

SpringBoot怎麼使用Caffeine實現緩存

為什麼要在應用程式中加入快取
在深入探討如何在應用程式中新增快取之前,首先想到的問題是為什麼我們需要在應用程式中使用快取。
假設有一個包含客戶資料的應用程序,使用者發出兩個請求來獲取客戶的資料(id=100)。
這就是沒有快取時的情況。
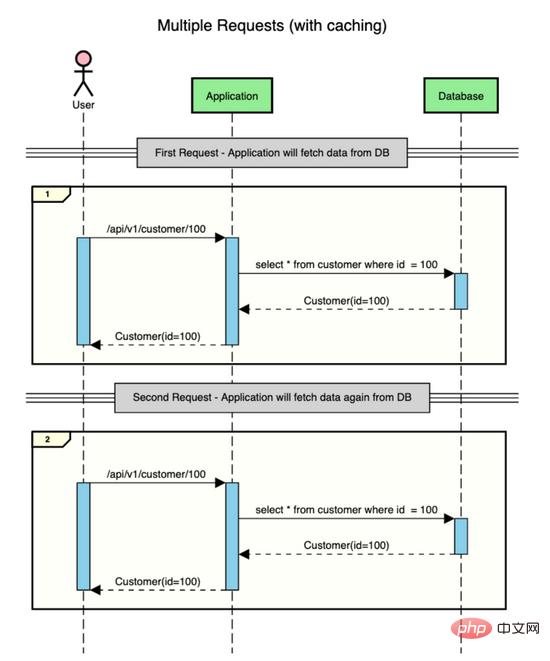
如您所見,對於每個請求,應用程式都會轉到資料庫以取得資料。從資料庫取得資料是一項成本高昂的操作,因為它涉及IO。
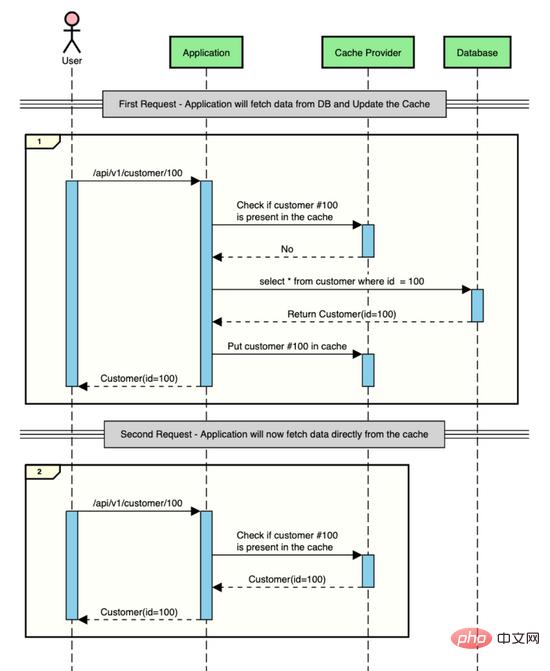
但是,如果中間有一個快取存儲,可以在其中臨時存儲短時間的數據,則可以將這些往返保存到資料庫並在IO時間保存。
這就是使用快取時上述互動的樣子。
在Spring Boot應用程式中實作快取
SpringBoot提供了什麼快取支援?
