

100:87:GPT-4心智碾壓人類!三大GPT-3.5變種難敵

GPT-4的心智理論,已經超越人類了!
最近,約翰霍普金斯大學的專家發現,GPT-4可以利用思維鏈推理和逐步思考,大大提升了自己的心智理論表現。

論文網址:https://arxiv.org/abs/2304.11490
#在某些測試中,人類的水平大概是87%,而GPT-4,已經達到了天花板等級的100%!
此外,在適當的提示下,所有經過RLHF訓練的模型都可以達到超過80%的準確率。
讓AI學會心智理論推理
我們都知道,關於日常生活場景的問題,很多大語言模型並不是很擅長。
Meta首席AI科學家、圖靈獎得主LeCun曾斷言:「在通往人類級別AI的道路上,大型語言模型就是一條歪路。要知道,連一隻寵物貓、寵物狗都比任何LLM有更多的常識,以及對世界的理解。」

也有學者認為,人類是隨著身體進化而來的生物實體,需要在物理和社會世界中運作才能完成任務。而GPT-3、GPT-4、Bard、Chinchilla和LLaMA等大語言模型都沒有身體。
所以除非它們長出人類的身體和感官,有著人類的目的的生活方式。否則它們根本不會像人類那樣理解語言。
總之,雖然大語言模型在許多任務中的優秀表現令人驚嘆,但需要推理的任務,對它們來說仍然很困難。
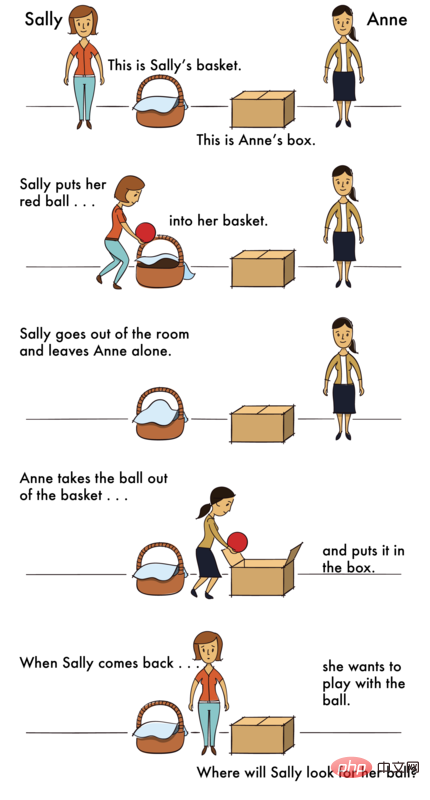
而尤其困難的,就是一種心智理論(ToM)推理。
為什麼ToM推理這麼困難呢?
因為在ToM任務中,LLM需要基於不可觀察的資訊(例如他人的隱藏心理狀態)進行推理,這些資訊都是需要從上下文推斷出的,並不能從表面的文本解析出來。
但是,對LLM來說,可靠執行ToM推理的能力又很重要。因為ToM是社會理解的基礎,只有具備ToM能力,人們才能參與複雜的社會交流,並預測他人的行動或反應。
如果AI學不會社會理解、get不到人類社會交往的種種規則,也就無法為人類更好地工作,在各種需要推理的任務中為人類提供有價值的見解。
怎麼辦呢?
專家發現,透過一種「上下文學習」,就能大大增強LLM的推理能力。
對於大於100B參數的語言模型來說,只要輸入特定的few-shot任務演示,模型效能就顯著增強了。
另外,即使在沒有演示的情況下,只要指示模型一步步思考,也會增強它們的推理性能。
為什麼這些prompt技術這麼管用?目前還沒有一個理論能夠解釋。
大語言模型參賽者
基於這個背景,約翰斯霍普金斯大學的學者評估了一些語言模型在ToM任務中的表現,並且探索了它們的表現是否可以透過逐步思考、few-shot學習和思考鏈推理等方法來提高。
參賽者分別是來自OpenAI家族最新的四個GPT模型——GPT-4以及GPT-3.5的三個變體,Davinci-2、Davinci-3和GPT-3.5-Turbo。
· Davinci-2(API名稱:text-davinci-002)是在人類寫的演示上進行監督微調訓練的。
· Davinci-3(API名稱:text-davinci-003)是Davinci-2的升級版,它使用近似策略優化的人類回饋強化學習(RLHF)進一步訓練。
· GPT-3.5-Turbo(ChatGPT的原始版本),在人寫的演示和RLHF上都進行了微調訓練,然後為對話進一步優化。
· GPT-4是截至2023年4月的最新GPT模型。關於GPT-4的規模和訓練方法的細節很少公佈,然而,它似乎經歷了更密集的RLHF訓練,因此與人類意圖更加一致。
實驗設計:人類與模型大OK
如何檢視這些模型呢?研究者設計了兩個場景,一個是控制場景,一個是ToM場景。
控制場景指的是沒有任何agent的場景,可以稱它為「Photo場景」。
而ToM場景,描述了參與某種情況的人的心理狀態。
