

阿里可解釋性推薦演算法應用

一、推薦業務簡介
首先介紹阿里健康的業務背景和對現狀的分析。
1、推薦場景展示
#可解釋性推薦,舉例而言,如下圖中當網“根據您瀏覽的商品推薦」(告訴用戶推薦的理由)及淘寶網「1000 居家控收藏」、「2000 數位達人加購」皆屬於可解釋性推薦,透過提供使用者資訊來說明推薦商品的原因。

左圖中的可解釋推薦,有一個較為簡單的實作思維:推薦主要包含召回和排序兩大主要模組,且召回往往涉及多路召回,使用者行為召回也是常見的一種召回方式。可對經過排序模組後的商品進行判定,若商品來自用戶行為召回池,則可在推薦的商品後面添加相應的推薦註釋。但此方法往往準確率精度不高,並未提供使用者較多有效資訊。
比較而言,右圖範例中可由對應的解釋性文字提供給使用者更多的信息,如產品類別資訊等,但該方法往往需要較多的人工幹預,在特徵到文本輸出環節進行人工處理。
而對於阿里健康,由於行業的特殊性,相比於其它場景,可能存在更多的限制。相關條例規定「三品一械」(藥品、保健食品、特殊醫藥用途配方食品及醫療器材)廣告中不允許出現「熱銷、排序、推薦」等文字訊息。因此阿里健康需在遵從上述條例的前提下,結合阿里健康的業務對產品進行推薦。
2、阿里健康的業務狀況
#阿里健康現有阿里健康自營店鋪和阿里健康產業店鋪兩類店鋪。其中自營店家主要含有大型藥局、海外店和醫藥旗艦店,而阿里健康產業店家主要涉及各品類旗艦店及私營店鋪。
就產品而言,阿里健康主要涵蓋常規商品、OTC 商品、處方藥三大類產品。常規商品,即定義為不是藥品的商品,對於常規商品的推薦,可展示較多信息,如品類銷售 top,超過 n 人收藏/購買等信息。而對於 OTC 及處方藥這類藥品商品的推薦,則受到相應條例的約束,需更加結合用戶關注點進行推薦,如功能主治、用藥週期、使用禁忌等資訊。
