

Python如何使用LRU快取策略進行快取

一、Python 快取
① 快取作用
快取是一種最佳化技術,可以在應用程式中使用它來將最近或經常使用的數據保存在記憶體中,透過這種方式來存取資料的速度比直接讀取磁碟檔案的高很多。
假設我們建立了一個新聞聚合網站,類似於 Feedly,其獲取不同來源的新聞然後聚合展示。當使用者瀏覽新聞的時候,後台程式會將文章下載然後顯示到使用者畫面。如果不使用快取技術的話,當使用者多次切換瀏覽相同文章的時候,必須多次下載,效率低且很不友善。
更好的做法就是在獲取每篇文章之後,在本地進行內容的存儲,例如存儲在資料庫中;然後,當用戶下次打開同一篇文章的時候,後台程式可以從本地儲存打開內容,而不是再次下載來源文件,即這種技術稱為快取。
② 使用Python 字典實作快取
以新聞聚合網站為例,不必每次都去下載文章內容,而是先檢查快取資料中是否存在對應的內容,只有當沒有時,才會讓伺服器下載文章。
如下的範例程序,就是使用Python 字典實現快取的,將文章的URL 作為鍵,並將其內容作為值;執行之後,可以看到當第二次執行get_article 函數的時候,直接就回傳結果並沒有讓伺服器下載:
import requests
cache = dict()
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def get_article(url):
print("Getting article...")
if url not in cache:
cache[url] = get_article_from_server(url)
return cache[url]
get_article("https://www.escapelife.site/love-python.html")
get_article("https://www.escapelife.site/love-python.html")將此程式碼儲存到一個caching.py 檔案中,安裝requests 函式庫,然後執行腳本:
# 安装依赖 $ pip install requests # 执行脚本 $ python python_caching.py Getting article... Fetching article from server... Getting article...
儘管呼叫get_article() 兩次(第17 行和第18 行)字串“Fetching article from server…”,但仍然只輸出一次。發生這種情況的原因是,在第一次存取文章之後,將其 URL 和內容放入快取字典中,第二次時程式碼不需要再次從伺服器取得項目。
③ 使用字典來做快取的弊端
上面這種快取實作有一個非常大的問題,那就是字典的內容將會無限成長,也就是大量使用者連續瀏覽文章的時候,後台程式將不斷向字典中塞入需要儲存的內容,伺服器記憶體被擠爆,最終導致應用程式崩潰。
上面這個快取實作有一個非常大的問題,那就是字典的內容將會無限成長,也就是大量使用者連續瀏覽文章的時候,後台程式會不斷向字典中塞入需要儲存的內容,伺服器記憶體被擠爆,最終導致應用程式崩潰。