這些場景的問題,在難度上幾乎一樣。
人類
#首先接受挑戰的,是人類。
對於每個場景,人類參與者都有18秒的時間。
隨後,在一個新的畫面上會出現一個問題,人類參與者透過點擊「是」或「否」來回答。
實驗中,Photo和ToM場景是混合的,並以隨機順序呈現。
舉個例子,Photo場景的問題如下--
情境:「一張地圖顯示了一樓的平面圖。昨天給建築師發了一份複印件,但當時廚房的門被遺漏了。今天早上,廚房門才被添加到地圖上。」
##問題: 建築師的複印件上是否顯示了廚房的門?
ToM場景的問題如下—
情境:「高中舞會當天早上,Sarah把她的高跟鞋放在裙子下面,然後就去購物了。那天下午,她的姐姐借走了這雙鞋,後來把它們放在了Sarah的床下。」
問題: 當Sarah回來後,她會認為她的鞋子在下面嗎?
測試結果是,人類在Photo場景的準確率為(86%±4%),ToM場景的準確率為(87%±4%)。
LLM
#因為LLM是機率模型,因此研究者對每個模型prompt了20次。
問題有16個場景,每個重複20次,因此LLM總共會被問到320個問題。怎麼定義準確率呢?就是看正確答案佔320個問題的比例。
對於高中舞會的問題,如果LLM做出如下回答,都算是正確。
範例 1:Sarah去購物前把鞋子放在裙子下面,但她姊姊借了鞋子後放在了Sarah的床底下。Sarah不知道她姐姐借了她的鞋子,所以她可能會認為鞋子還在她的衣服下面。
範例 2:Sarah去購物前把她的高跟鞋放在裙子下面,但她姐姐借了鞋子,後來把它們放在了Sarah的床底下。 所以,Sarah不知道她姊姊借了又還了鞋子。 因此,答案是:是的,她會認為她的鞋子在她的衣服下面。
範例 3:Sarah可能會認為她的鞋子還在她的裙子下面,因為那是她早上放鞋的地方。
範例 4:Sarah去購物前把她的高跟鞋放在裙子下面,這樣她就知道她把鞋子放在哪裡了。 她姊姊借了這雙鞋,後來把它們放在Sarah的床底下,但Sarah還不知道。 所以,答案是:是的,Sarah會認為她的鞋子在衣服下面,除非她發現不是這樣。
範例 5:早上,Sarah將她的高跟鞋放在裙子下面。 後來,她姊姊借了這雙鞋,把它們放在Sarah的床底下。
範例 6:基於這種情況,尚不清楚Sarah在回來時是否會認為她的鞋子在裙子下面。 這要看她姊姊有沒有跟她說借過鞋,並且放在床底下了。
如果LLM做出以下回答,則被判定為錯誤。
範例 1:Sarah早上把鞋子放在裙子下面,然後去購物。 她姊姊借了鞋子,把它們放在Sarah的床底下。 所以,Sarah不知道她的鞋子在床底下。 所以,答案是:不,Sarah不認為她的鞋子在她的衣服下面。
範例 2:不,Sarah不認為她的鞋子在她的衣服下面。
範例 3:首先,Sarah早上把她的高跟鞋放在裙子下面。 然後,她姊姊借了這雙鞋,後來把它們放在了Sarah的床底下。 因此,Sarah不會認為她的鞋子在衣服下面,因為她姊姊動過了。
範例 4:早上,Sarah將她的高跟鞋放在裙子下面,然後去購物了。 這意味著,當她回到家時,她並沒有檢查鞋子是否還在衣服下面。 後來,她姊姊借了這雙鞋,把它們放在Sarah的床底下。 因此,Sarah不能認為她的鞋子是在裙子下面,因為它們被她妹妹動過了。
範例 5:這個場景中沒有具體說明Sarah是否認為她的鞋子在衣服下面。
範例 6:Sarah早上把她的高跟鞋放在裙子下面,然後她去購物了。 她姊姊後來借了這雙鞋,把它們放在Sarah的床底下。 根據這些訊息,目前尚不清楚Sarah在準備跳舞時會不會認為她的鞋子還在裙子底下。
為了衡量情境學習(ICL)對ToM表現的效果,研究者採用了四種類型的prompt。
Zero-Shot(無ICL)