上述提到的可用於藥品推薦文字的資訊主要有以下幾大來源:
- #商品評論(不含處方藥)。
- 商品詳情頁。
- 說明書等資訊。
二、基礎資料準備
#第二部分主要介紹商品的特徵是如何提取及編碼的。
1、商品的特徵抽取
#下面以藿香正氣水為例,展示如何從上述數據來源進行關鍵特徵的擷取:

#商家為增大產品的召回,往往會在標題中加入較多的關鍵字,因此可透過商家自備的標題描述進行關鍵字的抽取。
#- 產品詳情圖
#可藉用OCR 技術基於商品的詳情圖中提取到商品的功能主治、核心賣點等更為全面的商品資訊。
- 使用者評論資料
#透過使用者基於某功能情感的得分,可對商品的對應關鍵字進行加權減權操作。如對於「防中暑」的藿香正氣水而言,可透過使用者評論中「防中暑」情感的打分,並對其對應的標籤進行對應的權重處理。
- 藥物說明書
透過上述多種資料來源,可抽取資訊中的關鍵字並建立關鍵字庫。由於抽取的關鍵字有較多重複、同義的情況,需對同義詞進行合併,並結合人工校驗,產生標準詞庫。最終可形成單一商品-標籤清單的關係,可用於後續編碼及在模型中的使用。
2、特徵編碼
以下介紹如何編碼特徵。特徵編碼主要基於 word2vec 的方式進行 word embedding。
真實的歷史購買商品對資料可分為下述三大類:
(1)共同瀏覽商品對:用戶在一段時間(30 min)內依序點擊的使用者定義為共同瀏覽資料。
(2)共同購買商品對:共同購買廣義而言,可定義為同一主訂單下子訂單間互夠為共同購買商品對;但考慮到實際用戶下單習慣,定義一定時間(10 min)內同一用戶的下單產品資料。