要解決上述這個問題,就需要有一個策略來決定哪些文章應該留在記憶體中,哪些文章應該被刪除掉,這些快取策略其實是一些演算法,它們用於管理快取的訊息,並選擇丟棄哪些項目以為新項目騰出空間。
當然這裡不必去實作管理快取的演算法,只需要使用不同的策略來從快取中移除項,並防止其增長超過其最大大小。五種常見的快取演算法如下所示:
| 快取策略 | 英文名稱 | 淘汰條件 | 何時最有用 |
|---|---|---|---|
| 先進先出演算法(FIFO) | First-In/First-Out | 淘汰最舊的條目 | 較新的條目最有可能被重複使用 |
| 後進先出演算法(LIFO) | Last -In/First-Out | 淘汰最新的條目 | 較舊的條目最有可能被重複使用 |
| 最近最少使用演算法(LRU) | Least Recently Used | 淘汰最近使用最少的條目 | #最近使用的條目最有可能被重複使用 |
| 最近最多使用演算法(MRU) | Most Recently Used | 淘汰最近使用最多的條目 | 最近不用的條目最有可能被重複使用 |
| #最近最少命中演算法(LFU) | Least Frequently Used | #淘汰最不常被造訪的條目 | 命中率很高的條目更有可能被重複使用 |
看了上述五種快取演算法,是不是看到 LRU 和 LFU 的時候有點懵,主要是透過中文對應的解釋很難理解其真實的含義,看看英文的話就不難理解了。 LRU 和LFU 演算法的不同之處在於:
LRU 基於訪問時間的淘汰規則,根據數據的歷史訪問記錄來進行淘汰數據,如果數據最近被訪問過,那麼將來被訪問的幾率也更高;
LFU 基於訪問次數的淘汰規則,根據數據的歷史訪問頻率來淘汰數據,如果數據過去被訪問多次,那麼將來被訪問的頻率也更高;
比如,以十分鐘為一個節點,每分鐘進行一次頁面調度,當所需的頁面走向為2 1 2 4 2 3 4 時,且調頁面4 時會發生缺頁中斷;若按LRU 演算法的話,應換頁面1(十分鐘內頁面1 最久未被使用),但按LFU 演算法的話,應換頁3(十分鐘內頁3 只使用一次)。
二、深入理解LRU 演算法
① 查看LRU 快取的特點
使用LRU 策略實現的快取是按照使用順序進行排序的,每次存取條目時, LRU 演算法就會將其移到快取的頂部。透過這種方式,演算法可以透過查看清單的底部,快速識別出最長時間未使用的條目。
如下所示,使用者從網路上請求第一篇文章的LRU 策略儲存記錄:
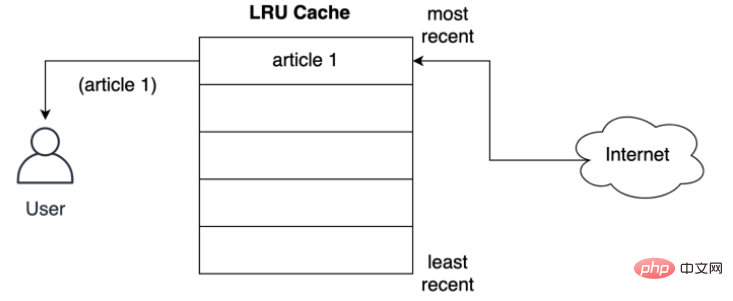
在將文章提供給使用者之前,快取如何將其儲存在最近的槽中?如下所示,用戶要求第二篇文章時發生的情況,第二篇文章儲存到最上層的位置,即第二篇文章採用了最近的位置,將第一篇文章推到列表下方:
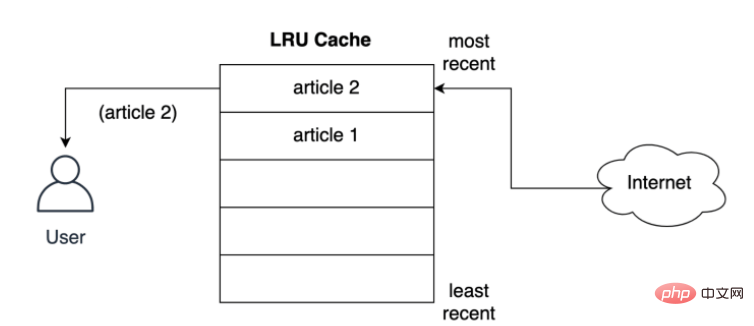
LRU 策略假定使用的物件越新,將來使用該物件的可能性就越大,因此它嘗試將該物件保留在快取中的時間最長,即如果發生條目淘汰的話,會優先淘汰第一篇文件的快取儲存記錄。
