

熔岩羊駝LLaVA來了:像GPT-4一樣可以看圖聊天,無需邀請碼,在線可玩


GPT-4 的識圖能力什麼時候能上線呢?這個問題目前依然沒有答案。
但研究社群等不及了,紛紛自己上手 DIY,其中最熱門的是名為 MiniGPT-4 的計畫。 MiniGPT-4 展示了許多類似於 GPT-4 的能力,例如產生詳細的圖像描述並從手寫草稿創建網站。此外,作者還觀察到 MiniGPT-4 的其他新興能力,包括根據給定的圖像創作故事和詩歌,提供解決圖像中顯示的問題的解決方案,根據食品照片教導使用者如何烹飪等。該專案上線 3 天就拿到了近一萬的 Star 量。

今天要介紹的計畫-LLaVA(Large Language and Vision Assistant)與之類似,是個由威斯康辛大學麥迪遜分校、微軟研究院和哥倫比亞大學研究者共同發表的多模態大模型。

- 論文連結:https://arxiv.org/pdf/2304.08485.pdf
- #專案連結:https://llava-vl.github.io/
#該模型顯示出了一些接近多模態GPT-4 的圖文理解能力:相對於GPT-4 獲得了85.1% 的相對得分。當在科學問答(Science QA)上進行微調時,LLaVA 和 GPT-4 的協同作用實現了 92.53% 準確率的新 SoTA。

以下是機器之心的試用結果(更多結果請見文末):

#論文概覽
人類透過視覺和語言等多種管道與世界交互,因為不同的管道在代表和傳達某些概念時都有各自獨特的優勢,多通道的方式有利於更好地理解世界。人工智慧的核心願望之一是發展一個通用的助手,能夠有效地遵循多模態指令,例如視覺或語言的指令,滿足人類的意圖,在真實環境中完成各種任務。
為此,社群興起了開發基於語言增強的視覺模型的風潮。這類模型在開放世界視覺理解方面具有強大的能力,如分類、偵測、分割和圖文,以及視覺生成和視覺編輯能力。每個任務都由一個大型視覺模型獨立解決,在模型設計中隱含地考慮了任務的需求。此外,語言僅用於描述圖像內容。雖然這使得語言在將視覺訊號映射到語言語義(人類溝通的常見管道)方面發揮了重要作用,但它導致模型通常具有固定的介面,在互動性和對使用者指令的適應性上存在限制。
另一方面,大型語言模型(LLM)已經表明,語言可以發揮更廣泛的作用:作為通用智慧助理的通用互動介面。在通用介面中,各種任務指令可以用語言明確表示,並引導端對端訓練的神經網路助理切換模式來完成任務。例如,ChatGPT 和 GPT-4 最近的成功證明了 LLM 在遵循人類指令完成任務方面的能量,並掀起了開發開源 LLM 的熱潮。其中,LLaMA 是一種與 GPT-3 效能相近的開源 LLM。 Alpaca、Vicuna、GPT-4-LLM 利用各種機器產生的高品質指令追蹤樣本來提高 LLM 的對齊能力,與專有 LLM 相比,展現了令人印象深刻的性能。但遺憾的是,這些模型的輸入僅為文字。
在本文中,研究者提出了視覺 instruction-tuning 方法,首次嘗試將 instruction-tuning 擴展到多模態空間,為建構通用視覺助理鋪平了道路。
具體來說,本文做出了以下貢獻:
- #多模態指令資料。當下關鍵的挑戰之一是缺乏視覺與語言組成的指令資料。本文提出了一個資料重組方式,使用 ChatGPT/GPT-4 將圖像 - 文字對轉換為適當的指令格式;
- 大型多模態模型。研究者透過連接 CLIP 的開源視覺編碼器和語言解碼器 LLaMA,開發了一個大型多模態模型(LMM)— LLaVA,並在生成的視覺 - 語言指令資料上進行端到端微調。實證研究驗證了將產生的資料用於 LMM 進行 instruction-tuning 的有效性,並為建立遵循視覺 agent 的通用指令提供了較為實用的技巧。使用 GPT-4,本文在 Science QA 這個多模態推理資料集上實現了最先進的效能。
- 開源。研究者向公眾發布了以下資產:產生的多模式指令資料、用於資料生成和模型訓練的程式碼庫、模型檢查點和視覺化聊天演示。
LLaVA 架構
本文的主要目標是有效利用預先訓練的 LLM 和視覺模型的功能。網路架構如圖 1 所示。本文選擇 LLaMA 模型作為 LLM fφ(・),因為它的有效性已經在幾個開源的純語言 instruction-tuning 工作中得到了證明。