(3)瀏覽後購買商品對:#同一用戶在點擊A 後又購買了B 產品,A 與B 互為瀏覽後購買數據。
透過對歷史資料進行分析,發現瀏覽後購買資料對商品間相似度較高:往往藥品核心功能相似,僅存在輕微不同,可定義為相似產品對,即為正樣本。
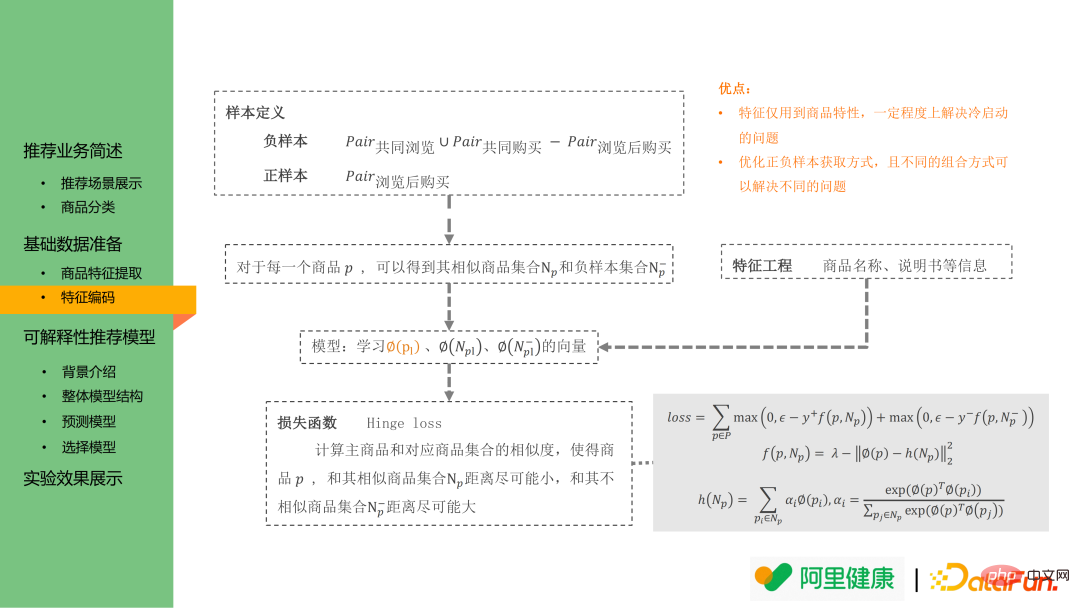
特徵編碼模型仍基於 word2vec 的想法:主要是希望具有相似的產品/標籤間embedding 更接近。因此 word embedding 中正樣本定義為上述提到的瀏覽後購買商品對;負樣本則為共同瀏覽商品對和共同購買商品對的並集減去瀏覽後購買的商品對數據。
基於上述正負樣本對的定義,利用 hinge loss,可以學習每個商品的embedding 用於i2i 回想階段,也可同本場景中學習出標籤/關鍵字的embedding,作為後續模型的輸入。
上述方法有兩個優點:
#(1)特徵只用到產品特性,能在一定程度上解決冷啟動問題:對於新上架的商品,仍可透過其標題、商品詳情圖等資訊取得相應標籤。
(2)正、負樣本的定義可用於不同的推薦場景:如若將正樣本定義為共同購買產品對,則訓練出來的商品 embedding 可用於「搭配購買推薦」場景。
三、可解釋推薦模型
1、可解釋模型背景介紹
業界現有較為成熟的可解釋型別主要包含內建可解釋性( model-intrinsic )和模型無關可解釋性( model-agnostic )兩大類。
其中內建可解釋性模型,如常見的XGBoost 等,但XGBoost 雖為端到端模型,但其特徵重要度是基於整體資料集而言,不符合「千人千面」的個人化推薦要求。