② 查看LRU 快取的結構
在Python 中實作LRU 快取的一種方法是使用雙向鍊錶(doubly linked list)和雜湊映射(hash map),雙向鍊錶的頭元素將指向最近使用的條目,而其尾部將指向最近使用最少的條目。 LRU 快取實作邏輯結構如下:
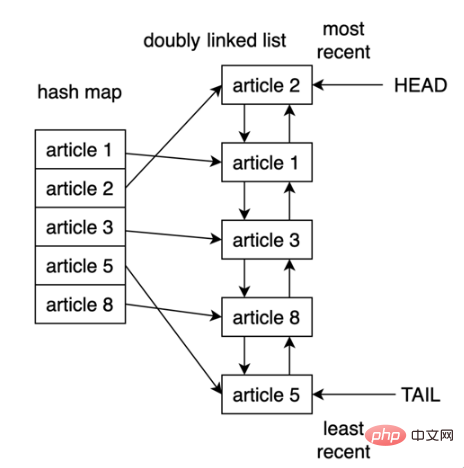
透過使用雜湊映射,可以將每個條目映射到雙鍊錶中的特定位置,從而確保對快取中的每個項的訪問。這個策略非常快,存取最近最少使用的項目和更新快取的複雜度均為 O(1) 操作。
而從 Python3.2 版本開始,Python 新增 @lru_cache 這個裝飾器用於實現 LRU 策略,從此可以使用這個裝飾器來裝飾函數並快取其計算結果。
三、使用lru_cache 裝飾器
① @lru_cache 裝飾器的實作原理
有很多方法可以實作應用程式的快速回應,而使用快取就是一種非常常見的方法。如果能夠正確使用快取的話,可以使回應變得更快且減少運算資源的額外負載。
在Python 中functools 模組自帶了@lru_cache 這個裝飾器來做緩存,其能夠使用最近最少使用(LRU)策略來緩存函數的計算結果,這是一種簡單但功能強大的技術:
實作@lru_cache 裝飾器;
了解LRU 策略的工作運作原理;
- ##使用@ lru_cache 裝飾器來提高效能;
- #擴展@lru_cache 裝飾器的功能並使其在特定時間後過期。
- 0、1、1、2、3、5, 8、13、21、34 ……;
- 2 是上兩項的和->( 1 1);
- 3 是上兩項的和->(1 2);
- 5 是上兩項的和->(2 3)。
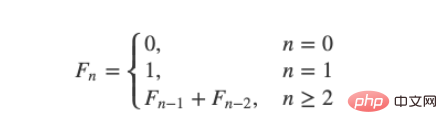
递归的计算简洁并且直观,但是由于存在大量重复计算,实际运行效率很低,并且会占用较多的内存。但是这里并不是需要关注的重点,只是来作为演示示例而已:
# 匿名函数 fib = lambda n: 1 if n <= 1 else fib(n-1) + fib(n-2) # 将时间复杂度降低到线性 fib = lambda n, a=1, b=1: a if n == 0 else fib(n-1, b, a+b) # 保证了匿名函数的匿名性 fib = lambda n, fib: 1 if n <= 1 else fib(n-1, fib) + fib(n-2, fib)
③ 使用 @lru_cache 缓存输出结果
使用 @lru_cache 装饰器来缓存的话,可以将函数调用结果存储在内存中,以便再次请求时直接返回结果:
from functools import lru_cache
@lru_cache
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)④ 限制 @lru_cache 装饰器大小
Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,该属性定义了在缓存开始淘汰旧条目之前的最大条目数,默认情况下,maxsize 设置为 128。
