

Python與Excel的完美結合:常用操作彙總(案例詳析)


正文
以前,商業分析對應的英文單字是Business Analysis,大家用的分析工具是Excel,後來資料量大了,Excel應付不過來了(Excel最大支援行數為1048576行),人們開始轉向python和R這樣的分析工具了,這時候商業分析對應的單字是Business Analytics。
其實python和Excel的使用準則一樣,都是[We don't repeat ourselves],都是盡可能用更方便的操作替代機械操作和純體力勞動。
用python做數據分析,離不開著名的pandas包,經過了很多版本的迭代優化,pandas現在的生態圈已經相當完整了,官網還給出了它和其他分析工具的對比:

本文用的主要也是pandas,繪圖用的函式庫是plotly,實作的Excel的常用功能有:
- Python和Excel的交互
- vlookup函數
- 資料透視表
- 繪圖
以後如果發掘了更多Excel的功能,會回來繼續更新和補充。在開始之前,先按照慣例載入pandas套件:
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法Python和Excel的互動
pandas裡最常用的和Excel I/O有關的四個函數是read_csv/ read_excel/ to_csv/ to_excel,它們都有特定的參數設置,可以自訂想要的讀取和匯出效果。
比如說想要讀取這樣一張表的左上部分:
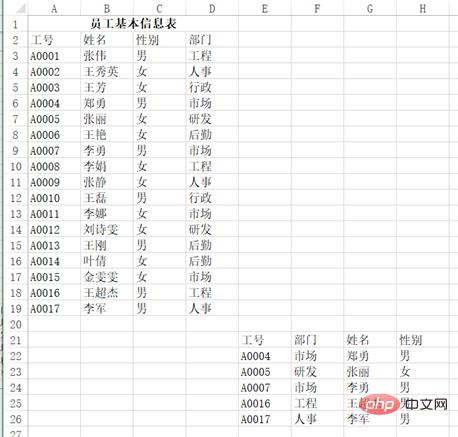
#可以用pd.read_excel("test.xlsx", header=1 , nrows=17, usecols=3),回傳結果:
df Out[]: 工号 姓名 性别部门 0 A0001 张伟男工程 1 A0002王秀英女人事 2 A0003 王芳女行政 3 A0004 郑勇男市场 4 A0005 张丽女研发 5 A0006 王艳女后勤 6 A0007 李勇男市场 7 A0008 李娟女工程 8 A0009 张静女人事 9 A0010 王磊男行政 10A0011 李娜女市场 11A0012刘诗雯女研发 12A0013 王刚男后勤 13A0014 叶倩女后勤 14A0015金雯雯女市场 15A0016王超杰男工程 16A0017 李军男人事
輸出函數也同理,使用多少列,要不要index,標題怎麼放,都可以控制。
vlookup函數
vlookup號稱是Excel裡的神器之一,用途很廣泛,下面的例子來自豆瓣,VLOOKUP函數最常用的10種用法,你會幾種?
案例一
問題:A3:B7單元格區域為字母等級查詢表,表示60分以下為E級、60~69分為D級、70~79分為C級、 80~89分為B級、90分以上為A級。 D:G列為初二年級1班語測驗成績表,如何依語文成績回到字母等級?