而模型無關可解釋性主要是指重建邏輯模擬模型,並對模型進行解釋,如 SHAP,其可對單一 case 進行分析,可判定出預測值與實際值不同的原因。但 SHAP 複雜度較高,較為耗時,經過效能改造後無法滿足線上效能需求。
因此需建構一個端到端,且能對每個樣本進行特徵重要度輸出的模型。
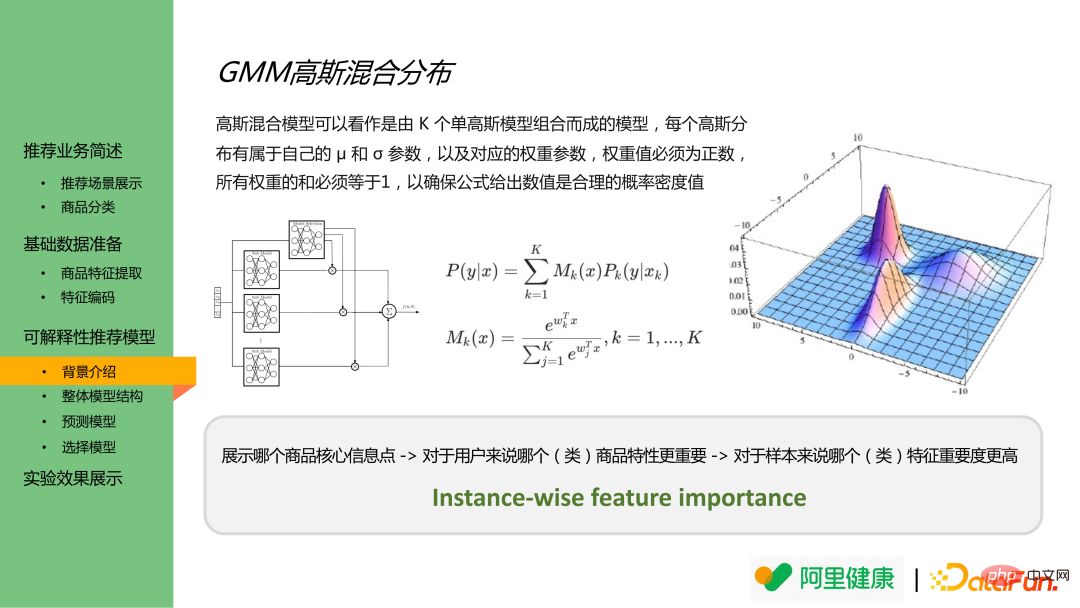
而高斯混合分佈是多個高斯分佈的組合,可輸出某個分佈的結果值及每個樣本結果屬於某個分佈的機率。因此可進行類比,將分類後的特徵理解為具有不同的分佈的數據,分別對對應特徵的預測結果 及此預測在實際結果中的重要程度 進行建模。
2、模型結構圖
下圖為整體的模型結構圖,左圖為選擇模型,可用作特徵重要度的展示,右圖為特徵對應的預測模型。
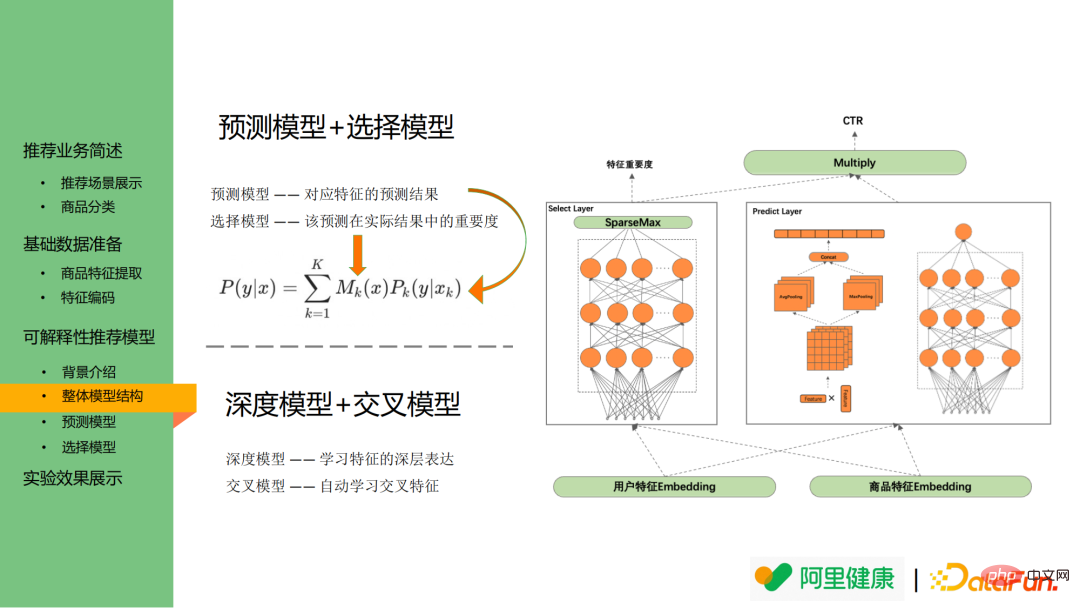
具體而言,預測模型用於預測對應特徵預測/點擊的機率,而選擇模型則用來說明哪些特徵分佈是比較重要、可用於作為解釋性文字的展示。
3、預測模型
下圖為預測模型的結果圖,預測模型主要藉鑒了 DeepFM 的思想,包含一個深度模型和交叉模型。深度模型主要用於學習特徵的深層表達,而交叉模型則用於學習交叉特徵。在
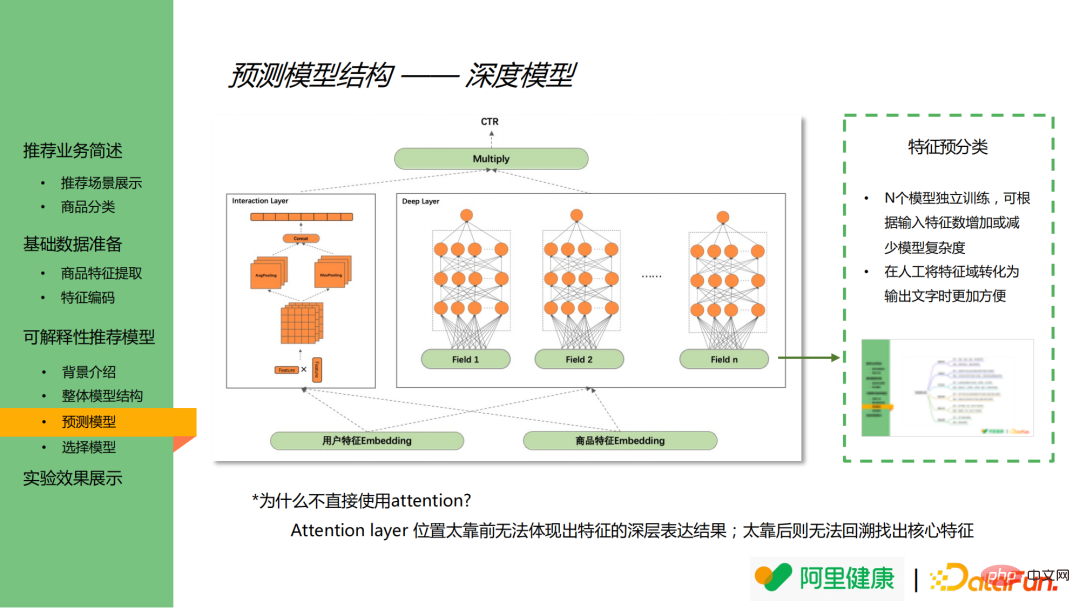
深度模型中,先提前將特徵分組(假設共有N 組),如對價格、類別等相關的特徵合併為價格、類別大類(圖中field 欄位),並對每一組特徵進行單獨的模型訓練,並得到基於該組特徵的模型結果。
將模型提前進行合併分組,具有下述兩個優點:
(1)透過N 個模型的獨立訓練,可透過輸入特徵的增減改變模型的複雜度,從而影響線上性能。
(2)對特徵的合併分組可明顯減少特徵量級,使人工將特徵域轉換為文字時更加方便。
值得一提的是,attention 層理論上也可用於特徵重要度的分析,但在本模型中未引入attention 的原因主要如下:
(1)若將attention layer 放在太前位置則無法體現出特徵深層表達的結果;
(2)若將attention layer 放在較為靠後的位置,則無法回溯、無法找出核心特徵。
而對於預測模型:
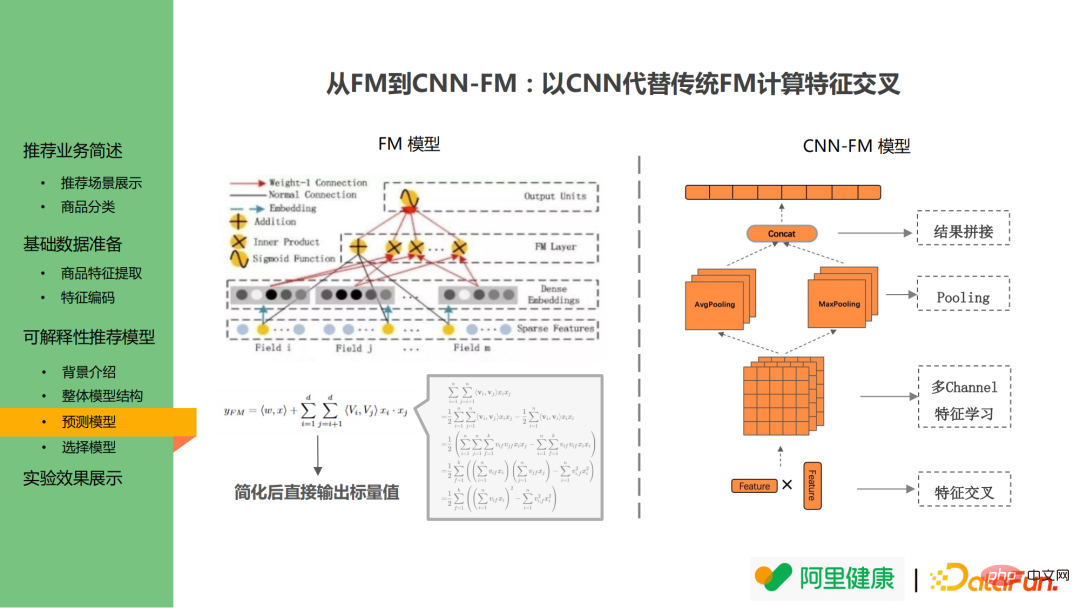
其交叉層並未沿用 FM 模型而是採用 CNN 取代 DeepFM 中 FM 結構。 FM 模型學習特徵兩兩交叉結果,並透過數學公式直接計算兩兩交叉結果,避免計算時的維度爆炸,但其導致無法回溯特徵重要度,因此在交叉模型中引入CNN 替代原有結構:採用N個特徵進行相乘以實現特徵交叉,再進行CNN 的對應操作。這樣使得特徵值在輸入後經過 pooling,concat 等操作後,仍可回溯。
除上述優點外,此方法還有一個優點:雖然現有版本僅是單一特徵到單一描述文字的轉化,但仍希望未來能實現多特徵互動的轉化。舉例而言,如果某用戶習慣購買100元低價產品,但若有原價50,000元商品打折至500出售,而用戶購買了該商品,模型可能因此將其定義為高消費用戶。但實際上,可能是因為高端品牌 高折扣雙重因素導致的用戶下單,因此需考慮組合邏輯。而對於 CNN-FM 模型而言,後期可直接利用 feature map 進行特徵組合的輸出。
4、選擇模型