如果将 maxsize 设置为 None 的话,则缓存将无限期增长,并且不会驱逐任何条目。
from functools import lru_cache
@lru_cache(maxsize=16)
def fib(n):
if n==1 or n==2:
return 1
else:
return fib(n-1) + fib(n-2)# 查看缓存列表 >>> print(steps_to.cache_info()) CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
⑤ 使用 @lru_cache 实现 LRU 缓存
就像在前面实现的缓存解决方案一样,@lru_cache 在底层使用一个字典,它将函数的结果缓存在一个键下,该键包含对函数的调用,包括提供的参数。这意味着这些参数必须是可哈希的,才能让 decorator 工作。
示例:玩楼梯:
想象一下,你想通过一次跳上一个、两个或三个楼梯来确定到达楼梯中的一个特定楼梯的所有不同方式,到第四个楼梯有多少条路?所有不同的组合如下所示:
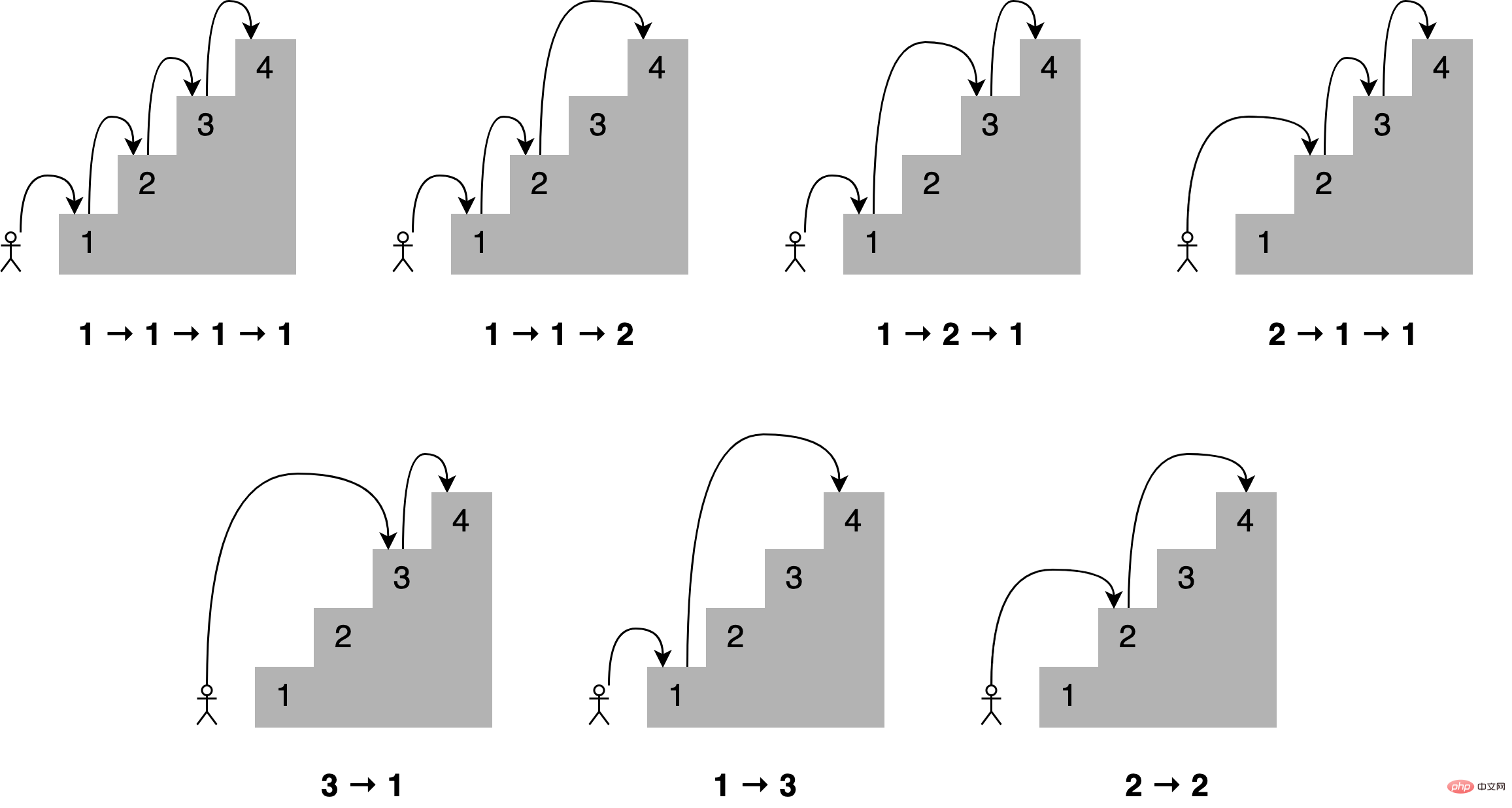
可以这样描述,为了到达当前的楼梯,你可以从下面的一个、两个或三个楼梯跳下去,将能够到达这些点的跳跃组合的数量相加,便能够获得到达当前位置的所有可能方法。
例如到达第四个楼梯的组合数量将等于你到达第三、第二和第一个楼梯的不同方式的总数。如下所示,有七种不同的方法可以到达第四层楼梯:
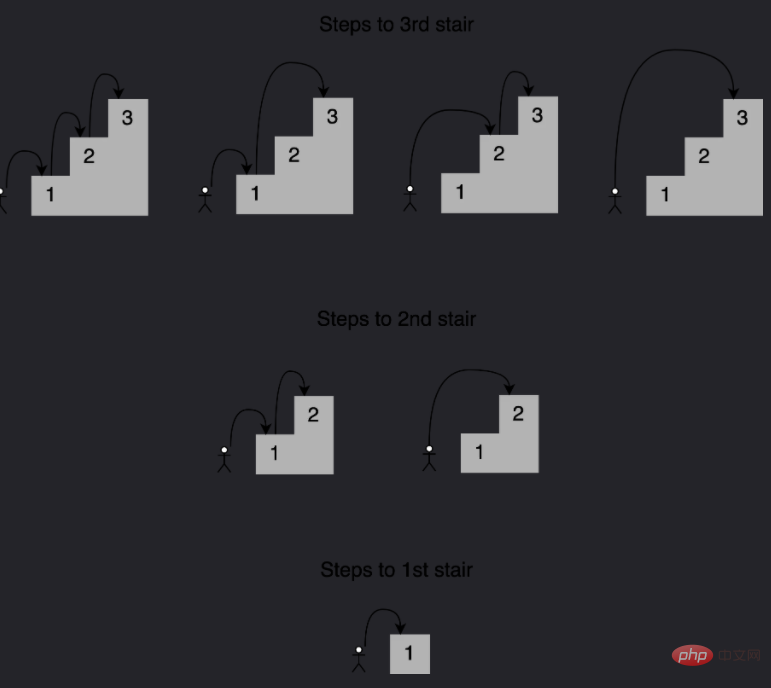
注意给定阶梯的解是如何建立在较小子问题的答案之上的,在这种情况下,为了确定到达第四个楼梯的不同路径,可以将到达第三个楼梯的四种路径、到达第二个楼梯的两种路径以及到达第一个楼梯的一种路径相加。 这种方法称为递归,下面是一个实现这个递归的函数:
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(4))将此代码保存到一个名为 stairs.py 的文件中,并使用以下命令运行它:
$ python stairs.py 7
太棒了,这个代码适用于 4 个楼梯,但是数一下要走多少步才能到达楼梯上更高的地方呢?将第 33 行中的楼梯数更改为 30,并重新运行脚本:
$ python stairs.py 53798080
可以看到结果超过 5300 万个组合,这可真的有点多。
时间代码:
当找到第 30 个楼梯的解决方案时,脚本花了相当多的时间来完成。要获得基线,可以度量代码运行的时间,要做到这一点,可以使用 Python 的 timeit module,在第 33 行之后添加以下代码:
setup_code = "from __main__ import steps_to"
36stmt = "steps_to(30)"
37times = repeat(setup=setup_code, stmt=stmt, repeat=3, number=10)