SpringBoot只提供了一個快取抽象,您可以使用它將快取透明、輕鬆地添加到Spring應用程式中。
它不提供實際的快取儲存。
但是,它可以與不同類型的快取提供者一起工作,如Ehcache、Hazelcast、Redis、Caffee等。
SpringBoot的快取抽象可以加入方法中(使用註解)
#基本上,在執行方法之前,Spring框架將檢查方法資料是否已經快取
如果是,則它將從快取中取得資料。
否則它將執行該方法並快取資料
#它也提供了從快取更新或刪除資料的抽象。
在我們目前的部落格中,我們將了解如何使用Caffeine添加緩存,Caffeine是一種基於Java8的高效能、接近最優的快取庫。
您可以在 application.yaml 檔案中指定使用哪個快取提供者來設定 spring.cache.type 屬性。
但是,如果沒有提供屬性,Spring將根據新增的庫自動偵測快取提供者。
新增生成依賴項
現在假設您已經啟動並運行了基本的Spring boot應用程序,讓我們新增快取相依性。
開啟 build.gradle 文件,並新增以下相依性以啟用Spring Boot的快取
compile('org.springframework.boot:spring-boot-starter-cache')
接下來我們將新增對Caffeine的依賴
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
快取配置
現在我們需要在Spring Boot應用程式中啟用快取。
為此,我們需要建立一個設定類別並提供註解 @EnableCaching 。
@Configuration
@EnableCaching
public class CacheConfig {
}現在這個類別是一個空類,但是我們可以為它添加更多配置(如果需要)。
現在我們已經啟用了緩存,讓我們提供快取名稱和快取屬性的配置,如快取大小、快取過期時間等
最簡單的方法是在 application.yaml 中新增設定
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60s上述設定執行以下動作
#將可用快取名稱限制為客戶、使用者和角色。將最大快取大小設定為500。
當快取中的物件數達到此限制時,將根據快取逐出策略從快取中刪除物件。將快取過期時間設定為1分鐘。
這表示項目將在新增至快取1分鐘後從快取中刪除。
還有另一種設定快取的方法,而不是在 application.yaml 檔案中設定快取。
您可以在快取設定類別中新增並提供一個 CacheManager Bean,該Bean可以完成與上面在 application.yaml 中的設定完全相同的工作
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}在我們的程式碼範例中,我們將使用Java配置。
我們可以在Java中做更多的事情,例如設定 RemovalListener ,當一個項目從快取中刪除時執行 RemovalListener ,或啟用快取統計記錄,等等。
快取方法結果
在我們使用的範例Spring boot應用程式中,我們已經有了以下API GET /API/v1/customer/{id} 來檢索客戶記錄。
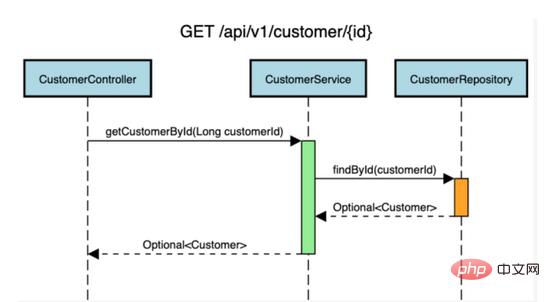
我們將在CustomerService類別的 getCustomerByd(longCustomerId) 方法新增快取。
要做到這一點,我們只需要做兩件事
1. 將註解 @CacheConfig(cacheNames=「customers」) 加入 CustomerService 類別