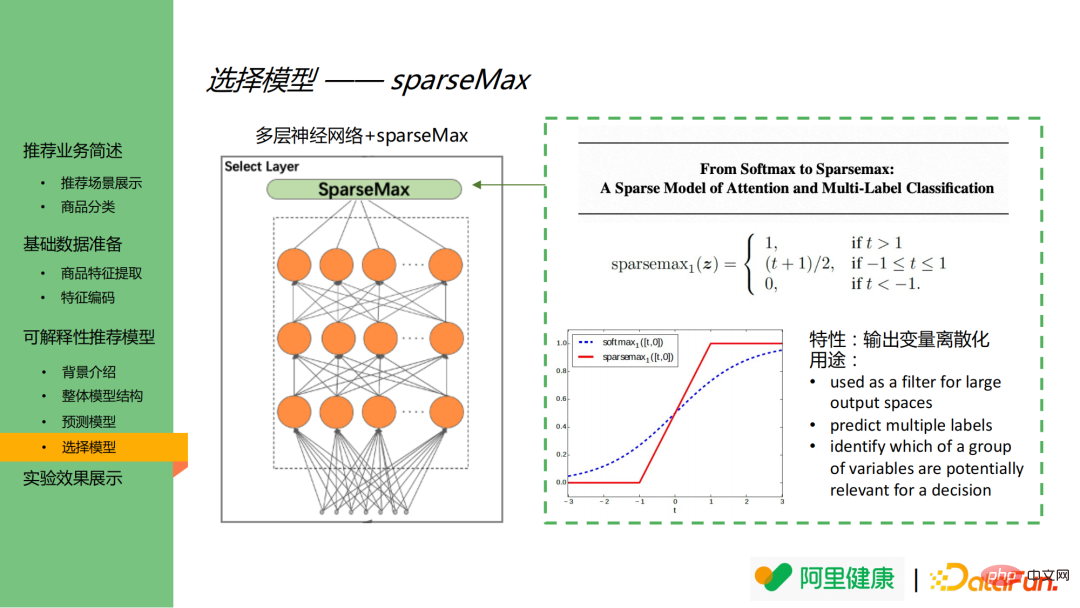
#選擇模型由 MLP 和 sparseMax 組成。值得一提的是,選擇模型中啟動函數採用的是 sparsemax 而不是更常見的 softmax。影像右邊依序是 sparsemax 的函數定義及 softmax 與 sparsemax 的函數比較圖。
從右下的圖中可看出,softmax 對重要度較低的輸出節點仍會賦予較小值,在該場景下會導致特徵維度爆炸,且容易造成重要特徵與不重要特徵間的輸出沒有區分度。而 sparseMax 可以將輸出離散化,最終僅輸出較為重要的特徵。
四、實驗效果展示
1、實驗數據說明
線上效果數據主要來自於大藥房首頁曝光-點擊數據,為避免過擬合,也引入了部分其他場景曝光-點擊數據,數據比例為4:1。
2、離線指標
在離線場景下,模型 AUC 為0.74。
3、線上指標
由於線上場景已有CTR 模型,考慮新版演算法除更換模型外,還會展示對應的解釋性文字,未控制變量,因此本次實驗並未直接採用AB test。而是當且僅當線上 CTR 模型及新版演算法預測值均高於特定閾值時,才會展示推薦理由的文字。上線後,新版演算法 PCTR 提升 9.13%,UCTR 提升 3.4%。
五、問答環節
Q1:產生標準字庫、同義詞合併採用什麼模型?效果如何?還需要多少人工校準工作?
A1:同義詞合併時會利用模型學習文本標準,並提供出基礎字庫。但實際上人工校驗的比重較大。因為健康/藥品的業務場景,對演算法準確度的要求較高,可能個別字的偏差會造成實際意義的較大偏離。整體而言人工校驗的比重會比演算法大。
Q2:LIME 模型可以用來當作推薦模型的解釋嗎?