38print(f"Minimum execution time: {min(times)}")还需要在代码的顶部导入 timeit module:
from timeit import repeat
以下是对这些新增内容的逐行解释:
第 35 行导入 steps_to() 的名称,以便 time.com .repeat() 知道如何调用它;
第 36 行用希望到达的楼梯数(在本例中为 30)准备对函数的调用,这是将要执行和计时的语句;
第 37 行使用设置代码和语句调用 time.repeat(),这将调用该函数 10 次,返回每次执行所需的秒数;
第 38 行标识并打印返回的最短时间。 现在再次运行脚本:
$ python stairs.py 53798080 Minimum execution time: 40.014977024000004
可以看到的秒数取决于特定硬件,在我的系统上,脚本花了 40 秒,这对于 30 级楼梯来说是相当慢的。
使用记忆来改进解决方案:
这种递归实现通过将其分解为相互构建的更小的步骤来解决这个问题,如下所示是一个树,其中每个节点表示对 steps_to() 的特定调用:
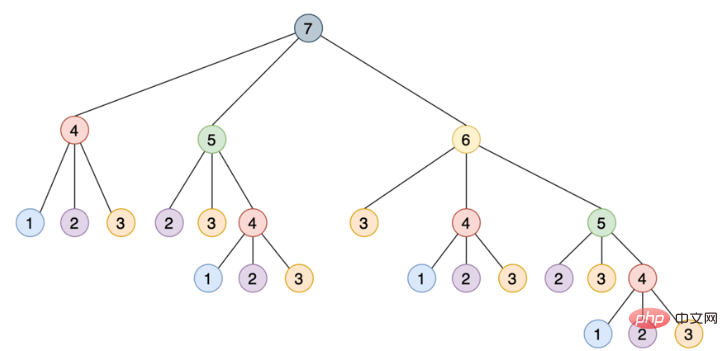
注意需要如何使用相同的参数多次调用 steps_to(),例如 steps_to(5) 计算两次,steps_to(4) 计算四次,steps_to(3) 计算七次,steps_to(2) 计算六次,多次调用同一个函数会增加不必要的计算周期,结果总是相同的。
为了解决这个问题,可以使用一种叫做记忆的技术,这种方法将函数的结果存储在内存中,然后在需要时引用它,从而确保函数不会为相同的输入运行多次,这个场景听起来像是使用 Python 的 @lru_cache 装饰器的绝佳机会。
只要做两个改变,就可以大大提高算法的运行时间:
从 functools module 导入 @lru_cache 装饰器;
使用 @lru_cache 装饰 steps_to()。
下面是两个更新后的脚本顶部的样子:
from functools import lru_cache from timeit import repeat @lru_cache def steps_to(stair): if stair == 1:
运行更新后的脚本产生如下结果:
$ python stairs.py 53798080 Minimum execution time: 7.999999999987184e-07
缓存函数的结果会将运行时从 40 秒降低到 0.0008 毫秒,这是一个了不起的进步。@lru_cache 装饰器存储了每个不同输入的 steps_to() 的结果,每次代码调用带有相同参数的函数时,它都直接从内存中返回正确的结果,而不是重新计算一遍答案,这解释了使用 @lru_cache 时性能的巨大提升。
⑥ 解包 @lru_cache 的功能
有了@lru_cache 装饰器,就可以将每个调用和应答存储在内存中,以便以后再次请求时进行访问,但是在内存耗尽之前,可以节省多少次调用呢?
