
語音辨識源自於 20 世紀 50 年代早期在貝爾實驗室所做的研究。早期語音辨識系統僅能辨識單一說話者以及只有約十幾個單字的詞彙量。現代語音辨識系統已經取得了很大進步,可以識別多個演講者,並且擁有識別多種語言的龐大詞彙表。
語音辨識的首要部分當然是語音。透過麥克風,語音便從實體聲音轉換為電訊號,然後透過類比數位轉換器轉換為資料。一旦被數位化,就可適用若干種模型,將音訊轉錄為文字。
大多數現代語音辨識系統都依賴隱馬可夫模型(HMM)。其工作原理為:語音訊號在非常短的時間尺度上(例如 10 毫秒)可被近似為靜止過程,即其統計特性不隨時間變化的過程。
許多現代語音辨識系統會在 HMM 辨識之前使用神經網絡,透過特徵變換和降維的技術來簡化語音訊號。也可以使用語音活動偵測器(VAD)將音訊訊號減少到可能僅包含語音的部分。
幸運的是,對於 Python 用戶而言,有些語音辨識服務可透過 API 在線上使用,其中大部分也提供了 Python SDK。
PyPI中有一些現成的語音辨識軟體包。其中包括:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit
一些軟體包(如wit 和apiai )提供了一些超出基本語音辨識的內建功能,如辨識說話者意圖的自然語言處理功能。其他軟體包,如Google雲端語音,則專注於語音向文字的轉換。
其中,SpeechRecognition 就因為便於使用而脫穎而出。
識別語音需要輸入音頻,而在 SpeechRecognition 中檢索音頻輸入是非常簡單的,它無需構建訪問麥克風和從頭開始處理音頻文件的腳本,只需幾分鐘即可自動完成檢索並運行。
SpeechRecognition 相容於 Python2.6 , 2.7 和 3.3 ,但若在 Python 2 中使用還需要一些額外的安裝步驟。大家可使用pip 指令從終端機安裝SpeechRecognition:pip3 install SpeechRecognition
安裝完成後可以開啟解釋器視窗進行驗證安裝:

#附註:不要關閉此會話,在後幾個步驟中你將要使用它。
若處理現有的音訊文件,只需直接呼叫 SpeechRecognition ,注意具體的用例的一些依賴關係。同時注意,安裝 PyAudio 套件來取得麥克風輸入
SpeechRecognition 的核心就是辨識器類別。
Recognizer API 主要目是識別語音,每個API 都有多種設定和功能來識別音訊來源的語音,這裡我選擇的是recognize_sphinx(): CMU Sphinx - requires installing PocketSphinx(支援離線的語音辨識)
那麼我們就需要透過pip指令來安裝PocketSphinx,在安裝過程中也容易出現一大串紅色字型的錯誤。
下載相關的音訊檔案儲存到特定的目錄(直接儲存到ubuntu桌面)
注意:
AudioFile 類別可以透過音訊檔案的路徑進行初始化,並提供用於讀取和處理檔案內容的上下文管理器介面。
SpeechRecognition 目前支援的檔案類型有:
WAV: 必須是PCM/LPCM 格式
AIFF
AIFF-CFLAC: 必須是初始FLAC 格式;OGG-FLAC 格式不可用
(1)開啟終端機
(2)進入語音測試檔案所在目錄(部落客的是桌面)
(3)開啟python解釋器
(4)依照下圖輸入相關指令
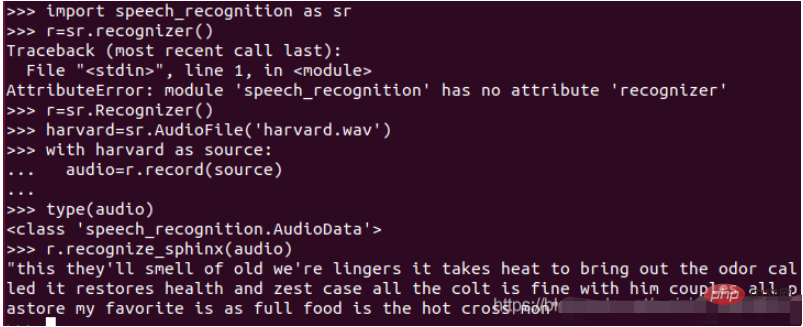
透過嘗試轉錄效果並不好,我們可以透過嘗試呼叫 Recognizer 類別的adjust_for_ambient_noise()指令。
若要使用 SpeechRecognizer 存取麥克風則必須安裝 PyAudio 軟體包。
如果使用的是基於Debian的Linux(如Ubuntu ),則可使用apt 安裝PyAudio:sudo apt-get install python-pyaudio python3-pyaudio安裝完成後可能仍需要啟用pip3 install pyaudio ,尤其是在虛擬情況下運行。
在安裝完pyaudio的情況下可以透過python實現語音錄入產生相關檔案。
pocketsphinx的使用注意:
支援檔案格式:wav
音訊檔案的解碼要求:16KHZ,單聲道
利用python實作錄音並產生相關檔案程式碼如下:
from pyaudio import PyAudio, paInt16
import numpy as np
import wave
class recoder:
NUM_SAMPLES = 2000
SAMPLING_RATE = 16000
LEVEL = 500
COUNT_NUM = 20
SAVE_LENGTH = 8
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
while True:
string_audio_data = stream.read(self.NUM_SAMPLES)
audio_data = np.fromstring(string_audio_data, dtype=np.short)
large_sample_count = np.sum(audio_data > self.LEVEL)
print(np.max(audio_data))
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
save_buffer.append(string_audio_data )
else:
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")注意:在利用python解釋器實作時一定要注意空格! ! !
最後產生的檔案就在Python解釋器回話所在目錄下,可以透過play來播放測試一下,如果沒有安裝play可以透過apt指令來安裝。
在進行完以前的工作以後,我們對語音辨識的流程大概有了一定的了解,但是身為一個中國人總得做一個中文的語音辨識吧!
我們要在CMU Sphinx語音辨識工具包裡面下載對應的國語升學和語言模型。
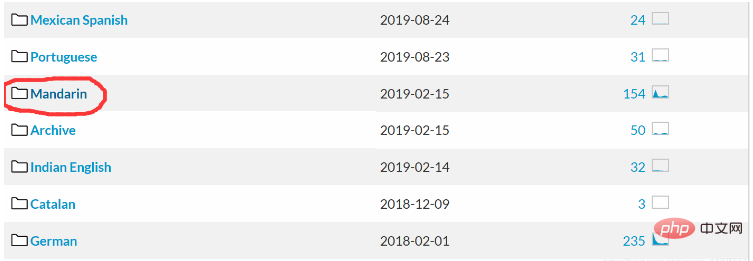
圖片中標記的是國語!下載相關的語音辨識工具包。
但我們要把zh_broadcastnews_64000_utf8.DMP轉換成language-model.lm.bin,再解壓縮zh_broadcastnews_16k_ptm256_8000.tar.bz2得到資料夾
借鏡剛才那位部落客的方法,在Ubuntu下找到speech_recognition資料夾。可能會有很多小夥伴找不到相關的資料夾,其實是在隱藏檔案下。大家可以點選資料夾右上角的三條槓。如下圖所示:

然後給顯示隱藏檔案打個勾,如下圖所示:

en-US改名為en-US-bak ,新建一個資料夾en-US,把解壓縮出來的zh_broadcastnews_ptm256_8000改成acoustic-model,把chinese.lm.bin#改成language -model.lm.bin,把pronounciation-dictionary.dic改後綴成dict,複製這三個檔案到en-US裡。同時把原來en-US檔目錄下的LICENSE.txt複製到現在的資料夾下。 最終該資料夾下有以下檔案:
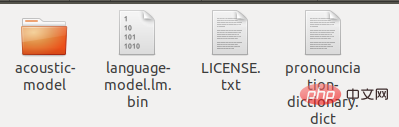
在該文件目錄下打開python解釋器輸入以下內容:
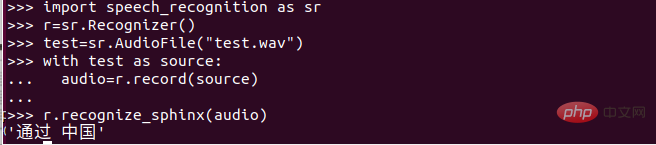
找到剛才複製的4個資料夾,有一個pronounciation-dictionary.dict的資料夾,開啟以後是以下內容:
 ##感覺這內容就是類似一個字典,很多用詞和平時溝通的用詞差距比較大。那我們改成我們習慣的用詞就可以啦!抱著試一試的想法,結果真的可以。識別效果真的不錯!
##感覺這內容就是類似一個字典,很多用詞和平時溝通的用詞差距比較大。那我們改成我們習慣的用詞就可以啦!抱著試一試的想法,結果真的可以。識別效果真的不錯!
(1)把圖片中紅色標記以上的內容繼續保留,紅色以下的內容刪除掉。當然處於保險考慮建議大家給該文件備份一下!
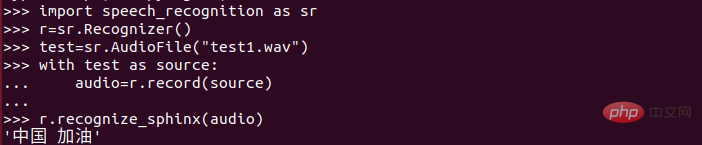
(2)給紅色線以下輸入自己想辨識的內容! (依照規則輸入,不同於拼音!!!)最近新型肺炎的情況不斷的變好,聽到最多的一句話就是「中國加油」那麼今天的內容就是將「中國加油」實現語音轉文字!希望能早日開學,哈哈哈哈。
 3)輸入以下內容:
3)輸入以下內容:
語音合成個人的理解就是文字轉語音。不過這句話中可以設定client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3 ,'pit':9,'per': 3})音量、音調、速度、男/女/蘿莉/逍遙。
以上是Linux下怎麼用python實現語音辨識功能的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