A2:可以。還有很多其他模型可以做可解釋推薦。因為分享者對 GMM 整體熟悉度高,所以選擇上述模型。
Q3:選擇模型和預測模型怎麼連動的?
A3:假設有N 組特徵組,預測模型、選擇模型都會產生1*N 維的向量,最終將預測模型和選擇模型的結果進行相乘(multiple),實現連動。
Q4:可解釋文字如何產生?
A4:目前還沒有合適的機器學習模型進行文字生成,主要還是採用以人工為基礎的方式。如價格是使用者關心的核心特徵,則會選擇對歷史資料進行分析,建議出性價比較高的產品。但目前而言,主要還是人工操作。希望未來能有合適的模型進行文字生成,但考慮到業務場景的特殊性,模型生成的文本仍需要人工進行校驗。
Q5:模型的篩選邏輯?
A5:對於 GMM 中子分佈的選擇,主要透過 GMM 中 Mk 對分佈進行學習,並基於 Mk 的高低值進行篩選。
Q6:字庫的標註有屬性型別嗎?
A6:對加屬性詞,如對產品描述中的疾病、功能、使用禁忌等進行達標。
#Q7:可解釋文字可否使用插槽填滿的想法?即準備不同模板,依照字詞的權重選擇不同模板?
A7:可以,現在的實際用法就是要填滿插槽位。
今天的分享就到這裡,謝謝大家。
以上是阿里可解釋性推薦演算法應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:明確監督BEVFormer結構,提升長尾偵測性能
Mar 26, 2024 pm 12:41 PM
寫在前面&筆者的個人理解目前,在整個自動駕駛系統當中,感知模組扮演了其中至關重要的角色,行駛在道路上的自動駕駛車輛只有通過感知模組獲得到準確的感知結果後,才能讓自動駕駛系統中的下游規控模組做出及時、正確的判斷和行為決策。目前,具備自動駕駛功能的汽車中通常會配備包括環視相機感測器、光達感測器以及毫米波雷達感測器在內的多種數據資訊感測器來收集不同模態的信息,用於實現準確的感知任務。基於純視覺的BEV感知演算法因其較低的硬體成本和易於部署的特點,以及其輸出結果能便捷地應用於各種下游任務,因此受到工業
 使用C++實現機器學習演算法:常見挑戰及解決方案
Jun 03, 2024 pm 01:25 PM
使用C++實現機器學習演算法:常見挑戰及解決方案
Jun 03, 2024 pm 01:25 PM
C++中機器學習演算法面臨的常見挑戰包括記憶體管理、多執行緒、效能最佳化和可維護性。解決方案包括使用智慧指標、現代線程庫、SIMD指令和第三方庫,並遵循程式碼風格指南和使用自動化工具。實作案例展示如何利用Eigen函式庫實現線性迴歸演算法,有效地管理記憶體和使用高效能矩陣操作。
 探究C++sort函數的底層原理與演算法選擇
Apr 02, 2024 pm 05:36 PM
探究C++sort函數的底層原理與演算法選擇
Apr 02, 2024 pm 05:36 PM
C++sort函數底層採用歸併排序,其複雜度為O(nlogn),並提供不同的排序演算法選擇,包括快速排序、堆排序和穩定排序。
 人工智慧可以預測犯罪嗎?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智慧可以預測犯罪嗎?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智慧(AI)與執法領域的融合為犯罪預防和偵查開啟了新的可能性。人工智慧的預測能力被廣泛應用於CrimeGPT(犯罪預測技術)等系統,用於預測犯罪活動。本文探討了人工智慧在犯罪預測領域的潛力、目前的應用情況、所面臨的挑戰以及相關技術可能帶來的道德影響。人工智慧和犯罪預測:基礎知識CrimeGPT利用機器學習演算法來分析大量資料集,識別可以預測犯罪可能發生的地點和時間的模式。這些資料集包括歷史犯罪統計資料、人口統計資料、經濟指標、天氣模式等。透過識別人類分析師可能忽視的趨勢,人工智慧可以為執法機構