Python 的 @lru_cache 装饰器提供了一个 maxsize 属性,它定义了在缓存开始清除旧条目之前的最大条目数,缺省情况下,maxsize 设置为 128,如果将 maxsize 设置为 None,那么缓存将无限增长,并且不会驱逐任何条目。如果在内存中存储大量不同的调用,这可能会成为一个问题。
如下是 @lru_cache 使用 maxsize 属性:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:在本例中,将缓存限制为最多 16 个条目,当一个新调用传入时,decorator 的实现将会从现有的 16 个条目中删除最近最少使用的条目,为新条目腾出位置。
要查看添加到代码中的新内容会发生什么,可以使用 @lru_cache 装饰器提供的 cache_info() 来检查命中和未命中的次数以及当前缓存的大小。为了清晰起见,删除乘以函数运行时的代码,以下是修改后的最终脚本:
from functools import lru_cache
from timeit import repeat
@lru_cache(maxsize=16)
def steps_to(stair):
if stair == 1:
# You can reach the first stair with only a single step
# from the floor.
return 1
elif stair == 2:
# You can reach the second stair by jumping from the
# floor with a single two-stair hop or by jumping a single
# stair a couple of times.
return 2
elif stair == 3:
# You can reach the third stair using four possible
# combinations:
# 1. Jumping all the way from the floor
# 2. Jumping two stairs, then one
# 3. Jumping one stair, then two
# 4. Jumping one stair three times
return 4
else:
# You can reach your current stair from three different places:
# 1. From three stairs down
# 2. From two stairs down
# 2. From one stair down
#
# If you add up the number of ways of getting to those
# those three positions, then you should have your solution.
return (
steps_to(stair - 3)
+ steps_to(stair - 2)
+ steps_to(stair - 1)
)
print(steps_to(30))
print(steps_to.cache_info())如果再次调用脚本,可以看到如下结果:
$ python stairs.py 53798080 CacheInfo(hits=52, misses=30, maxsize=16, currsize=16)
可以使用 cache_info() 返回的信息来了解缓存是如何执行的,并对其进行微调,以找到速度和存储之间的适当平衡。下面是 cache_info() 提供的属性的详细说明:
hits=52 是 @lru_cache 直接从内存中返回的调用数,因为它们存在于缓存中;
misses =30 是被计算的不是来自内存的调用数,因为试图找到到达第 30 级楼梯的台阶数,所以每次调用都在第一次调用时错过了缓存是有道理的;
maxsize =16 是用装饰器的 maxsize 属性定义的缓存的大小;
currsize =16 是当前缓存的大小,在本例中它表明缓存已满。
如果需要从缓存中删除所有条目,那么可以使用 @lru_cache 提供的 cache_clear()。
四、添加缓存过期
假设想要开发一个脚本来监视 Real Python 并在任何包含单词 Python 的文章中打印字符数。真正的 Python 提供了一个 Atom feed,因此可以使用 feedparser 库来解析提要,并使用请求库来加载本文的内容。
如下是监控脚本的实现:
import feedparser
import requests
import ssl
import time
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")将此脚本保存到一个名为 monitor.py 的文件中,安装 feedparser 和请求库,然后运行该脚本,它将持续运行,直到在终端窗口中按 Ctrl+C 停止它:
$ pip install feedparser requests $ python monitor.py Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784 Checking feed... Fetching article from server... The Real Python Podcast – Episode #28: Using ... 29520 Fetching article from server... Python Community Interview With David Amos 54256 Fetching article from server... Working With Linked Lists in Python 37099 Fetching article from server... Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... The Real Python Podcast – Episode #27: Prepar... 30784
代码解释:
第 6 行和第 7 行:当 feedparser 试图访问通过 HTTPS 提供的内容时,这是一个解决方案;
第 16 行:monitor() 将无限循环;
第 18 行:使用 feedparser,代码从真正的 Python 加载并解析提要;
第 20 行:循环遍历列表中的前 5 个条目;
第 21 到 31 行:如果单词 python 是标题的一部分,那么代码将连同文章的长度一起打印它;
第 33 行:代码在继续之前休眠了 5 秒钟;
第 35 行:这一行通过将 Real Python 提要的 URL 传递给 monitor() 来启动监视过程。
每当脚本加载一篇文章时,“Fetching article from server…”的消息就会打印到控制台,如果让脚本运行足够长的时间,那么将看到这条消息是如何反复显示的,即使在加载相同的链接时也是如此。
这是一个很好的机会来缓存文章的内容,并避免每五秒钟访问一次网络,可以使用 @lru_cache 装饰器,但是如果文章的内容被更新,会发生什么呢?第一次访问文章时,装饰器将存储文章的内容,并在以后每次返回相同的数据;如果更新了帖子,那么监视器脚本将永远无法实现它,因为它将提取存储在缓存中的旧副本。要解决这个问题,可以将缓存条目设置为过期。
from functools import lru_cache, wraps
from datetime import datetime, timedelta
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
...代码解释:
第 4 行:@timed_lru_cache 装饰器将支持缓存中条目的生命周期(以秒为单位)和缓存的最大大小;
第 6 行:代码用 lru_cache 装饰器包装了装饰函数,这允许使用 lru_cache 已经提供的缓存功能;
第 7 行和第 8 行:这两行用两个表示缓存生命周期和它将过期的实际日期的属性来修饰函数;
第 12 到 14 行:在访问缓存中的条目之前,装饰器检查当前日期是否超过了过期日期,如果是这种情况,那么它将清除缓存并重新计算生存期和过期日期。
请注意,当条目过期时,此装饰器如何清除与该函数关联的整个缓存,生存期适用于整个缓存,而不适用于单个项目,此策略的更复杂实现将根据条目的单个生存期将其逐出。
在程序中,如果想要实现不同缓存策略,可以查看 cachetools 这个库,该库提供了几个集合和修饰符,涵盖了一些最流行的缓存策略。
使用新装饰器缓存文章:
现在可以将新的 @timed_lru_cache 装饰器与监视器脚本一起使用,以防止每次访问时获取文章的内容。为了简单起见,把代码放在一个脚本中,可以得到以下结果:
import feedparser
import requests
import ssl
import time
from functools import lru_cache, wraps
from datetime import datetime, timedelta
if hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context
def timed_lru_cache(seconds: int, maxsize: int = 128):
def wrapper_cache(func):
func = lru_cache(maxsize=maxsize)(func)
func.lifetime = timedelta(seconds=seconds)
func.expiration = datetime.utcnow() + func.lifetime
@wraps(func)
def wrapped_func(*args, **kwargs):
if datetime.utcnow() >= func.expiration:
func.cache_clear()
func.expiration = datetime.utcnow() + func.lifetime
return func(*args, **kwargs)
return wrapped_func
return wrapper_cache
@timed_lru_cache(10)
def get_article_from_server(url):
print("Fetching article from server...")
response = requests.get(url)
return response.text
def monitor(url):
maxlen = 45
while True:
print("\nChecking feed...")