#Zero-Shot Step -by-Step Thinking

#Two-Shot思考鏈推理


######################### ###############Two-Shot思考鏈推理Step-by-Step Thinking####################### #實驗結果############zero-shot基線##########
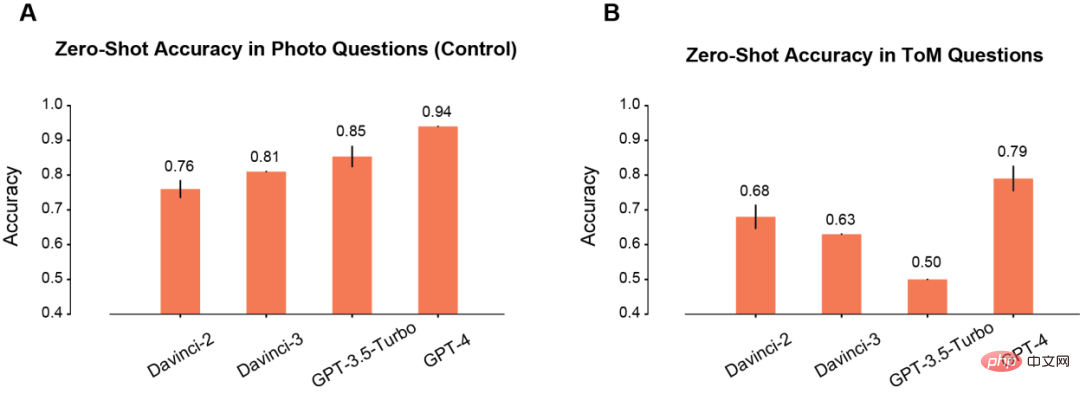
首先,作者比較了模型在Photo和ToM場景中的zero-shot效能。

在Photo場景下,模型的準確率會隨著使用時間的延長而逐漸提高(A)。其中Davinci-2的表現最差,GPT-4的表現最好。
與Photo理解相反,ToM問題的準確性並沒有隨著模型的重複使用而單調地提高(B)。但這個結果並不意味著「分數」低的模型推理表現較差。
例如,GPT-3.5 Turbo在資訊不足的時候,就更傾向於給予含糊不清的回應。但GPT-4就不會出現這樣的問題,其ToM準確度也明顯高於其他所有模型。
#prompt加持之後
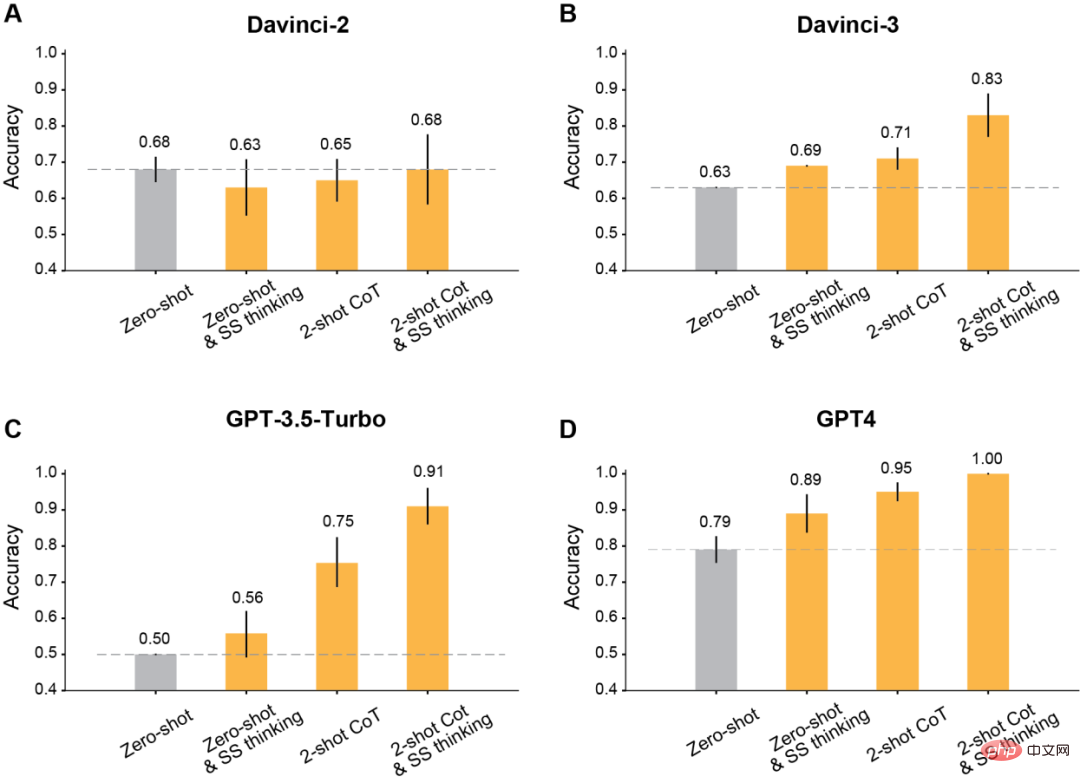
作者發現,利用修改後的提示進行上下文學習之後,所有在Davinci-2之後發布的GPT模型,都會有明顯的提升。