提供此選項將確保 CustomerService 的所有可快取方法都會使用快取名稱「customers」
2. 向方法 Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
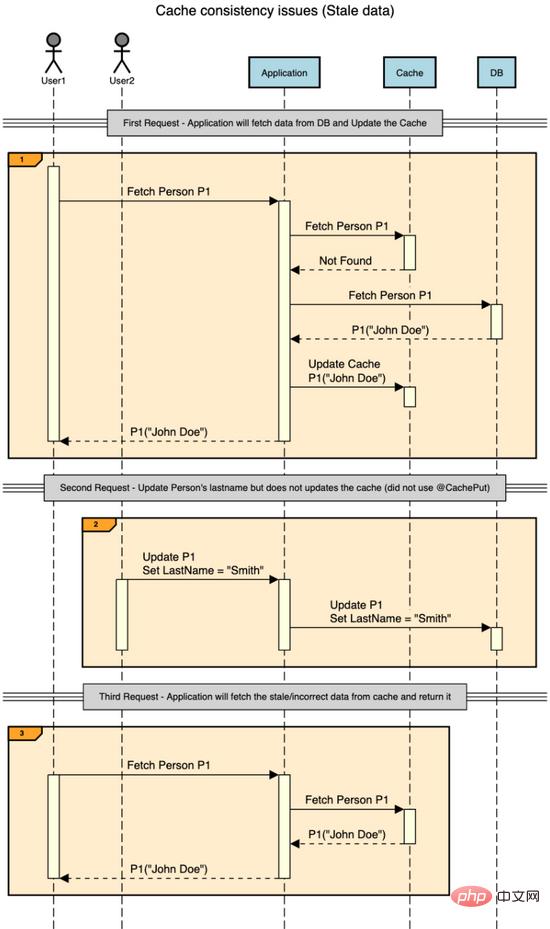
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
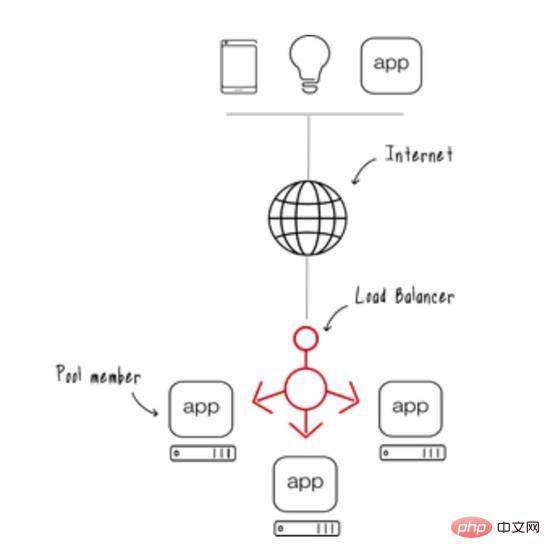
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
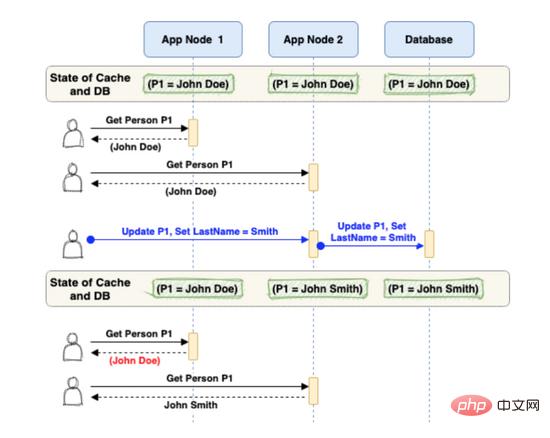
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
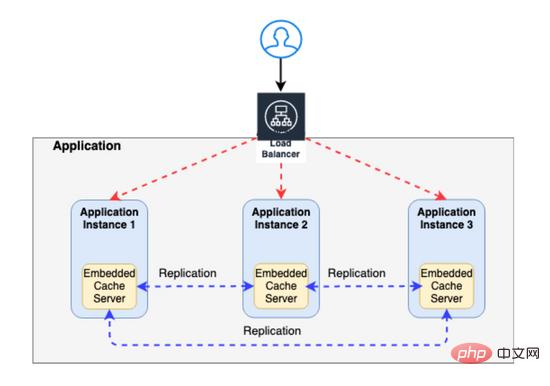
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
以上是SpringBoot怎麼使用Caffeine實現緩存的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Springboot怎麼整合Jasypt實現設定檔加密
Jun 01, 2023 am 08:55 AM
Springboot怎麼整合Jasypt實現設定檔加密
Jun 01, 2023 am 08:55 AM
Jasypt介紹Jasypt是一個java庫,它允許開發員以最少的努力為他/她的專案添加基本的加密功能,並且不需要對加密工作原理有深入的了解用於單向和雙向加密的高安全性、基於標準的加密技術。加密密碼,文本,數字,二進位檔案...適合整合到基於Spring的應用程式中,開放API,用於任何JCE提供者...添加如下依賴:com.github.ulisesbocchiojasypt-spring-boot-starter2. 1.1Jasypt好處保護我們的系統安全,即使程式碼洩露,也可以保證資料來源的
 SpringBoot怎麼整合Redisson實現延遲隊列
May 30, 2023 pm 02:40 PM
SpringBoot怎麼整合Redisson實現延遲隊列
May 30, 2023 pm 02:40 PM
使用場景1、下單成功,30分鐘未支付。支付超時,自動取消訂單2、訂單簽收,簽收後7天未進行評估。訂單超時未評價,系統預設好評3、下單成功,商家5分鐘未接單,訂單取消4、配送超時,推播簡訊提醒…對於延時比較長的場景、即時性不高的場景,我們可以採用任務調度的方式定時輪詢處理。如:xxl-job今天我們採
 怎麼在SpringBoot中使用Redis實現分散式鎖
Jun 03, 2023 am 08:16 AM
怎麼在SpringBoot中使用Redis實現分散式鎖
Jun 03, 2023 am 08:16 AM
一、Redis實現分散式鎖原理為什麼需要分散式鎖在聊分散式鎖之前,有必要先解釋一下,為什麼需要分散式鎖。與分散式鎖相對就的是單機鎖,我們在寫多執行緒程式時,避免同時操作一個共享變數產生資料問題,通常會使用一把鎖來互斥以保證共享變數的正確性,其使用範圍是在同一個進程中。如果換做是多個進程,需要同時操作一個共享資源,如何互斥?現在的業務應用通常是微服務架構,這也意味著一個應用會部署多個進程,多個進程如果需要修改MySQL中的同一行記錄,為了避免操作亂序導致髒數據,此時就需要引入分佈式鎖了。想要實現分
 springboot讀取檔案打成jar包後存取不到怎麼解決
Jun 03, 2023 pm 04:38 PM