對於輸入影像X_v,本文使用預先訓練的CLIP 視覺編碼器ViT-L/14 進行處理,得到視覺特徵Z_v=g ( X_v)。實驗中使用的是最後一個 Transformer 層之前和之後的網格特徵。本文使用一個簡單的線性圖層來將影像特徵連接到單字嵌入空間。具體而言,應用可訓練投影矩陣W 將Z_v 轉換為語言嵌入標記H_q,H_q 具有與語言模型中的單字嵌入空間相同的維度:
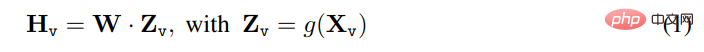
之後,得到一系列視覺標記H_v。這種簡單投影方案具有輕量、成本低等特點,能夠快速迭代以資料為中心的實驗。也可以考慮連接影像和語言特徵的更複雜(但昂貴)的方案,例如Flamingo 中的門控交叉注意力機制和BLIP-2 中的Q-former,或提供物件層級特徵的其他視覺編碼器,如SAM。
實驗結果
多模態聊天機器人
#研究者開發了一個聊天機器人範例產品,以展示LLaVA 的影像理解和對話能力。為了進一步研究 LLaVA 如何處理視覺輸入,展現其處理指令的能力,研究者首先使用 GPT-4 原始論文中的範例,如表 4 和表 5 所示。使用的 prompt 需要貼合影像內容。為了進行比較,本文引用了其論文中多模態模型 GPT-4 的 prompt 和結果。


令人驚訝的是,儘管LLaVA 是用一個小的多模態指令資料集(約80K 的不重複影像)訓練的,但它在上述這兩個範例上展示了與多模態模型GPT-4 非常相似的推理結果。請注意,這兩張圖像都不在 LLaVA 的資料集範圍內,LLaVA 能夠理解場景並按照問題說明進行回答。相較之下,BLIP-2 和 OpenFlamingo 專注於描述影像,而不是按照使用者指示以適當的方式回答。更多示例如圖 3、圖 4 和圖 5 所示。



#量化評估結果如表 3。

ScienceQA
#ScienceQA 包含21k 個多模態多選問題,涉及3 個主題、26 個主題、127 個類別和379 種技能,具有豐富的領域多樣性。基準資料集分為訓練、驗證和測試部分,分別有 12726、4241 和 4241 個樣本。本文比較了兩種具代表性的方法,包括GPT-3.5 模型(text-davinci-002)和沒有思考鏈(CoT)版本的GPT-3.5 模型,LLaMA-Adapter,以及多模態思考鏈(MM- CoT)[57],這是該資料集上目前的SoTA 方法,結果如表6 所示。

試用回饋
在論文給出的視覺化使用頁面上,機器之心也嘗試輸入了一些圖片和指令。首先是問答裡常見的數人任務。測試表明,數人的時候較小的目標會被忽略,重疊的人也有識別誤差,性別也有識別誤差。


接著,我們嘗試了一些生成任務,例如為圖片起名字,或根據圖片講一個故事。模型輸出的結果還是偏向圖片內容理解,生成方面的能力仍有待加強。


在這張照片中,即便人體有重疊也依然能準確地辨識出人數。從圖片描述和理解能力的角度來看,本文的工作還是有亮點,存在著二創的空間。
以上是熔岩羊駝LLaVA來了:像GPT-4一樣可以看圖聊天,無需邀請碼,在線可玩的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
DDREASE是一種用於從檔案或區塊裝置(如硬碟、SSD、RAM磁碟、CD、DVD和USB儲存裝置)復原資料的工具。它將資料從一個區塊設備複製到另一個區塊設備,留下損壞的資料區塊,只移動好的資料區塊。 ddreasue是一種強大的恢復工具,完全自動化,因為它在恢復操作期間不需要任何干擾。此外,由於有了ddasue地圖文件,它可以隨時停止和恢復。 DDREASE的其他主要功能如下:它不會覆寫恢復的數據,但會在迭代恢復的情況下填補空白。但是,如果指示工具明確執行此操作,則可以將其截斷。將資料從多個檔案或區塊還原到單
 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基準測試中表現已經超過Pytorch和TensorFlow,7項指標排名第一。而且測試並不是JAX性能表現最好的TPU上完成的。雖然現在在開發者中,Pytorch依然比Tensorflow更受歡迎。但未來,也許有更多的大型模型會基於JAX平台進行訓練和運行。模型最近,Keras團隊為三個後端(TensorFlow、JAX、PyTorch)與原生PyTorch實作以及搭配TensorFlow的Keras2進行了基準測試。首先,他們為生成式和非生成式人工智慧任務選擇了一組主流
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模態文件理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模態文件理解能力新SOTA!阿里mPLUG團隊發布最新開源工作mPLUG-DocOwl1.5,針對高解析度圖片文字辨識、通用文件結構理解、指令遵循、外部知識引入四大挑戰,提出了一系列解決方案。話不多說,先來看效果。複雜結構的圖表一鍵識別轉換為Markdown格式:不同樣式的圖表都可以:更細節的文字識別和定位也能輕鬆搞定:還能對文檔理解給出詳細解釋:要知道,“文檔理解”目前是大語言模型實現落地的一個重要場景,市面上有許多輔助文檔閱讀的產品,有的主要透過OCR系統進行文字識別,配合LLM進行文字理