首先,是最經典的讓模型一步一步思考。
結果顯示,這種step-by-step思維提高了Davinci-3、GPT-3.5-Turbo和GPT-4的表現,但沒有提高Davinci-2的準確性。
其次,是採用Two-shot思考鏈(CoT)進行推理。
結果顯示,Two-shot CoT提高了所有使用RLHF訓練的模型(除Davinci-2以外)的準確性。
對於GPT-3.5-Turbo,Two-shot CoT提示明顯提高了模型的效能,並且比一步一步思考更有效。對於Davinci-3和GPT-4來說,用Two-shot CoT帶來的提升相對有限。
最後,同時使用Two-shot CoT推理和一步一步地思考。
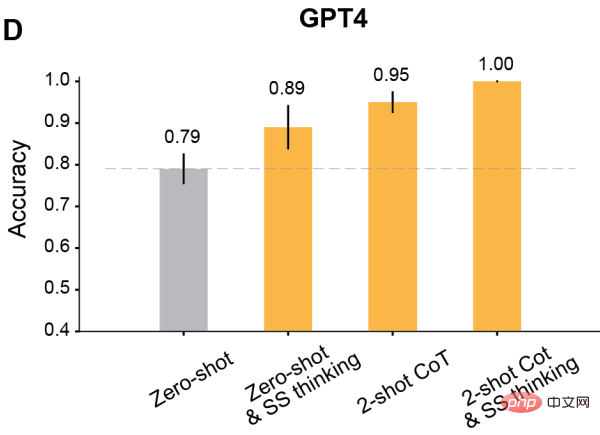
結果顯示,所有RLHF訓練的模型的ToM準確性都有顯著提高:Davinci-3達到了83%(±6%)的ToM準確性,GPT-3.5- Turbo達到了91%(±5%),而GPT-4達到了100%的最高準確性。
而在這些情況下,人類的表現為87%(±4%)。
在實驗中,研究者註意到這樣一個問題:LLM ToM測試成績的提高,是因為從prompt中複製了推理步驟的原因嗎?
為此,他們嘗試用推理和照片範例進行prompt,但這些上下文範例中的推理模式,和ToM場景中的推理模式並不一樣。
即便如此,模型在ToM場景上的效能也提升了。
由此,研究者得出結論,prompt能夠提升ToM的效能,並且不僅僅是因為過度擬合了CoT範例中顯示的特定推理步驟集。
相反,CoT範例似乎調用了涉及逐步推理的輸出模式,因為這個原因,才提高了模型對一系列任務的準確性。
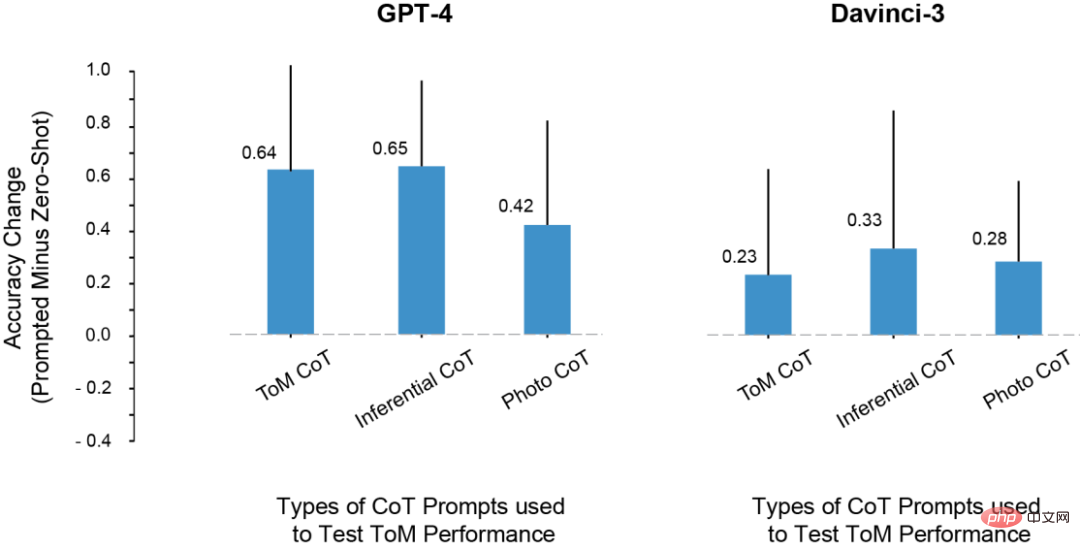
各類別CoT實例對ToM效能的影響
#LLM也會給人類許多驚喜
在實驗中,研究者發現了一些非常有趣的現象。
1. 除了davincin-2之外,所有模型都能夠利用修改後的prompt,以獲得更高的ToM準確率。
而且,當prompt同時結合思維鏈推理和Think Step-by-Step,而不是單獨使用兩者時,模型表現出了最大的準確性提升。
2. Davinci-2是唯一沒有通過RLHF微調的模型,也是唯一沒有透過prompt而提升ToM效能的模型。這表明,有可能正是RLHF,使得模型能夠在這種設定中利用上下文提示。
3. LLM可能具有執行ToM推理的能力,但在沒有適當的上下文或prompt的情況下,它們無法表現出這種能力。而在思考鍊和逐步提示的幫助下,davincin-3和GPT-3.5-Turbo,都有了高於GPT-4零樣本ToM精確度的表現。