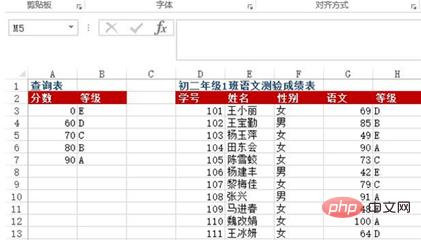
方法:在H3:H13單元格區域中輸入=VLOOKUP(G3, $A$3:$B$7, 2)
python實作:
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
Out[]:
学号 姓名 性别 语文 等级
0 101王小丽女 69D
1 102王宝勤男 85B
2 103杨玉萍女 49E
3 104田东会女 90A
4 105陈雪蛟女 73C
5 106杨建丰男 42E
6 107黎梅佳女 79C
7 108 张兴 男 91A
8 109马进春女 48E
9 110魏改娟女100A
10111王冰研女 64D案例二#
##問題:在Sheet1裡面如何找出折舊明細表中對應編號下的月折舊額? (跨表查詢)。

df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
Out[]:
编号 资产名称月折旧额
0YT001电动门 1399
1YT005桑塔纳轿车1147
2YT008打印机51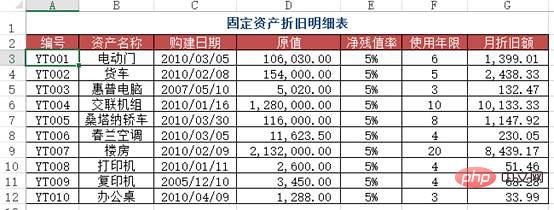
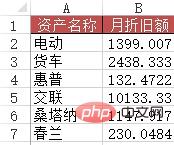
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
Out[]:
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普132
3 交联10133
4桑塔纳 1147
5 春兰230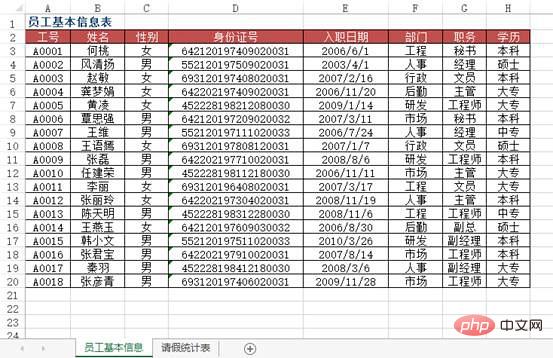
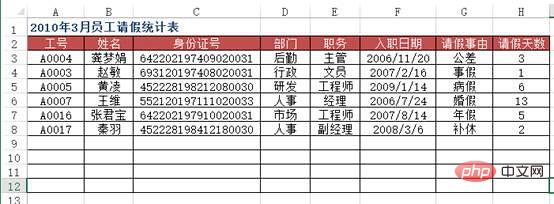
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
Out[]:
工号 姓名部门 职务 入职日期
0A0004龚梦娟后勤 主管 2006-11-20
1A0003 赵敏行政 文员 2007-02-16
2A0005 黄凌研发工程师 2009-01-14
3A0007 王维人事 经理 2006-07-24
4A0016张君宝市场工程师 2007-08-14
5A0017 秦羽人事副经理 2008-03-06案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
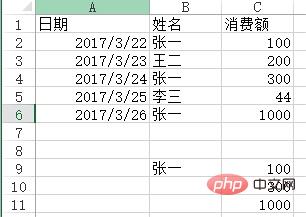
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些。
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
Out[]:
姓名 消费额
0张一 100
2张一 300
4张一1000数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途:(https://www.zhihu.com/question/22484899/answer/39933218 )
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润。
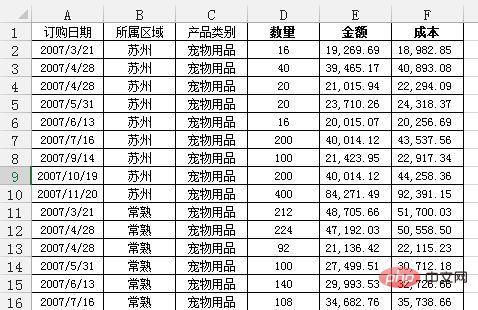
通过Excel的数据透视表的操作最终实现了下面这样的效果:
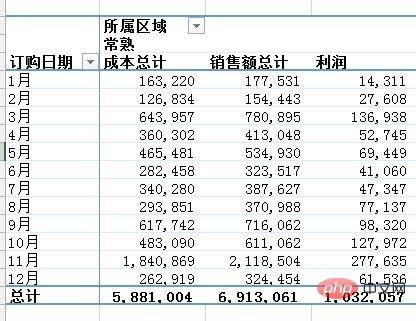
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
Out[]:
销售额 成本利润
订购月份 所属区域
1南京134313.61 94967.8439345.77
常熟177531.47163220.0714311.40
无锡316418.09231822.2884595.81
昆山159183.35145403.3213780.03
苏州287253.99238812.0348441.96
2南京187129.13138530.4248598.71
常熟154442.74126834.3727608.37
无锡464012.20376134.9887877.22
昆山102324.46 86244.5216079.94
苏州105940.34 91419.5414520.80
...... ...
