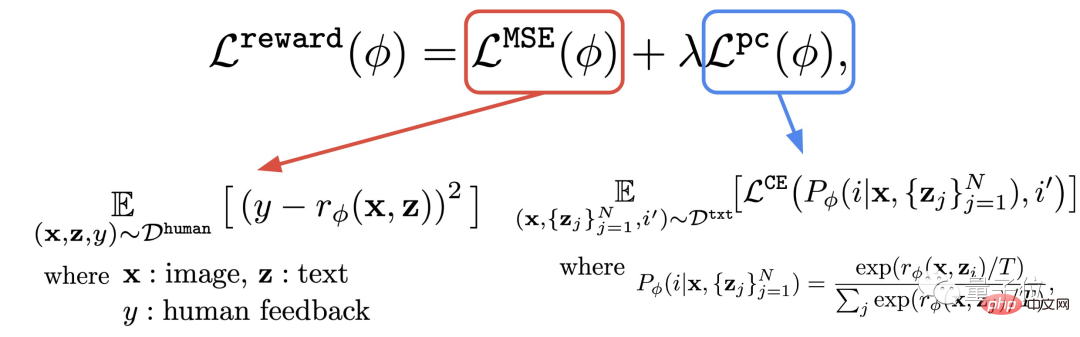
除了獎勵函數,作者也提出了一個輔助任務(公式藍色部分)。
也就是當圖像生成完成後,模型再給一堆文本,但其中只有一個是原始文本,讓獎勵模型「自己檢查」圖像是否跟該文本相符。
這種逆向操作可以讓效果得到「雙重保險」(可以輔助下圖中的step2進行理解)。
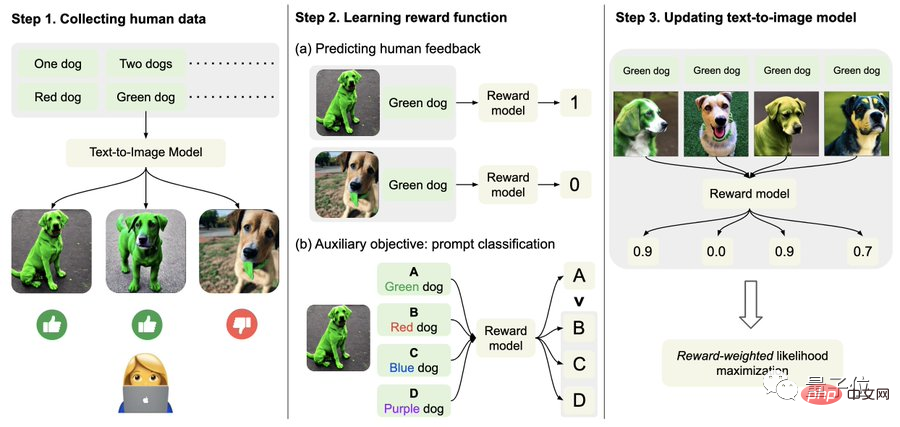
最後,就是微調了。
即透過獎勵加權最大似然估計(reward-weighted likelihood maximization)(下公式第一項),更新文字-圖像生成模型。
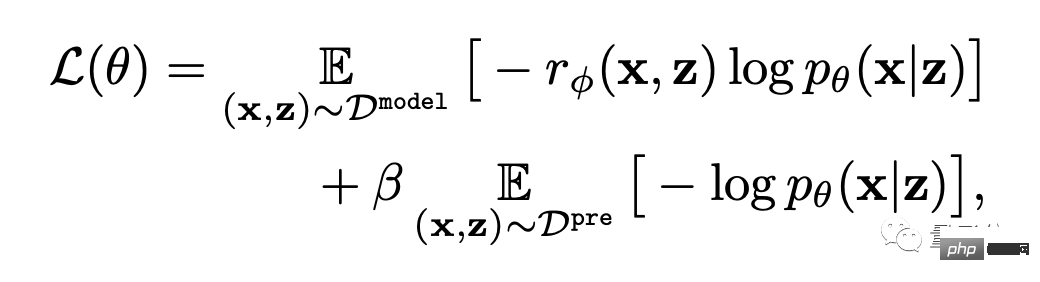
為了避免過度擬合,作者對預訓練資料集上的NLL值(公式第二項)進行了最小化。這種做法類似於InstructionGPT (ChatGPT的「直系前輩」)。
效果提升47%,但清晰度下滑5%
如下一系列效果所示,相比原始的Stable Diffusion,用RLHF微調過後的模型可以:
(1)更正確地get文字裡的“兩隻”和“綠色”;