 改進的檢測演算法:用於高解析度光學遙感影像目標檢測
Jun 06, 2024 pm 12:33 PM
改進的檢測演算法:用於高解析度光學遙感影像目標檢測
Jun 06, 2024 pm 12:33 PM
01前景概要目前,難以在檢測效率和檢測結果之間取得適當的平衡。我們研究了一種用於高解析度光學遙感影像中目標偵測的增強YOLOv5演算法,利用多層特徵金字塔、多重偵測頭策略和混合注意力模組來提高光學遙感影像的目標偵測網路的效果。根據SIMD資料集,新演算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在偵測結果和速度之間達到了更好的平衡。 02背景&動機隨著遠感技術的快速發展,高解析度光學遠感影像已被用於描述地球表面的許多物體,包括飛機、汽車、建築物等。目標檢測在遠感影像的解釋中
 九章雲極DataCanvas多模態大模型平台的實踐與思考
Oct 20, 2023 am 08:45 AM
九章雲極DataCanvas多模態大模型平台的實踐與思考
Oct 20, 2023 am 08:45 AM
一、多模態大模型的歷史發展上圖這張照片是1956年在美國達特茅斯學院舉行的第一屆人工智慧workshop,這次會議也被認為拉開了人工智慧的序幕,與會者主要是符號邏輯學屆的前驅(除了前排中間的神經生物學家PeterMilner)。然而這套符號邏輯學理論在隨後的很長一段時間內都無法實現,甚至到80年代90年代還迎來了第一次AI寒冬期。直到最近大語言模型的落地,我們才發現真正承載這個邏輯思維的是神經網絡,神經生物學家PeterMilner的工作激發了後來人工神經網絡的發展,也正因為此他被邀請參加了這個
 演算法在 58 畫像平台建置中的應用
May 09, 2024 am 09:01 AM
演算法在 58 畫像平台建置中的應用
May 09, 2024 am 09:01 AM
一、58畫像平台建置背景首先和大家分享下58畫像平台的建造背景。 1.傳統的畫像平台傳統的想法已經不夠,建立用戶畫像平台依賴數據倉儲建模能力,整合多業務線數據,建構準確的用戶畫像;還需要數據挖掘,理解用戶行為、興趣和需求,提供演算法側的能力;最後,還需要具備數據平台能力,有效率地儲存、查詢和共享用戶畫像數據,提供畫像服務。業務自建畫像平台和中台類型畫像平台主要區別在於,業務自建畫像平台服務單條業務線,按需定制;中台平台服務多條業務線,建模複雜,提供更為通用的能力。 2.58中台畫像建構的背景58的使用者畫像
 即時加SOTA一飛沖天! FastOcc:推理更快、部署友善Occ演算法來啦!
Mar 14, 2024 pm 11:50 PM
即時加SOTA一飛沖天! FastOcc:推理更快、部署友善Occ演算法來啦!
Mar 14, 2024 pm 11:50 PM
寫在前面&筆者的個人理解在自動駕駛系統當中,感知任務是整個自駕系統中至關重要的組成部分。感知任務的主要目標是使自動駕駛車輛能夠理解和感知周圍的環境元素,如行駛在路上的車輛、路旁的行人、行駛過程中遇到的障礙物、路上的交通標誌等,從而幫助下游模組做出正確合理的決策和行為。在一輛具備自動駕駛功能的車輛中,通常會配備不同類型的信息採集感測器,如環視相機感測器、雷射雷達感測器以及毫米波雷達感測器等等,從而確保自動駕駛車輛能夠準確感知和理解周圍環境要素,使自動駕駛車輛在自主行駛的過程中能夠做出正確的決斷。目