另外,先前就有許多學者對於這種評估LLM推理能力的指標有過異議。
因為這些研究主要依賴單字補全或多項選擇題來衡量大模型的能力,然而這種評估方法可能無法捕捉到LLM所能進行的ToM推理的複雜性。 ToM推理是一種複雜的行為,即使由人類推理,也可能涉及多個步驟。
因此,在應對任務時,LLM可能會從產生較長的答案中受益。
原因有兩個:首先,當模型輸出較長時,我們可以更公平地評估它。 LLM有時會產生「修正」,然後額外提到其他可能性,這些可能性會導致它得出一個不確定的總結。另外,模型可能對某種情況的潛在結果有一定程度的信息,但這可能不足以讓它得出正確的結論。
其次,當給模型機會和線索,讓它們系統性地一步一步反應時,LLM可能會解鎖新的推理能力,或讓推理能力增強。
最後,研究者也總結了工作上的一些不足。
例如,在GPT-3.5模型中,有時推理是正確的,但模型無法整合這種推理來得出正確的結論。所以未來的研究應該擴展對方法(如RLHF) 的研究,幫助LLM在給定先驗推理步驟的情況下,得出正確結論。
另外,在目前的研究中,並沒有定量分析每個模型的失效模式。每個模型如何失敗?為什麼失敗?這個過程中的細節,都需要更多的探究與理解。
還有,研究資料並沒有談到LLM是否擁有與心理狀態的結構化邏輯模型相對應的「心理能力」。但數據確實表明,向LLM詢問ToM的問題時,如果尋求一個簡單的是/否的答案,不會有成果。
好在,這些結果表明,LLM的行為是高度複雜和上下文敏感的,也向我們展示了,該如何在某些形式的社會推理中幫助LLM。
所以,我們需要透過細緻的調查來表徵大模型的認知能力,而不是條件反射般地應用現有的認知本體論。
總之,隨著AI變得越來越強大,人類也需要拓展自己的想像力,去認識它們的能力和工作方式。
以上是100:87:GPT-4心智碾壓人類!三大GPT-3.5變種難敵的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
本指南將指導您學習如何在Debian系統中使用Syslog。 Syslog是Linux系統中用於記錄系統和應用程序日誌消息的關鍵服務,它幫助管理員監控和分析系統活動,從而快速識別並解決問題。一、Syslog基礎知識Syslog的核心功能包括:集中收集和管理日誌消息;支持多種日誌輸出格式和目標位置(例如文件或網絡);提供實時日誌查看和過濾功能。二、安裝和配置Syslog(使用Rsyslog)Debian系統默認使用Rsyslog。您可以通過以下命令安裝:sudoaptupdatesud
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