springboot讀取檔案打成jar包後存取不到怎麼解決
Jun 03, 2023 pm 04:38 PM
springboot讀取文件,打成jar包後訪問不到最新開發出現一種情況,springboot打成jar包後讀取不到文件,原因是打包之後,文件的虛擬路徑是無效的,只能通過流去讀取。文件在resources下publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Springboot+Mybatis-plus不使用SQL語句進行多表新增怎麼實現
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus不使用SQL語句進行多表新增怎麼實現
Jun 02, 2023 am 11:07 AM
在Springboot+Mybatis-plus不使用SQL語句進行多表添加操作我所遇到的問題準備工作在測試環境下模擬思維分解一下:創建出一個帶有參數的BrandDTO對像模擬對後台傳遞參數我所遇到的問題我們都知道,在我們使用Mybatis-plus中進行多表操作是極其困難的,如果你不使用Mybatis-plus-join這一類的工具,你只能去配置對應的Mapper.xml文件,配置又臭又長的ResultMap,然後再寫對應的sql語句,這種方法雖然看上去很麻煩,但具有很高的靈活性,可以讓我們
 SpringBoot與SpringMVC的比較及差別分析
Dec 29, 2023 am 11:02 AM
SpringBoot與SpringMVC的比較及差別分析
Dec 29, 2023 am 11:02 AM
SpringBoot和SpringMVC都是Java開發中常用的框架,但它們之間有一些明顯的差異。本文將探究這兩個框架的特點和用途,並對它們的差異進行比較。首先,我們來了解一下SpringBoot。 SpringBoot是由Pivotal團隊開發的,它旨在簡化基於Spring框架的應用程式的建立和部署。它提供了一種快速、輕量級的方式來建立獨立的、可執行
 SpringBoot怎麼自訂Redis實作快取序列化
Jun 03, 2023 am 11:32 AM
SpringBoot怎麼自訂Redis實作快取序列化
Jun 03, 2023 am 11:32 AM
1.自訂RedisTemplate1.1、RedisAPI預設序列化機制基於API的Redis快取實作是使用RedisTemplate範本進行資料快取操作的,這裡開啟RedisTemplate類,查看該類別的源碼資訊publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations,BeanClassLoaderAware{//聲明了value的各種序列化方式,初始值為空@NullableprivateRedisSe
 springboot怎麼取得application.yml裡值
Jun 03, 2023 pm 06:43 PM
springboot怎麼取得application.yml裡值
Jun 03, 2023 pm 06:43 PM
在專案中,很多時候需要用到一些配置信息,這些信息在測試環境和生產環境下可能會有不同的配置,後面根據實際業務情況有可能還需要再做修改。我們不能將這些設定在程式碼中寫死,最好是寫到設定檔中,例如可以把這些資訊寫到application.yml檔案中。那麼,怎麼在程式碼裡取得或使用這個位址呢?有2個方法。方法一:我們可以透過@Value註解的${key}即可取得設定檔(application.yml)中和key對應的value值,這個方法適用於微服務比較少的情形方法二:在實際專案中,遇到業務繁瑣,邏