#(2)不會忽略“海”作為背景的要求;
(3)想要紅老虎,能給出「更紅」的結果。
從具體數據來看,微調後的模型人類滿意度為50%,相比原來的模型(3%),得到了47%的提升。
不過,代價是失去了5%的影像清晰度。
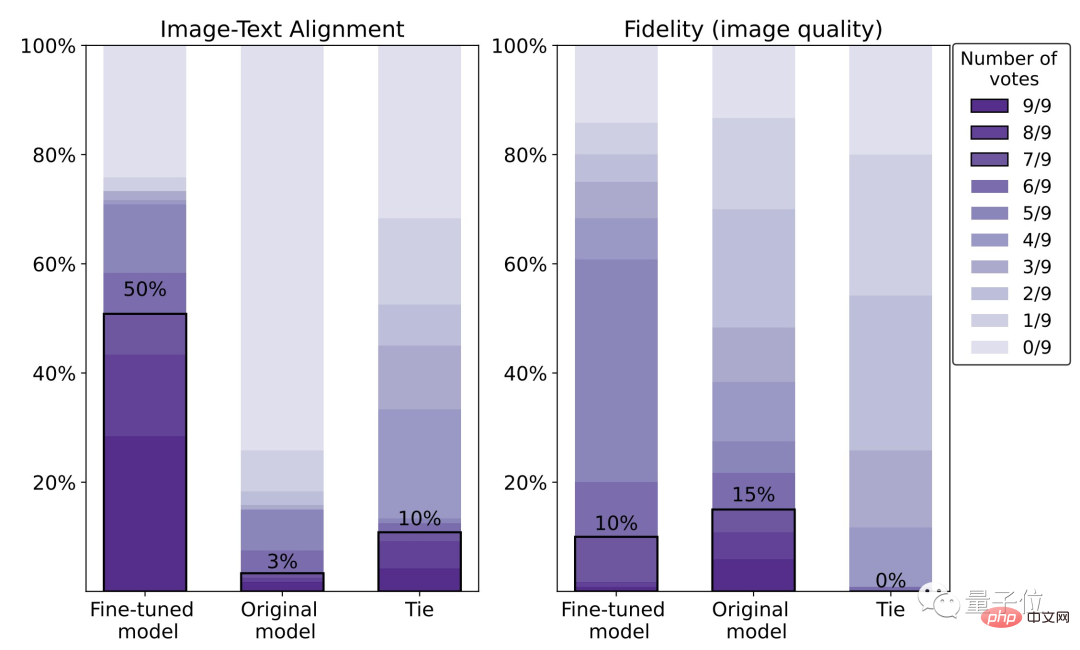
從下圖我們也能很清楚的看到,右邊的狼明顯比左邊的糊一些:
對此,作者表示,使用更大的人類評估資料集和更好的最佳化 (RL) 方法,可以改善這種情況。
關於作者
本文總共9位作者。

一作為GoogleAI研究科學家Kimin Lee,韓國科學技術院博士,博士後研究在UC柏克萊大學展開。

華人作者三位:
#Liu Hao,UC柏克萊正在讀博士生,主要研究興趣為回饋神經網路。
Du Yuqing,同UC柏克萊博士在讀,主要研究方向為無監督強化學習方法。
Shixiang Shane Gu (顧世翔),通訊作者,本科師從三巨頭之一Hinton,博士畢業於劍橋大學。

△ 顧世翔
值得一提的是,寫這篇文章時他還是谷歌人,如今已經跳槽至OpenAI,並在那裡直接向ChatGPT負責人報告。
論文網址:
https://arxiv.org/abs/2302.12192
參考連結:[1]https://www.php .cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
###[2]https://openai.com/blog/instruction-following/###以上是ChatGPT核心方法可用於AI繪畫,效果飛升47%,通訊作者:已跳槽OpenAI的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
本指南將指導您學習如何在Debian系統中使用Syslog。 Syslog是Linux系統中用於記錄系統和應用程序日誌消息的關鍵服務,它幫助管理員監控和分析系統活動,從而快速識別並解決問題。一、Syslog基礎知識Syslog的核心功能包括:集中收集和管理日誌消息;支持多種日誌輸出格式和目標位置(例如文件或網絡);提供實時日誌查看和過濾功能。二、安裝和配置Syslog(使用Rsyslog)Debian系統默認使用Rsyslog。您可以通過以下命令安裝:sudoaptupdatesud
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