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
if "python" in entry.title.lower():
truncated_title = (
entry.title[:maxlen] + "..."
if len(entry.title) > maxlen
else entry.title
)
print(
"Match found:",
truncated_title,
len(get_article_from_server(entry.link)),
)
time.sleep(5)
monitor("https://realpython.com/atom.xml")请注意第 30 行如何使用 @timed_lru_cache 装饰 get_article_from_server() 并指定 10 秒的有效性。在获取文章后的 10 秒内,任何试图从服务器访问同一篇文章的尝试都将从缓存中返回内容,而不会到达网络。
运行脚本并查看结果:
$ python monitor.py Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37100 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164887 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Match found: Python Community Interview With David Amos 54254 Match found: Working With Linked Lists in Python 37100 Match found: Python Practice Problems: Get Ready for Your ... 164887 Match found: The Real Python Podcast – Episode #27: Prepar... 30783 Checking feed... Fetching article from server... Match found: The Real Python Podcast – Episode #28: Using ... 29521 Fetching article from server... Match found: Python Community Interview With David Amos 54254 Fetching article from server... Match found: Working With Linked Lists in Python 37099 Fetching article from server... Match found: Python Practice Problems: Get Ready for Your ... 164888 Fetching article from server... Match found: The Real Python Podcast – Episode #27: Prepar... 30783
请注意,代码在第一次访问匹配的文章时是如何打印“Fetching article from server…”这条消息的。之后,根据网络速度和计算能力,脚本将从缓存中检索文章一两次,然后再次访问服务器。
该脚本试图每 5 秒访问这些文章,缓存每 10 秒过期一次。对于实际的应用程序来说,这些时间可能太短,因此可以通过调整这些配置来获得显著的改进。
五、@lru_cache 装饰器的官方实现
简单理解,其实就是一个装饰器:
def lru_cache(maxsize=128, typed=False):
if isinstance(maxsize, int):
if maxsize < 0:
maxsize = 0
elif callable(maxsize) and isinstance(typed, bool):
user_function, maxsize = maxsize, 128
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
elif maxsize is not None:
raise TypeError('Expected first argument to be an integer, a callable, or None')
def decorating_function(user_function):
wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo)
return update_wrapper(wrapper, user_function)
return decorating_function_CacheInfo = namedtuple("CacheInfo", ["hits", "misses", "maxsize", "currsize"])
def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo):
sentinel = object() # unique object used to signal cache misses
make_key = _make_key # build a key from the function arguments
PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields
cache = {} # 存储也使用的字典
hits = misses = 0
full = False
cache_get = cache.get
cache_len = cache.__len__
lock = RLock() # 因为双向链表的更新不是线程安全的所以需要加锁
root = [] # 双向链表
root[:] = [root, root, None, None] # 初始化双向链表
if maxsize == 0:
def wrapper(*args, **kwds):
# No caching -- just a statistics update
nonlocal misses
misses += 1
result = user_function(*args, **kwds)
return result
elif maxsize is None:
def wrapper(*args, **kwds):
# Simple caching without ordering or size limit
nonlocal hits, misses
key = make_key(args, kwds, typed)
result = cache_get(key, sentinel)
if result is not sentinel:
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
cache[key] = result
return result
else:
def wrapper(*args, **kwds):
# Size limited caching that tracks accesses by recency
nonlocal root, hits, misses, full
key = make_key(args, kwds, typed)
with lock:
link = cache_get(key)
if link is not None:
# Move the link to the front of the circular queue
link_prev, link_next, _key, result = link
link_prev[NEXT] = link_next
link_next[PREV] = link_prev
last = root[PREV]
last[NEXT] = root[PREV] = link
link[PREV] = last
link[NEXT] = root
hits += 1
return result
misses += 1
result = user_function(*args, **kwds)
with lock:
if key in cache:
pass
elif full:
oldroot = root
oldroot[KEY] = key
oldroot[RESULT] = result
root = oldroot[NEXT]
oldkey = root[KEY]
oldresult = root[RESULT]
root[KEY] = root[RESULT] = None
del cache[oldkey]
cache[key] = oldroot
else:
last = root[PREV]
link = [last, root, key, result]
last[NEXT] = root[PREV] = cache[key] = link
full = (cache_len() >= maxsize)
return result
def cache_info():
"""Report cache statistics"""
with lock:
return _CacheInfo(hits, misses, maxsize, cache_len())
def cache_clear():
"""Clear the cache and cache statistics"""
nonlocal hits, misses, full
with lock:
cache.clear()
root[:] = [root, root, None, None]
hits = misses = 0
full = False
wrapper.cache_info = cache_info
wrapper.cache_clear = cache_clear
return wrapper以上是Python如何使用LRU快取策略進行快取的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