11 南京286329.88221687.1164642.77
常熟 2118503.54 1840868.53 277635.01
无锡633915.41536866.7797048.64
昆山351023.24342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京894522.06808959.3285562.74
常熟324454.49262918.8161535.68
无锡 1040127.19856816.72 183310.48
昆山 1096212.75951652.87 144559.87
苏州347939.30302154.2545785.05
[60 rows x 3 columns]也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum') df3['利润'] = df3['销售额'] - df3['成本'] df3 Out[]: 成本销售额利润 订购月份 所属区域 1南京 94967.84134313.6139345.77 常熟163220.07177531.4714311.40 无锡231822.28316418.0984595.81 昆山145403.32159183.3513780.03 苏州238812.03287253.9948441.96 2南京138530.42187129.1348598.71 常熟126834.37154442.7427608.37 无锡376134.98464012.2087877.22 昆山 86244.52102324.4616079.94 苏州 91419.54105940.3414520.80 ...... ... 11 南京221687.11286329.8864642.77 常熟 1840868.53 2118503.54 277635.01 无锡536866.77633915.4197048.64 昆山342420.18351023.24 8603.06 苏州 1144809.83 1269351.39 124541.56 12 南京808959.32894522.0685562.74 常熟262918.81324454.4961535.68 无锡856816.72 1040127.19 183310.48 昆山951652.87 1096212.75 144559.87 苏州302154.25347939.3045785.05 [60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。)
但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。
不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。
我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off import plotly.graph_objs as go off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是:
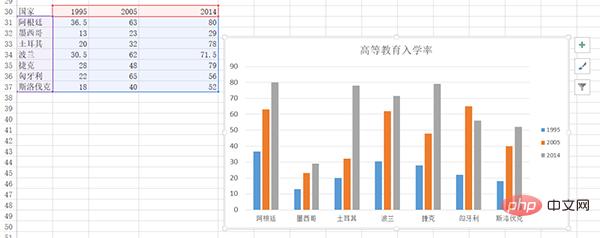
下面用plotly来画一下:
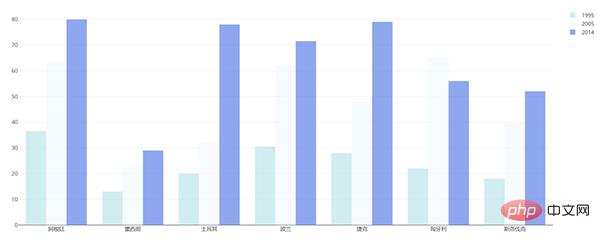
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)雷达图
用Excel画的:
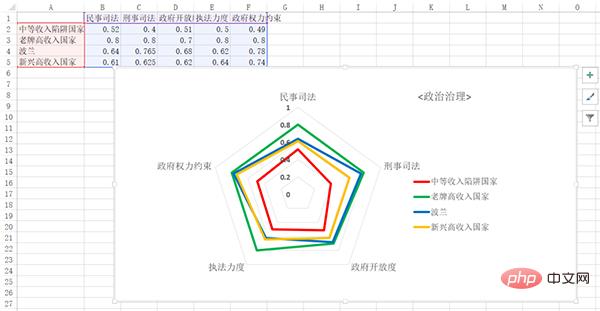
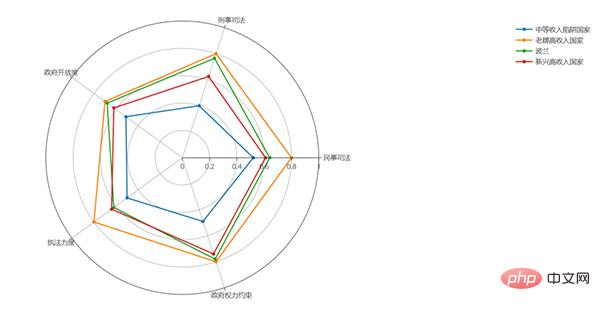
用python画的:
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)画起来比Excel要麻烦得多。
总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
以上是Python與Excel的完美結合:常用操作彙總(案例詳析)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
CentOS上如何進行PyTorch模型訓練
Apr 14, 2025 pm 03:03 PM
在CentOS系統上高效訓練PyTorch模型,需要分步驟進行,本文將提供詳細指南。一、環境準備:Python及依賴項安裝:CentOS系統通常預裝Python,但版本可能較舊。建議使用yum或dnf安裝Python3併升級pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。 CUDA與cuDNN(GPU加速):如果使用NVIDIAGPU,需安裝CUDATool
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
CentOS下PyTorch版本怎麼選
Apr 14, 2025 pm 02:51 PM
在CentOS下選擇PyTorch版本時,需要考慮以下幾個關鍵因素:1.CUDA版本兼容性GPU支持:如果你有NVIDIAGPU並且希望利用GPU加速,需要選擇支持相應CUDA版本的PyTorch。可以通過運行nvidia-smi命令查看你的顯卡支持的CUDA版本。 CPU版本:如果沒有GPU或不想使用GPU,可以選擇CPU版本的PyTorch。 2.Python版本PyTorch
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
